class="author">为何要翻译
一来是为了感受国外优秀技术社区知名博主的高质量文章,二来是为了复习对.NET技术的基础拾遗达到温故知新的效果,最后也是为了锻炼一下自己的英文读写能力。因为是首次翻译英文文章(哎,原谅我这个菜比,弱爆了!),所以肯定会有很多问题(有些语句理解不透彻,翻译出来也不通顺,还请不吝赐教),也请各位园友多多指正,谢谢!
关于原文作者

原文作者:
Shivprasad koirala
原文地址:http://www.code
project.com/Articles/76153/Six-important-NET-concepts-Stack-heap-value-types
内容导读
- 概述
- 当你声明一个变量背后发生了什么?
- 堆和栈
- 值类型和引用类型
- 哪些是值类型,哪些是引用类型?
- 装箱和拆箱
- 装箱和拆箱的性能问题
一、概述
本文会阐述六个重要的概念:堆、栈、值类型、引用类型、装箱和拆箱。本文首先会通过阐述当你定义一个变量之后系统内部发生的改变开始讲解,然后将关注点转移到存储双雄:堆和栈。之后,我们会探讨一下值类型和引用类型,并对有关于这两种类型的重要基础内容做一个讲解。
本文会通过一个简单的代码来展示在装箱和拆箱过程中所带来的性能上的影响,请各位仔细阅读。

二、当你声明一个变量背后发生了什么?
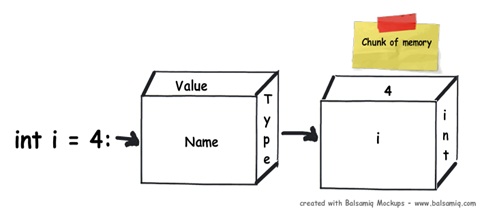
当你在一个.NET应用程序中定义一个变量时,在RAM中会为其分配一些内存块。这块内存有三样东西:变量的名称、变量的数据类型以及变量的值。
上面简单阐述了内存中发生的事情,但是你的变量究竟会被分配到哪种类型的内存取决于数据类型。在.NET中有两种可分配的内存:栈和堆。在接下来的几个部分中,我们会试着详细地来理解这两种类型的存储。
三、存储双雄:堆和栈
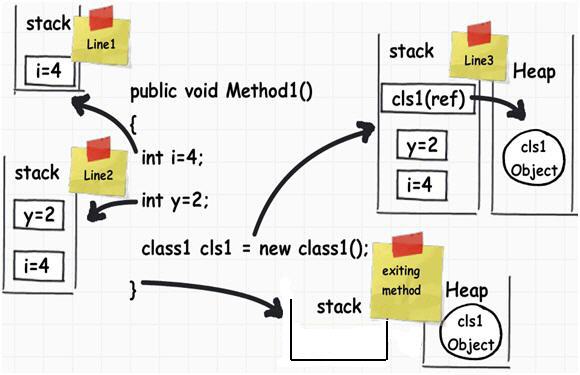
为了理解栈和堆,让我们通过以下的代码来了解背后到底发生了什么。
public void Method1()
{
// Line 1
int i=4;
// Line 2
int y=2;
//Line 3
class1 cls1 = new class1();
}
代码只有三行,现在我们可以一行一行地来了解到底内部是怎么来执行的。
- Line 1:当这一行被执行后,编译器会在栈上分配一小块内存。栈会在负责跟踪你的应用程序中是否有运行内存需要
- Line 2:现在将会执行第二步。正如栈的名字一样,它会将此处的一小块内存分配叠加在刚刚第一步的内存分配的顶部。你可以认为栈就是一个一个叠加起来的房间或盒子。在栈中,数据的分配和解除都会通过LIFO (Last In First Out)即先进后出的逻辑规则进行。换句话说,也就是最先进入栈中的数据项有可能最后才会出栈。
- Line 3:在第三行中,我们创建了一个对象。当这一行被执行后,.NET会在栈中创建一个指针,而实际的对象将会存储到一个叫做“堆”的内存区域中。“堆”不会追踪运行内存,它只是能够被随时访问到的一堆对象而已。不同于栈,堆用于动态内存的分配。
- 这里需要注意的另一个重要的点是对象的引用指针是分配在栈上的。 例如:声明语句 Class1 cls1; 其实并没有为Class1的实例分配内存,它只是在栈上为变量cls1创建了一个引用指针(并且将其默认职位null)。只有当其遇到new关键字时,它才会在堆上为对象分配内存。
- 离开这个Method1方法时(the fun):现在执行控制语句开始离开方法体,这时所有在栈上为变量所分配的内存空间都会被清除。换句话说,在上面的示例中所有与int类型相关的变量将会按照“LIFO”后进先出的方式从栈中一个一个地出栈。
- 需要注意的是:这时它并不会释放堆中的内存块,堆中的内存块将会由垃圾回收器稍候进行清理。
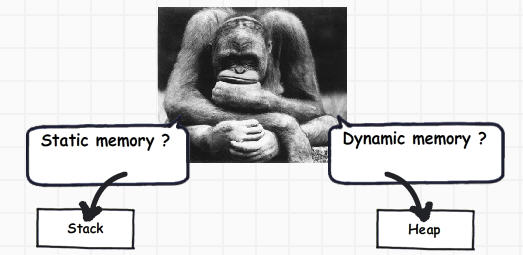
现在我们许多的开发者朋友一定很好奇为什么会有两种不同类型的存储?我们为什么不能将所有的内存块分配只到一种类型的存储上?
