序)很多时候其实问题很简单,问题在于自己懂得过于肤浅
项目中需要用到一个功能,机器人模拟和人类聊天,玩家说出一句话之后,机器人本能的和他开始聊天,这破B玩意儿我觉得只要有强大的词库和拆分算法,就那么点东西,但是要自己做还真是压力满满的。于是果断的在网上搜索,轻松的找到了这个东西:
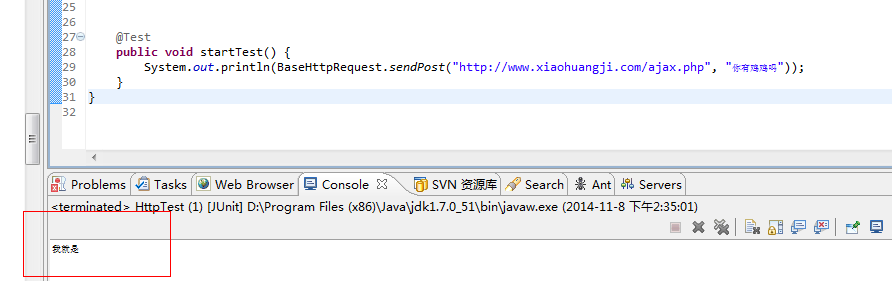
这玩意儿给我的第一感觉就是实在,可以,完全能够满足需求,不过貌似它没有提供接口,这不是事儿,果断的翻网页源码,找到post的地方,是一个ajax的post请求,带了一个参数,很简单,于是果断的来个java模拟HTTP,分分钟搞定,写了个junit测试下:
10分钟就搞定了一个智能聊天机器人,本来以为问题就解决了,于是轻松的部署到jetty去,鄙人对jetty绯闻挺多了,websocket中的EOF曾经就搞了很久,部署上去之后,果断开始使用安卓端测试下,客户端发了一个:你好,另一个客户端收到:骞茶帿瀛?
明显是乱码了,感觉debug一下:
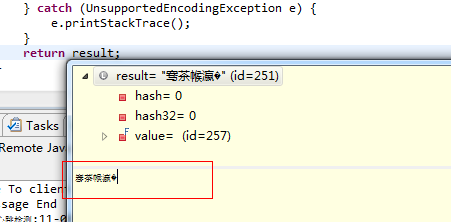
可以看到接受到http的返回值的时候已经乱码了,在此过程中经历过如下步骤:
发出http请求 ---> 第三方接口http返回值 --> 本地jetty容器接受二进制流 --> jetty根据容器编码重新编码二进制数据 --> Java InputStream接受jetty编码之后的流 --> java将其转换成String
于是我们看到了一个String的返回值,而这个返回值乱码,一般在汉字乱码中分为两种情况:
1:骞茶帿瀛? 这样的乱码其实不叫乱码,而是数据不是我们想要的,因为我们要的是A却显示成了B,这样的原因主要是因为编码格式不正确导致
2:????? 全是问号的乱码应该很多人都遇见过,这样的东西应该才是算乱码,为什么会出现?。因为字节内的东西无法用一个汉字展示出来,也就是找不到汉字对应这个内容,于是这样的东西会以?的形式展示出来,官方的称呼就是编码黑洞,对应的二进制数据为63,转换后就是一个?
根据情况来看自己遇到的是第一种,于是有点疑惑,管他的,来个强转:
ChangeCharset changeCharset = new ChangeCharset(); try { result = changeCharset.toUTF_8(URLDecoder.decode(result, "UTF-8")); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return result;
管你什么编码,哥给你来个统一,于是美滋滋的再次打开客户端测试,又出现了另外一种情况:
机器人说:你好爱你哦亲??
