class="p0">��webmagicʵ�ֵ���������
����֩�����������棩Web?Spider��һ���dz�����ı�����������ǵ�������һ��֩������ÿ���ڵ����һ����վ����ϵÿ���ڵ��֩��˿����������վ�����ӡ����������ԭ����ʵ������������ͨ����ҳ�����ӵ�ַ��Ѱ����ҳ����?��վijһ��ҳ�棨ͨ������ҳ����ʼ����ȡ��ҳ�����ݣ��ҵ�����ҳ�е��������ӵ�ַ��Ȼ��ͨ����Щ���ӵ�ַѰ����һ����ҳ������һֱѭ����ȥ��ֱ���������վ���е���ҳ��ץȡ��Ϊֹ��
���������ʵ�֣�
֮ǰ�ҹ�����һ����������ʵ������������������桪������վ�����ݾ������������������̨��
http://448230305.iteye.com/admin/blogs/2145296
��������ʵ�����Dz�����ֻ�ǰ������������̨���ܶ���������ǻ��и����ӵ�����
1.?��Ҫ�����Ǵ洢�����ݿ⣻
2.?��Ҫ�����Ǵ洢��redis���ļ��
3.?�������ǻ���Ҫ���ǵ�����ʶ���Ѿ���������վ���������ǵĴ洢�豸�г����ظ���
4.?����һЩ��Ҫ��¼����վ��������Ҫ����ʵ��ģ���¼��
5.?ijЩ��վ����ǰ����Ⱦ�ģ���Щ��վ�����ݴ�Դ���в���ֱ�ӿ��������δ�����
?
֪ʶ������
Ҫ�����һ���⣺
����������Ҫ������֪ʶ���˽⣺
Spring
MyBatis
MyBatis-Spring��http://mybatis.github.io/spring/zh/��
?
��Ȼ��ѧϰ���ķ���������������һ��demo��Ȼ�����Ǹ�demo�Լ�ʵ��һ����������Ϊ����ṩһ����ȡ��Ƹ��Ϣ������demo��jobhunter��
https://github.com/webmagic-io/jobhunter
?
�����濴�����demo֮��������Ҫ���ľ����Լ�ȥʵ��һ��demo��
1��Ŀ¼�ṹ��
?
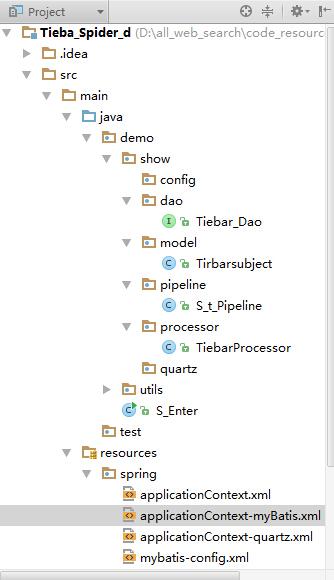
??
2��Resources��
Resources���������ݿ����ӵ������ļ���spring-myBatis�������ļ���
?
