class="markdown-doc">今晚听同事分享提到这个,简单总结下。
## Unicode字符集
Unicode的出现是因为ASCII等其他编码码不够用了,比如ASCII是英语为母语的人发明的,只要一个字节8位就能够表示26个英文字母了,但是当跨区域进行信息交流的时候,尤其是Internet的出现,除了“A”,“B”,“C",还有“你”,“我”,“他”需要表示,一个字节8位显然不够用,因此Unicode就被发明出来,Unicode的最大码位0x10FFFF,有21位。中文对应的Unicode编码见http://www.chi2ko.com/tool/CJK.htm
## UTF-8字符编码
Unicode只是给这世界上每个字符规定了一个统一的二进制编号,并没有规定程序该如何去存储和解析。
可以说UTF-8是Unicode实现方式之一,它的规则如下:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
Unicode编码(十六进制)
UTF-8 字节流(二进制)
000000 - 00007F
0xxxxxxx
000080 - 0007FF
110xxxxx 10xxxxxx
000800 - 00FFFF
1110xxxx 10xxxxxx 10xxxxxx
010000 - 10FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
可以看到最多一共有21个x,所以刚好能够表示Unicode的最大的码位。
##大端(BE)和小端(LE)
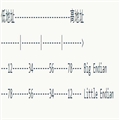
考虑4个字节的16进制表示ox12345678,计算机都是以字节为单位存储数据的,因此内存地址空间从低到高被挖成一个个“坑”,一个萝卜一个坑,那么相邻的萝卜之间自然就有顺序的问题。文字说明太抽象,直接看图理解。

大端跟我们平时的书写习惯一致,比较好理解,记住大端就可以了,我们平时说的网络字节顺序也是指大端,至于小端就让它见鬼去吧。
实在要文字说明理解的话,可以这么来:大端可以认为是“高位在尾端”(大->高),“高位”指的是我们书写时的高位,比如1024,个十百千,1是高位,“尾端”指的是内存空间中低地址一端,所以1存储在低地址空间,只不过计算机是以一个字节为单位的。反之小端就是“低位在尾端”(小->低)了。
## BOM
BOM(Byte Order Mark)是用来区分字节序列和编码方式的(UTF-8,UTF-16,UTF-32)。就是让编辑器或程序读到前面几个字节就知道后面该以哪种编码方式来解析,8/16/32是指以多少位作为编码单位的,依次就是1/2/4个字节,因为UTF-8是以单个字节作为编码单位的所以其实没有必要指定它的字节序列,所以UTF-8有BOM和无BOM的两种。
UTF编码
Byte Order Mark (BOM)
UTF-8 without BOM
无
UTF-8 with BOM
EF BB BF
UTF-16LE
FF FE
UTF-16BE
FE FF
UTF-32LE
FF FE 00 00
UTF-32BE
00 00 FE FF
## 延伸阅读
Unicode字符平面映射:
http://zh.wikipedia.org/wiki/Unicode%E5%AD%97%E7%AC%A6%E5%B9%B3%E9%9D%A2%E6%98%A0%E5%B0%84#.E5.9F.BA.E6.9C.AC.E5.A4.9A.E6.96.87.E7.A7.8D.E5.B9.B3.E9.9D.A2
[1]: http://images.cnitblog.com/blog/288950/201411/192303551093399.png