上一篇介绍了POI组件操作Excel时如何对单元格和行进行设置,合并单元格等操作,最后给出一个综合实例,就是制作复杂报表,原理就是涉及合并行和列的计算。
本篇就来详细分析一下复杂报表的分析与设计问题,并用POI通过程序来生成Excel报表。首先说一点文档相关内容。使用POI组件可以生成
Office文档,而Office文档也有一些属性,比如作者,分类,公司等信息。我们若通过程序生成时,这一步就直接略过了,但有时我们会需要这些信息,要写入一些文档信息,那么该如何实现呢?
我们分2003和2007两个
版本说明,因为操作是不太一样的。看下面的代码:
// 设置核心属性
POIXMLProperties.CoreProperties props = workbook2007.getProperties()
.getCoreProperties();
props.setCreator("Nanlei");
props.setCategory("POI程序测试");
props.setTitle("学生信息表");
// 设置扩展属性
POIXMLProperties.ExtendedProperties extProps = workbook2007
.getProperties().getExtendedProperties();
// 设置自定义属性
POIXMLProperties.CustomProperties customProps = workbook2007
.getProperties().getCustomProperties();
生成2007的Excel时,只需上述步骤便可加入我们需要的属性了,具体的属性含义可以参考
官方文档,这里仅仅添加作者,分类和标题,生成Excel文档后,我们可以查看到入校内容:
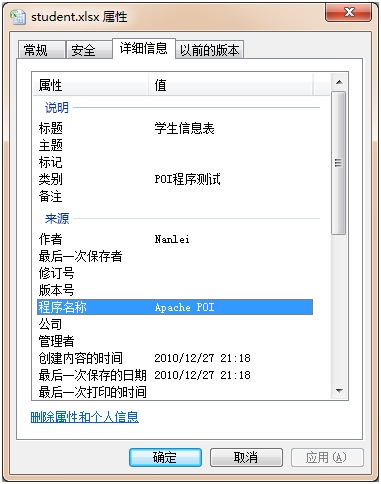
那么这里就是我们设置的一些信息了。而对于2003,则需要如下的步骤:
// 创建工作簿对象
HSSFWorkbook workbook2003 = new HSSFWorkbook();
workbook2003.createInformationProperties();
SummaryInformation si = workbook2003.getSummaryInformation();
si.setAuthor("Nanlei");
si.setTitle("学生信息表");
si.setComments("POI程序测试");
DocumentSummaryInformation dsi = workbook2003
.getDocumentSummaryInformation();
dsi.setCompany("Pioneer");
要注意的是第二行,必须执行createInformationProperties()方法,之后才可以设置属性,这和2007的做法是不同的。这里只是给出示例,就不深入讨论每个设置项了。
回头来看报表。
中国式的复杂报表基本上是合计,合计再合计,就是数值分析到一个阶段后出一次合计,这个阶段可以按照业务的不同元素来划分。本例是根据经销商,省份最终到达事业部。那么设计数据库时就要唯一区分开这些元素,根据这些标识来实现划分,合并等,首先来准备一些数据。
static {
cruiseServiceLocationList = new ArrayList<CruiseServiceLocation>();
csl[0] = new CruiseServiceLocation("T001", "北京市", "北京总部", "bj", "清华大学",
20);
csl[1] = new CruiseServiceLocation("T001", "北京市", "北京总部", "bj", "北京大学",
30);
csl[2] = new CruiseServiceLocation("T001", "北京市", "海淀经销商", "bjhd",
"西直门", 15);
csl[3] = new CruiseServiceLocation("T001", "北京市", "海淀经销商", "bjhd",
"首都机场", 50);
csl[7] = new CruiseServiceLocation("T001", "辽宁省", "大连经销商", "lndl",
"河口软件园", 15);
csl[8] = new CruiseServiceLocation("T001", "辽宁省", "大连经销商", "lndl",
"七贤岭腾飞软件园", 13);
csl[9] = new CruiseServiceLocation("T001", "辽宁省", "大连经销商", "lndl",
"高新园区信达街", 11);
csl[19] = new CruiseServiceLocation("T003", "河北省", "石家庄经销商", "hbsjz",
"火车站", 4);
csl[20] = new CruiseServiceLocation("", "", "", "", "", 0);// 合并算法捕捉最后一行有问题,增补一行无效数据,计算时去除
cruiseServiceLocationList.addAll(Arrays.asList(csl));
}
(具体数据请参考源码,附件中下载)
注意在最后增补一条无效数据,因为算法的
限制,读取最后一行比较时可能会将其略过,所以这样保证所有数据都能被正常读出。这个数据结构根据事业部代号,省份和经销商名称来区分各个元素。
算法就是根据标识位的不同来区分是否该进行特殊处理了,这之前数据要排好顺序,就可以分门别类进行了,来看一下合计算法:
// 合计量的计算
CruiseServiceLocation cslTotal = null;
List<CruiseServiceLocation> cslList = new ArrayList<CruiseServiceLocation>();
// 合并计算控制
double totalDealer = 0;
double totalProvince = 0;
double totalDivision = 0;
int locationNum = 0;
// 循环遍历List
for (int i = 0; i < cruiseServiceLocationList.size(); i++) {