如果你观察足够仔细,基元数据类型并不复杂,他们仅仅保存像 ‘int i = 0’这样的值。对象数据类型就复杂了,他们引用其他对象或其他基元数据类型。换句话说,他们保存其他多个值的引用并且这些值必须一一地存储在内存中。对象类型需要的是动态内存而基元类型需要静态内存。如果需求是动态内存的话,那么它将会在堆上为其分配内存,相反,则会在栈上为其分配。
四、值类型和引用类型
既然我们已经了解了栈和堆的概念了,是时候了解值类型和引用类型的概念了。值类型将数据和内存都保存在同一位置,而一个引用类型则会有一个指向实际内存区域的指针。
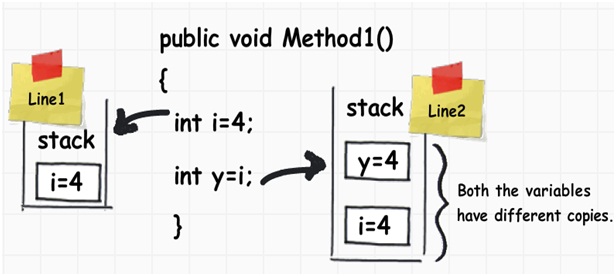
通过下图,我们可以看到一个名为i的整形数据类型,它的值被赋值到另一个名为j的整形数据类型。他们的值都被存储到了栈上。
当我们将一个int类型的值赋值到另一个int类型的值时,它实际上是创建了一个完全不同的副本。换句话说,如果你改变了其中某一个的值,另一个不会发生改变。于是,这些种类的数据类型被称为“值类型”。
当我们创建一个对象并且将此对象赋值给另外一个对象时,他们彼此都指向了如下图代码段所示的内存中同一块区域。因此,当我们将obj赋值给obj1时,他们都指向了堆中的同一块区域。换句话说,如果此时我们改变了其中任何一个,另一个都会受到影响,这也说明了他们为何被称为“引用类型”。
五、哪些是值类型,哪些是引用类型?