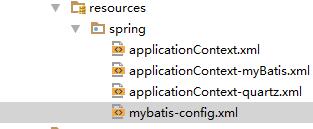
?��Щ�ļ��ܶ࣬�ҾͲ�ȫ������ҿ���~ֻ����ҿ�һ�����ݿ����÷���ģ�
????<bean?id="dataSource"?class="org.apache.commons.dbcp.BasicDataSource"
??????????destroy-method="close">
????????<property?name="driverClassName"?value="com.mysql.jdbc.Driver"?/>
????????<property?name="url"?value="jdbc:mysql://localhost:3306/search_show?characterEncoding=UTF-8"?/>
????????<property?name="username"?value="root"?/>
????????<property?name="password"?value=""?/>
</bean>
url��username��password�ֱ��Ӧ���ݿ�ĵ�ַ���û��������룻
3������jar����
�����������ʹ�õ���idea+maven+gitģʽ���п�����û���ù����ģʽ��ͬѧ�������Բ���
Idea��http://www.jetbrains.com/idea/
Maven��http://my.oschina.net/huangyong/blog/194583
Git��http://my.oschina.net/huangyong/blog/200075
˳��˵һ�£�maven�����û�������ʱ���������ϵͳ�������һ�������ڻ����������ʱ���ʧ���ˡ���ʱ���Ҳ���ԭ����֪���Ŀ������Ը�����Ŷ��
��maven��������Ҫ���õ�jar���У�
????<properties>
????????<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
????????<!--?m2eclipse?wtp?0.12+?enabled?to?configure?contextRoot,?add?by?w.vela?-->
????????<m2eclipse.wtp.contextRoot>/</m2eclipse.wtp.contextRoot>
????????<spring-version>3.1.1.RELEASE</spring-version>
????????<spring-security-version>3.1.0.RELEASE</spring-security-version>
????</properties>
????<dependencies>
????????<dependency>
????????????<groupId>us.codecraft</groupId>
????????????<version>0.5.2</version>
????????????<artifactId>webmagic-core</artifactId>
????????</dependency>
????????<dependency>
????????????<groupId>us.codecraft</groupId>
????????????<version>0.5.2</version>
????????????<artifactId>webmagic-extension</artifactId>
????????</dependency>
????????<dependency>
????????????<groupId>org.springframework</groupId>
????????????<artifactId>spring-jdbc</artifactId>
????????????<version>${spring-version}</version>
????????</dependency>
????????<dependency>
????????????<groupId>org.apache.commons</groupId>
????????????<artifactId>commons-lang3</artifactId>
????????????<version>3.1</version>
????????</dependency>
????????<dependency>
????????????<groupId>javax.servlet</groupId>
????????????<artifactId>servlet-api</artifactId>
????????????<version>2.5</version>
????????</dependency>
????????<dependency>
????????????<groupId>mysql</groupId>
????????????<artifactId>mysql-connector-java</artifactId>
????????????<version>5.1.18</version>
????????</dependency>
????????<dependency>
????????????<groupId>commons-dbcp</groupId>
????????????<artifactId>commons-dbcp</artifactId>
????????????<version>1.3</version>
????????</dependency>
????????<dependency>
????????????<groupId>junit</groupId>
????????????<artifactId>junit</artifactId>
????????????<version>4.7</version>
????????????<scope>test</scope>
????????</dependency>
????????<dependency>
????????????<groupId>org.mybatis</groupId>
????????????<artifactId>mybatis</artifactId>
????????????<version>3.1.1</version>
????????</dependency>
????????<dependency>
????????????<groupId>org.mybatis</groupId>
????????????<artifactId>mybatis-spring</artifactId>
????????????<version>1.1.1</version>
????????</dependency>
????????<dependency>
????????????<groupId>commons-logging</groupId>
????????????<artifactId>commons-logging</artifactId>
????????????<version>1.1.1</version>
????????</dependency>
????????<dependency>
????????????<groupId>org.springframework</groupId>
????????????<artifactId>spring-test</artifactId>
????????????<version>${spring-version}</version>
????????????<scope>test</scope>
????????</dependency>
4��Daoʵ�֣�
Dao�����ݿ⽻�����ӿ���sql����д�����棬���ǿ�һ��Tiebar_Dao,�������Ŷ�Tiebar����������ɾ�IJ飻
package?demo.show.dao;
?
import?demo.show.model.Tirbarsubject;
import?org.apache.ibatis.annotations.Insert;
import?org.apache.ibatis.annotations.Select;
?
import?java.util.List;
?
public?interface?Tiebar_Dao?{
????@Insert("insert?into?t_po_tieba?(`TITLE`,`ADDRESS`,`DATETIME`,`CONTENT`,`HTS`,`USER`,`TB_TYPE`)?values?(#{title},#{address},#{dateTime},#{content},#{hts},#{user},#{tb_type})")
????public?int?add(Tirbarsubject?tir);
?
????@Select("select?PK_TIEBA_ID,ADDRESS?from?t_po_tieba")
????public?List<Tirbarsubject>?get_resources();
?