妈了个巴子,居然有部分乱码,于是继续测试想找出规律,后来果然发现规律,只要过来的数据是偶数个,则不会乱码,若是奇数个,则最后一个汉字乱码,乱码的形式是固定的?,来了一个?,我靠,今天两种情况都遇到了,本以为很简单的东西居然卡在了编码的地方,苦思冥想,很明显是容器编码问题,很SB的解决方法也很简单,判断下是不是奇偶,不是偶数加个东西就行了。
但是想搞明白为什么是最后一个字乱码,突然想到一个东西,UTF-8中,一个汉字3个字节,GBK中一个汉字2个字节,我好像明白了什么。。
因为jetty容器默认是按照系统编码来决定容器编码,前提是没有自己修改启动编码,而公司里我台PC是windows的,好像默认GBK的,反正我对windows绯闻也挺多的,于是这里有一个问题,比如jetty接受到了一串经过UTF-8编码的汉字:
我很好
jetty收到的最原始的二进制数组是这样的:
[-26, -120, -111, -27, -66, -120, -27, -91, -67]
当然这不是最原始的,最原始的0和1,当然为了好看就算他是最原始的吧,下一步jetty要开始编码了,按照jetty的GBK编码,他按照2个字节一个汉字的格式去编码,于是出现了这样的组合:
[-26, -120] [ -111, -27] [-66, -120] [-27, -91] [-67]
前面每两个字节都能找到对应的汉字,最后jetty发现最后居然只有一个字节,找不到对应的汉字,心里想这SB是哪来的,于是jetty放弃它了,把它赶出去,把63丢过去,于是最后的组合成了:
[-26, -120] [ -111, -27] [-66, -120] [-27, -91] [63]
经过GBK的格式编码,两个字节对应一个汉字,就显示出了这样的东西:
骞茶帿瀛?
会出现5个,因为每2个字节代表一个汉字,最后一个字节是63,对应的符号是?,就出现了上面的东西,于是我对它做了强制的UTF-8编码,导致上面的二进制数组重新组合,经过UTF-8的组合之后,二进制数组成了这样:
[-26, -120, -111] [-27, -66, -120] [-27, -91, 63]
再经过UTF-8显示之后,变成了这样:
我很??
前6个字节能够正常的显示出汉字,因为那就是真正的数据,然而最后3个字节,已经被GBK处理了,替换过了,即使使用UTF-8也无法还原它原来的容貌,于是它就显示成了上面的样子,但是为什么偶数不会出错?
因为偶数能够被GBK正常的解码,也就是如果汉字是偶数,UTF-8和GBK是等同的,但是如果是奇数,则就出问题了,这也是传说中的最后一个汉字乱码的问题,因为最后一个 字节始终是63,要解决这个问题,必须要治标还要治本,项目中必须全程保证编码一致性,因为我这个项目是游戏服务器,走的WebSocket,要是Servlet可以直接在Servlet里面处理或者Filter处理。
不同的编码方式,处理逻辑不一样,很多时候我们强转看似解决了问题,其实只是问题没有暴漏出来,知道其根本,方能运筹帷幄之中,决胜千里之外。
扯点题外话,前几天半夜不知道抽了什么风,将Centos升级到了6.6,结果在6.6下eclipse全部打不开,全是fatal级别的错误,反正不是我等闲人能解决的,那一次更新下载的更新包是1.4GB,明显是系统兼容性的问题,我了个擦,于是想到一代码农不能死于eclipse下,于是折腾下了VIM,弄了几个插件。虽然以前也用VIM,但是没有这次这么正式,弄了下发现其实这玩意儿相当优秀,基本除了eclipse的打断点Debug,其他和他差不多,写C/C++更快,一个\im过去整个文件注释main整体就起来了,相当便捷,另外Linux下的UI也相当不错,特别是DUCK桌面,和Mac基本差不多,甚至你可以用java写出这样的东西:
对于程序猿,Linux是个好东西,有喜欢试水的朋友,可以试试。
附上最近给自己系统加了DUCK美容后的美照:
结语)其实这个问题很简单,只是当时太SB,想想就揪心。。