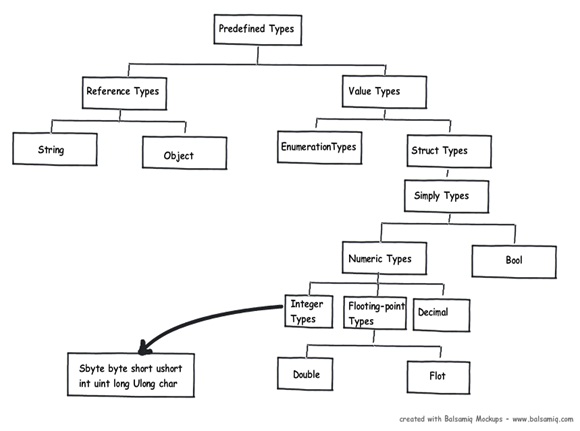
在.NET中,变量是存储到栈还是堆中完全取决于其所属的数据类型。比如:‘String’或‘Object’属于引用类型,而其他.NET基元数据类型则会被分配到栈上。下图则详细地展示了在.NET预置类型中,哪些是值类型,哪些又是引用类型。
六、装箱和拆箱
现在,你已经有了不少的理论基础了。现在,是时候了解上面的知识在实际编程中的使用了。在应用中最大的一个意义就在于:理解数据从栈移动到堆的过程中所发生的性能消耗问题,反之亦然。
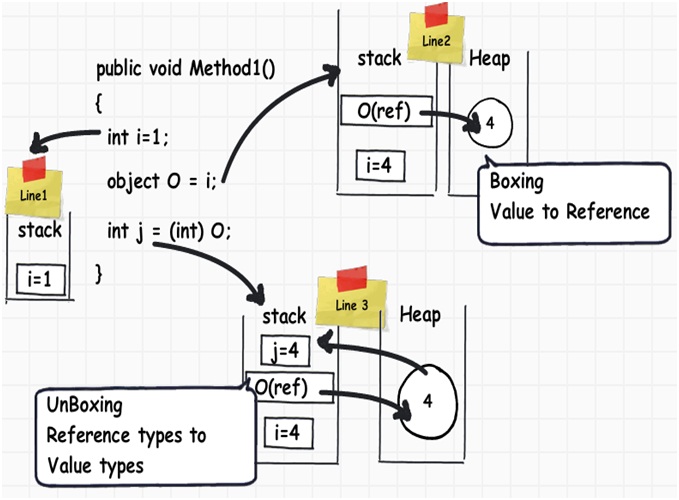
考虑一下以下的代码片段,当我们将一个值类型转换为引用类型,数据将会从栈移动到堆中。相反,当我们将一个引用类型转换为值类型时,数据也会从堆移动到栈中。
不管是在从栈移动到堆还是从堆中移动到栈上都会不可避免地对系统性能产生一些影响。
于是,两个新名词横空出世:当数据从值类型转换为引用类型的过程被称为“装箱”,而从引用类型转换为值类型的过程则被成为“拆箱”。
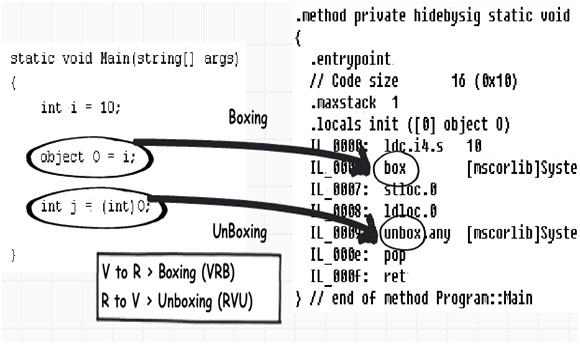
如果你编译一下上面这段代码并且在ILDASM(一个IL的反编译工具)中对其进行查看,你会发现在IL代码中,装箱和拆箱是什么样子的。下图则展示了示例代码被编译后所产生的IL代码。
七、装箱和拆箱的性能问题
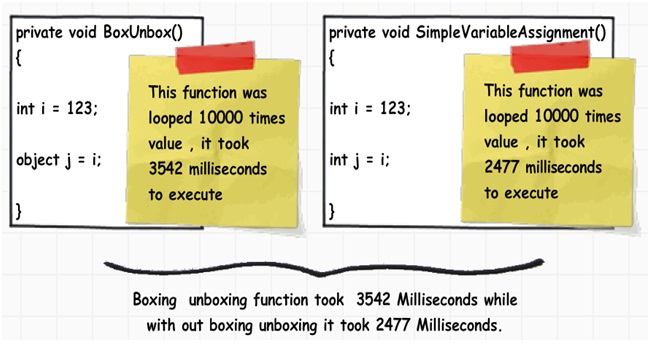
为了弄明白到底装箱和拆箱会带来怎样的性能影响,我们分别循环运行10000次下图所示的两个函数方法。其中第一个方法中有装箱操作,另一个则没有。我们使用一个Stopwatch对象来监视时间的消耗。
具有装箱操作的方法花费了3542毫秒来执行完成,而没有装箱操作的方法只花费了2477毫秒,整整相差了1秒多。而且,这个值也会因为循环次数的增加而增加。也就是说,我们要尽量避免装箱和拆箱操作。在一个项目中,如果你需要装箱和装箱,请仔细考虑它是否是绝对必不可少的操作,如果不是,那么尽量不用。
虽然以上代码段没有展示拆箱操作,但其效果同样适用于拆箱。你可以通过写代码来实现拆箱,并且通过Stopwatch来测试其时间消耗。
译者:周旭龙
出处:http://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。