????@Select("select?ADDRESS?from?t_po_tieba?where?ADDRESS=#{address}")
????public?Tirbarsubject?get_resource(String?Address);
}
������Ҫʹ����Щ����ʱ��ֱ�ӵ�����Щ�����Ϳ��ԣ������ǿ�����sql���ģ�
5��Model��
ϸ�ĵ����ѿ��ܻ�ע���Tirbarsubject�����Ƕ�����Model�ļ�������࣬���������������ݿ�һ������model��
package?demo.show.model;
?
import?us.codecraft.webmagic.Page;
import?us.codecraft.webmagic.model.AfterExtractor;
import?us.codecraft.webmagic.model.annotation.Formatter;
?
import?java.io.Serializable;
import?java.util.Date;
?
/**
?*?Created?by?qxy?on?2014-10-24.
?*/
public?class?Tirbarsubject?implements?AfterExtractor,Serializable?{
?
????private?int?id;
?
????private?String?title;
?
????private?String?content;
?
????@Formatter("yyyy-MM-dd?HH:mm")
????private?Date?dateTime;
?
????private?String?address;
?
????private?int?hts;
?
????private?String?user;
?
????private?String?tb_type;
?
????public?String?toString()?{
????????return?"TiebaSubject{"?+
????????????????"id="?+?id?+
????????????????",?Title="?+?title?+
????????????????",?DateTime="?+?dateTime?+
????????????????",?Address='"?+?address?+?'\''?+
????????????????",?Content='"?+?content?+?'\''?+
????????????????",?Hts='"+hts+'\''+
????????????????",?User='"+user+'\''+
????????????????'}';
????}
?
????public?int?getId()?{
????????return?id;
????}
?
????public?void?setId(int?id)?{
????????this.id?=?id;
????}
?
????public?String?getTitle()?{
????????return?title;
????}
��������������������
�����������������������м��get��set�����ҾͲ�д�˹���ƪ�����ޣ�
????public?void?setTb_type(String?tb_type)?{
????????this.tb_type?=?tb_type;
????}
?
????@Override
????public?void?afterProcess(Page?page)?{
????}
}
�������ǿ�����дtoString�������������д����������ǵ�ַ��
6��Process��
ҳ��������ֲ������ǽ���Ҫ�����ص㣬��������������һ�£�
1������ҳ��ʱ���������ݷ�Ϊ�����֣�
������Ҫ��������+������Ҫ������ҳ�棻������Ҫ������ҳ�������������Ҫ�������ӣ�����Ҳ�п��ܴ���������Ҫ��������������������Ҫ������ҳ���Ӵ��ڲ�ͬ��ҳ�棨��������ҳ�棩
��������һ���ģ�һ������£�����Ҫ��������ҳ��ĵ�ַ��������ͬ���ɵģ���ץȡ����ʱ�����ǿ���ʹ��Xpath������λ�ý��ж�λ�����˵�һЩ�����ṹ���Ƶ��Ƿ�����ҳ��ͬλ�õ����ӣ�����ʹ����������ʽ��ȡ���ɣ���ҳ���м���һ��if�жϣ����������������ץȡ�����У�
?if?(page.getUrl().regex(URL_PAGE).match()){
????????????System.out.println(page.getUrl().toString());
?
????????????LB?=?page.getHtml().xpath("//div[@id='frs_list_pager']/").links().regex(URL_PAGE).all();
????????????for(int?i=0;i<LB.size();i++){
????????????????LB.set(i,"http://tieba.baidu.com"+LB.get(i));
????????????}
????????????page.addTargetRequests(LB);
????????????NR?=?page.getHtml().links().regex(URL_CON).all();
????????????page.addTargetRequests(NR);
????????}
�������ǽ�ץȡ��ҳ��������ǵ����ݿ��
������ץȡ��
?else?{
?
