1.关于PDF文件
PDF(Portable Document Format的简称,意为“便携式文件格式”)是由Adobe systems.html" target="_blank">Systems在1993年用于文件交换所发展出的文件格式。它的优点在于跨平台、能保留文件原有格式(Layout)、开放标准,能自由授权(Royalty-free)自由开发PDF兼容软件。(PDF - 维基百科)
2.关于解析PDF
就像大神灵感之源的博文关于PDF的代码,真是多得不得了。。。,由于现在实习公司需要从大量文档中提取金融数据.对于网页解析我们有强大的HtmlAgilityPack和ScrapySharp等.对于office家族里excel、word等 直接用.net里类库就行了。唯独对处理PDF没有一个统一方案。当然,我也没有把全部pdf工具研究一遍,感觉大多数工具对于解析pdf功能确实不是很完美。(可能我的见识短浅,只不过还没遇到像解析网页那样解析pdf的工具),现在公司有个系统中有个一个关于pdf数据解析模块。这个模块也是先将PDF转换Html格式文件,然后解析html文件。解析标记语言html已经有很多完美办法,但是问题是由于PDF文件特点,解析PDF本来就是无法保证正确性的事情,而现在却要解析转换后的HTML岂不是更加没有保证了。经过询问得知这个方法在解析PDF中表现确实不是很好。
3.我的方案
公司里需要解析PDF种类和数量有很多,对于Analyst来说每天从大量PDF中手动提取信息是无比痛苦的事情,也是对眼睛和身心巨大考验。对于每种PDF解析策略当然也是不一样的。我打算根据每种不同PDF文件分别介绍下我的处理方案。我的方案是基于PDFNet.dll封装了一个针对公司业务的解析方案。当然了这个DLL并不是开源的,但是在Debug版本中没问题了,一次意外的忘记导入license在内部发布了release产品中只有一台电脑出现无法使用问题。当然,公司也不会在乎这点小钱,我们是有license的。废话不多说,也希望园子里的大神们能给小码农点建议或者能提出更好的方案来!
4.分类介绍
根据不同需求我打算分成系列来介绍这个PDF解析方案。
1.PDF中文本字符串格式中关键值信息抓取(已完成)
简介:这种解析比较传统最简单主要熟练使用Regular Expression做语义识别和验证.
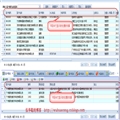
2.PDF类似表格形式关键值数据抓取。(已完成)
简介:这种格式需要用的封装数据结构PdfString类和PdfAnalyzer类,根据给定关键词在指定范围提取数据
3.需要PDF中大量数据转换到Excel中去 (已完成)
简介:基与2的延伸,加入一个自动模糊匹配到行和列边界范围,根据位置坐标排序提取正确数据信息。
4.PDF中数据保存图片格式(未完成)
想法:这种PDF文件我目前还没好的处理办法,应该需要用到图像识别方面的算法。