? ? ? ?Hash是各种程序语言中经常用到的一个“算法”或者说“结构”,按我的理解,hash就是把大量的数据打乱,对每一个数据分配一个唯一的映射值,然后重新储存,对于每一个关键字Value?,都有一个映射值Key对应,既通过唯一的f(key)可以找到value;
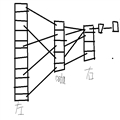
? ? ? ?在每次通过key查找的时候就可以通过常数级时间查到我们所需要的对象,是一个用空间换时间的典型例子,这Hash最主要的部分当然是用一个算法(哈希函数)来分配每一个Value的映射值(就是f(key)),这里有一个例子,假设有一个从1-100岁的人口数据统计表,我们就可以把年龄当做key,hash函数就去key自身,那么当我们要查20岁的有多少人,就可以直接查表第20项,我们也可以把hash函数取key的某个整数的模,同样我们查找的时候根据key和hash算法的逆求出value所在位置;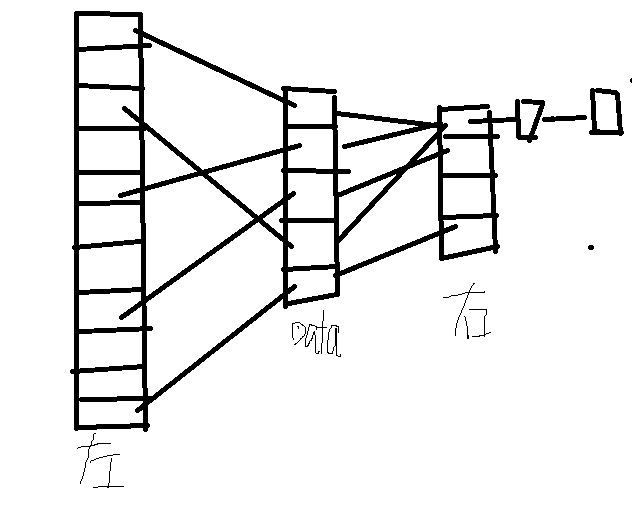
? ? ? ?那么我们就要解决另外一个问题了,就像上面的图片右边,data会有重复的f(key)值,就造成分配冲突,这个时候 我们可以再横向的建立一个链表,把冲突的f(key)放到后面去,就向上面说的;当然,这个方法肯定不是一个好的方法,当冲突的数量达到一定的程度的时候,就完全抹掉了hash的优点,甚至变成了累赘;一个好的hash函数当然是这个好的hash的前提,但是对于现在的TB级大数据,hash肯定会有冲突,那就要rehash;下面是java的HashTable里面的rehash方法
class="java">protected void rehash() {
int oldCapacity = table.length;
//元素
Entry<K,V>[] oldMap = table;
int newCapacity = (oldCapacity << 1) + 1; //新容量=旧容量 * 2 + 1
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<K,V>[] newMap = new Entry[]; //新建一个size = newCapacity 的HashTable
modCount++;//这个先不管它
//重新计算阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
//重新计算hashSeed
boolean rehash = initHashSeedAsNeeded(newCapacity);
table = newMap;
//将原来的元素拷贝到新的HashTable中
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}
可以看到,HashTable里面是把Entry的容量扩大,然后把原来的数据重新copy进去,这个是一个十分耗时间的过程,hashseed是用计算key的hash值,把它和hashcode进行按位异或运算,hashcode这个东东也有的研究,等我深究一下下再写出来跟大家分享一下,暂时可以理解成是物理地址,回过去说hashseed事实上就是用于解决冲突的。
? ? ? ?解决冲突的方法不止一种,对于相对较少的数据可以用hashtable里面的那一种。
?