????????????HT?=?page.getHtml().xpath("//li[@class='l_pager?pager_theme_5?pb_list_pager']/").regex(URL_HUITIE).all();
????????????for(int?i=0;i<HT.size();i++){
????????????????HT.set(i,"http://tieba.baidu.com"+HT.get(i));
????????????}
????????????page.addTargetRequests(HT);
????????????//����ҳ��
????????????List<String>?content_ht?=?new?ArrayList<String>();
????????????List<String>?user_ht?=?new?ArrayList<String>();
????????????List<String>?date_ht?=?new?ArrayList<String>();
????????????List<String>?lc?=?new?ArrayList<String>();
????????????List<String>?hufu_l?=?new?ArrayList<String>();
????????????String?address_ht;
????????????String?address_zt=null;
????????????List<Huitiesubject>?huitiesubjects_l?=?new?ArrayList<Huitiesubject>();
????????????//��������
????????????String?tb_type=page.getHtml().xpath("//*[@id=\"wd1\"]").regex("value=\"(.+?)\"").regex("[^value=\"].+[^\"]").toString();
????????????String?Title?=?page.getHtml().xpath("//div[@class='core_title?core_title_theme_bright']/h1/text()").toString();
????????????String?Address?=?page.getUrl().toString();
????????????String?str_date?=?page.getHtml().xpath("//div[@id='j_p_postlist']/").regex(XEGEX_TIME).toString();
????????????String?Content?=?page.getHtml().xpath("//div[@id='j_p_postlist']/div[@class='l_post?l_post_bright?noborder']/div[@class='d_post_content_main?d_post_content_firstfloor']/div[1]/cc/div/text()").toString();
????????????String?User?=?page.getHtml().xpath("//div[@id='j_p_postlist']/div[@class='l_post?l_post_bright?noborder']/div[@class='d_author']/ul/li[3]/a/text()").toString();
????????????String?Hts?=?page.getHtml().xpath("//*[@id='thread_theme_5']/div[1]/ul/li[2]/span[1]/text()").toString();
??????//��������
????????????content_ht?=?page.getHtml().xpath("//div[@id='j_p_postlist']//div[3]/div[1]/cc/div/text()").all();
????????????user_ht?=?page.getHtml().xpath("//*[@id=\"j_p_postlist\"]/div/div[2]/ul/li[3]/a/text()").all();
????????????date_ht?=?page.getHtml().xpath("//div[@id='j_p_postlist']/").regex(XEGEX_TIME).all();
????????????lc?=?page.getHtml().xpath("//div[@id='j_p_postlist']/").regex("(post_no":\\d+)").regex("\\d+").all();
????????????address_ht?=?Address;
????????????String?zhengz=?"(.+/\\d*)";
????????????Pattern?p?=?Pattern.compile(zhengz);
????????????Matcher?m=p.matcher(Address);
���ţ����ǽ������������ݿ⣺
??//��������
????????????tirbarsubject.setAddress(Address);
????????????tirbarsubject.setTitle(Title);
????????????tirbarsubject.setDateTime(Data_StrtoDate.ToYMDHM(str_date));
????????????tirbarsubject.setContent(Content);
????????????tirbarsubject.setUser(User);
????????????tirbarsubject.setHts(Integer.parseInt(Hts));
????????????tirbarsubject.setTb_type(tb_type);
????????//��������
????????????for?(int?i=0;i<user_ht.size();i++){
????????????????huitiesubject.setUser(user_ht.get(i));
????????????????huitiesubject.setContent(content_ht.get(i));
????????????????huitiesubject.setDateTime(Data_StrtoDate.ToYMDHM(date_ht.get(i)));
????????????????huitiesubject.setZt_address(address_zt);
????????????????huitiesubject.setAddress(address_ht);
????????????????huitiesubject.setLc(Integer.parseInt(lc.get(i)));
????????????????huitiesubjects_l.add(huitiesubject);
????????????}
?