cslList.add(cruiseServiceLocationList.get(i));
// 是否是最后一条记录的开关
boolean last = (i == cruiseServiceLocationList.size() - 1);
// 取出相邻的两条记录进行比较
CruiseServiceLocation csl1 = null;
CruiseServiceLocation csl2 = null;
if (!last) {
csl1 = cruiseServiceLocationList.get(i);
csl2 = cruiseServiceLocationList.get(i + 1);
} else {
// 防止最后一条记录无法加入集合
csl1 = cruiseServiceLocationList.get(i);
if (cruiseServiceLocationList.size() != 1)
csl2 = cruiseServiceLocationList.get(i - 1);
else
csl2 = cruiseServiceLocationList.get(i);
}
// 开始处理
if (csl1.getDealerName().equals(csl2.getDealerName())) {
locationNum++;
totalDealer += csl1.getMiles();
} else {
locationNum++;
totalDealer += csl1.getMiles();
cslTotal = new CruiseServiceLocation();
cslTotal.setTotalDealer(totalDealer);
cslTotal.setLocationNum(locationNum);
cslList.add(cslTotal);
totalDealer = 0;
locationNum = 0;
}
if (csl1.getProvince().equals(csl2.getProvince())) {
totalProvince += csl1.getMiles();
} else {
totalProvince += csl1.getMiles();
cslTotal = new CruiseServiceLocation();
cslTotal.setTotalProvince(totalProvince);
cslList.add(cslTotal);
totalProvince = 0;
}
if (csl1.getDivision().equals(csl2.getDivision())) {
totalDivision += csl1.getMiles();
} else {
totalDivision += csl1.getMiles();
cslTotal = new CruiseServiceLocation();
cslTotal.setTotalDivision(totalDivision);
cslList.add(cslTotal);
totalDivision = 0;
}
}
其中Bean的设计如下:
package org.ourpioneer.excel.bean;
/**
* 巡航服务地点bean
*
* @author Nanlei
*
*/
public class CruiseServiceLocation {
private String division;// 事业部
private String province;// 省份
private String dealerName;// 经销商名称
private String dealerCode;// 经销商代码
private String location;// 巡航服务地点
private double miles;// 巡航服务里程
private int locationNum;// 地点条数
private double totalDealer;// 经销商合计
private double totalProvince;// 省份合计
private double totalDivision;// 事业部合计
public CruiseServiceLocation() {
super();
}
public CruiseServiceLocation(String division, String province,
String dealerName, String dealerCode, String location, double miles) {
super();
this.division = division;
this.province = province;
this.dealerName = dealerName;
this.dealerCode = dealerCode;
this.location = location;
this.miles = miles;
}
// 省略getter和setter方法
}
下面来分析一下这个算法,思路很简单,就是逐条记录进行比较,
发现不同后立即处理,按照从小到大的顺序,一次处理经销商,省份和事业部,取出两条相邻元素之后,首先比较的是经销商是否一致,如果一致,经销商数量加1,里程累加,不一致时,这两个量也要相应计算并放入新的对象中,加入list里,这样一个合计行就加好了,后面的省份和事业部处理也是这个思路。循环完成,我们就得到了按顺序排好的最终列表,剩下的就是遍历这个列表来生成表格了。
要注意我们之前填补了一条无效记录,那么在合并的时候也会多处三行合计,要把这四项排除在外,不能忘记了。
计算合并行是需要一些辅助变量,比如:
// 省份合计和事业部合计时跨行的计算数据
int comboProvince = 0;
int comboDivision = 0;
List<Integer> indexComboProvice = new ArrayList<Integer>();
List<Integer> indexComboDivision = new ArrayList<Integer>();