��������Ķ���ͻ����Ķ������page�
???????????page.putField("huifu_l",?huitiesubjects_l);
???????????page.putField("tir",tirbarsubject);
7��Pipeline��
Pipeline�ǽ����ǽ������������ݴ浽���ݿ�������һ������������Ƚ��٣�Ҳ�Ƚ����������Ǿ�ֱ���ϴ���ɣ�
package?demo.show.pipeline;
import?demo.show.dao.Huitie_Dao;
import?demo.show.dao.Tiebar_Dao;
import?demo.show.model.Huitiesubject;
import?demo.show.model.Tirbarsubject;
import?org.springframework.stereotype.Repository;
import?us.codecraft.webmagic.ResultItems;
import?us.codecraft.webmagic.Task;
import?us.codecraft.webmagic.pipeline.Pipeline;
import?javax.annotation.Resource;
import?java.util.List;
@Repository("S_t_Pipeline")
public?class?S_t_Pipeline?implements?Pipeline?{
????@Resource
????private?Tiebar_Dao?tiebar_dao;
????@Resource
????private?Huitie_Dao?huitiedao;
????@Override
????public?void?process(ResultItems?resultItems,?Task?task)?{
????????Tirbarsubject?ts=resultItems.get("tir");
????????List<Huitiesubject>?ht_l?=?resultItems.get("huifu_l");
????????Tirbarsubject?Address?=?tiebar_dao.get_resource(ts.getAddress());
????????if(ts!=null&&Address==null&&ts.getUser()!=null)?{
????????????System.out.print("���⣺"+ts.getTb_type()+"\n");
????????????System.out.println("��������?:"?+?tiebar_dao.add(ts));
????????}else{
????????????System.out.println("ts?is?null");
????????}
????????for?(int?i=0;i<ht_l.size();i++){
????????????if?(ht_l!=null&&huitiedao.get_resource_addr(ht_l.get(i).getContent())==null){
//????????????????System.out.print("������ַ��"+ht_l.get(i).getAddress()+"\n");
????????????????System.out.println("�������?:"?+?huitiedao.add(ht_l.get(i)));
????????????}
????????????else?{
????????????????System.out.println("huifu?is?null");
????????????}
????????}
?
????}
}
8����������
package?demo;
import?demo.show.dao.Tiebar_Dao;
import?demo.show.processor.TiebarProcessor;
import?org.springframework.beans.factory.annotation.Autowired;
import?org.springframework.beans.factory.annotation.Qualifier;
import?org.springframework.context.ApplicationContext;
import?org.springframework.context.support.ClassPathXmlApplicationContext;
import?org.springframework.stereotype.Controller;
import?us.codecraft.webmagic.Spider;
import?us.codecraft.webmagic.pipeline.Pipeline;
import?javax.annotation.Resource;
@Controller
public?class?S_Enter{
?
????@Qualifier("S_t_Pipeline")
????@Autowired(required?=?true)
????private?Pipeline?S_t_Pipeline;
?
????@Resource
????private?Tiebar_Dao?tiebar_dao;
?
????private?String[]?url_l?=?new?String[3];
?
????public?String[]?getUrl_l()?{
????????return?url_l;
????}
?
????public?void?setUrl_l(String[]?url_l)?{
????????this.url_l?=?url_l;
????}
?
????public?void?crawl(){
????????Spider.create(new?TiebarProcessor()).addUrl(url_l).addPipeline(S_t_Pipeline).thread(5).run();
????}
?
????public?static?void?main(String[]?args)?{
????????String[]?url_l?=?new?String[3];
????????url_l[0]="http://tieba.baidu.com/f?kw=���ϴ�ѧ&pn=0";
????????url_l[1]="http://tieba.baidu.com/f?kw=�Ž���̷&pn=0";
????????url_l[2]="http://tieba.baidu.com/f?kw=���ߴ��¼�&pn=0";
?
?
????????ApplicationContext?applicationContext?=?new?ClassPathXmlApplicationContext("classpath:/spring/applicationContext*.xml");
????????S_Enter?s_enter?=?applicationContext.getBean(S_Enter.class);
????????s_enter.setUrl_l(url_l);
????????s_enter.crawl();
????}
}
?
��������ʹ��webmagic���ʵ�ֵ�һ�����ٶ����ɵ����棬��Ȼ�������ʵ�ֵ�ֻ�Ƕ�html�Ľ�����������Щʹ��js��Ⱦ����ҳ��ʱ��û���漰����Щ��ҳһ�������ַ�����һ����ʹ�������ģ�����������潫��Ⱦ�õ�ҳ����������������ʹ�ùȸ���������е����Ԫ�ع���ȥ�鿴Ҫ��������Դ����Ҳ�DZȽ��鷳�ģ���������Ҳ��һ���dz�����������������Ŷ~~
?
<!--EndFragment-->