它们是用来计算合并数量的,最后用在跨行数量上,因为每出一条合计,整体跨行数就要增加,那么需要将这些数据记录到List中,方便处理。我们就引入了这些辅助变量。
先来看经销商合并算法:
if (csl.getTotalDealer() != 0) {
row.createCell(0).setCellStyle(style);
row.createCell(1).setCellStyle(style);
XSSFCell t_dealer = row.createCell(2);
t_dealer.setCellValue("经销商合计");
t_dealer.setCellStyle(biStyle);
sheet.addMergedRegion(new CellRangeAddress(i + 1, i + 1, 2, 4));
XSSFCell t_dealer_value = row.createCell(5);
t_dealer_value.setCellValue(csl.getTotalDealer());
t_dealer_value.setCellStyle(biStyle);
sheet.addMergedRegion(new CellRangeAddress(i
- csl.getLocationNum() + 1, i, 2, 2));
sheet.addMergedRegion(new CellRangeAddress(i
- csl.getLocationNum() + 1, i, 3, 3));
}
这个就很简单了,因为不涉及到跨行,只是跨列而已,这都是预先已经设定好的,不难。而省份和经销商的跨行计算就略微复杂:
if (csl.getTotalProvince() != 0) {
XSSFCell t_province = row.createCell(1);
row.createCell(0).setCellStyle(style);
row.createCell(3).setCellStyle(style);
row.createCell(4).setCellStyle(style);
t_province.setCellValue("省份合计");
t_province.setCellStyle(biStyle);
sheet.addMergedRegion(new CellRangeAddress(i + 1, i + 1, 1, 4));
XSSFCell t_province_value = row.createCell(5);
t_province_value.setCellValue(csl.getTotalProvince());
t_province_value.setCellStyle(biStyle);
indexComboProvice.add(i);
// 合并行
if (comboProvince == 0) {
sheet.addMergedRegion(new CellRangeAddress(1, i, 1, 1));
} else if (comboProvince == 1) {
sheet.addMergedRegion(new CellRangeAddress(
indexComboProvice.get(comboProvince - 1)
+ comboProvince + 1, i, 1, 1));
} else {
sheet.addMergedRegion(new CellRangeAddress(
indexComboProvice.get(comboProvince - 1)
+ comboProvince, i, 1, 1));
}
comboProvince++;
}
这里为了将所有单元格都加入样式,所以没有数据填充的单元格仅做样式处理即可。合并行的时
候要看这是第几次合并,因为算法不同。第一次时比较简单,只需数出有第一个合计中有多少经销商即可。而后续的就需要记录上次合并出现的位置,然后再加上第二个经销商的数量,之后进行合并。那么事业部的算法也是如此。
if (csl.getTotalDivision() != 0) {
XSSFCell t_division = row.createCell(0);
row.createCell(1).setCellStyle(style);
row.createCell(2).setCellStyle(style);
row.createCell(3).setCellStyle(style);
row.createCell(4).setCellStyle(style);
t_division.setCellValue("事业部合计");
t_division.setCellStyle(biStyle);
sheet.addMergedRegion(new CellRangeAddress(i + 1, i + 1, 0, 4));
XSSFCell t_division_value = row.createCell(5);
t_division_value.setCellValue(csl.getTotalDivision());
t_division_value.setCellStyle(biStyle);
indexComboDivision.add(i);
// 合并行
if (comboDivision == 0) {
sheet.addMergedRegion(new CellRangeAddress(1, i, 0, 0));
} else if (comboDivision == 1) {
sheet.addMergedRegion(new CellRangeAddress(
indexComboDivision.get(comboDivision - 1)
+ comboDivision + 1, i, 0, 0));
} else {
sheet.addMergedRegion(new CellRangeAddress(
indexComboDivision.get(comboDivision - 1)
+ comboDivision, i, 0, 0));
}
comboDivision++;
}
最
后生成文件,就得到了我们要的报表了。

综合实例就介绍完了,下一篇将
结合Spring MVC来说明在Web应用程序中如何生成Excel文件并进行下载操作。





