class="topic_img" alt=""/>
class="topic_img" alt=""/>
������������ڰ�һ�� Python 2 ����Ƶ���ع��� youku-lixian ��д�� Python 3�����������Լ���Ҫ�� YouTube ֧�֡�
������ Linux �£�������еú�˳�������еĶ������� UTF-8����������Python 3 ��� str ���ʹ� 2.x �汾�� ASCII �ַ�������� Unicode �ַ��������Ƴ���ԭ����������ڱ��ر������͵��жϴ������֡������ץȡ��ҳ������������Ƶ���ⲿ�ֵ� Unicode �ַ�����ֱ�� print ()��ʾ���������һ�п������ܺ�г��
�����ٶ���ץȡ�������Ƶ���������ģ�����“��ã�����”��������֪�������� Python ���õ� Unicode ֧�֣������ֻ��Ҫ��һ�䣺
print ('��ã�����')��������ɱ�� Windows 7�²����������ʱ���鷳�ͳ����ˡ��������֪����Ϊʲô��ô˵�����������ȥ��
�����������˽�� Windows
����ȥ���ѧУ�õ���̨ Dell �ʼDZ�ʱ��Windows 7 ��Ȼ��Ԥװ������ġ�
����ϵͳ�����Ѿ����ó���Ӣ��ܿ죬�Ҷ��������̵IJ��ָе����䲻��Ӧ�����ı�����λ����Ӣ����̲����кܴ����𣬷ֺš�ð����������˫���š�б�ܷ�б����Щ����Ա˾�ռ��ߵķ��ţ�����ʽӢ�������ȫ��ͬ�����ǣ��ҰѼ��̲��ֻ�����ϰ����Ӣ����̣�˳��ѿ�������“����”ѡ��Ҳһ�Ŵ���任����Ӣ��/������
�����ںܳ�һ��ʱ������˽�����Ӣ�����⣬���������������õ�����ϵͳûʲô������Ĭ�ϵ��������壬���뷨�����������ĵġ���ƽʱ�������ģ�ֻ�У���������Ѹ�ף��� IE ���������� Mirror's Edge�������¶��ѡ�
�����ļ�ϵͳ�� Unicode ����ģ�Web �������֧�� Unicode �ģ�ż���õ��ı��༭��Ҳ��һ�����ó� UTF-8 �ġ���������֪������ Windows 2000 ��Windows ������ʵ����ʹ�� UTF-16LE �ġ��������˿�Ҫ���˻��д���ҳ��ôһ���¡�
�������ǣ����Ҫ��Ӣ�� Windows ϵͳ��������ʾ����ִ���������� Unicode �ı��ij���
#!/usr/bin/env python # -*- coding: utf-8 -*- if __name__ == '__main__': print ('������')
����Python �ͻ�������һ��������
File "c:\Python32\lib\encodings\cp437.py", line 19, in encode return codecs.charmap_encode (input,self.errors,encoding_map)[0] UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-1: character maps to <undefined>
�����ѵ� Python 3 ����֧�� Unicode �����ѵ���������ƽ̨����
������һ�����⣬�������ǶԵģ�Python 3 ȷʵ֧�� Unicode������֧���������������е� str �ַ�������Ϊ Unicode ������������ϡ�
�����ڶ������⣬����ȫ����ƽ̨�Ŀ���ֲ�����������ġ�Python ������֧�� Unicode��������������˷� Unicode �ĹŶ��������Ǿ�һ��취Ҳû�С�
����ʲô��“�� Unicode �ĹŶ�����”��……������˵�IJ��� DOS�������������Ȼ���� Windows �ϵ�cmd.exe��ÿ���˻����ٶ��ù��������л�����
����cmd.exe���� MinGW �� Python��������ÿ�� Windows ����Ҫ�Ӵ������еĿ�����Ա���㲻��ȥ�Ķ���������ô�Ͳ��ܰ�������Щ�����ڴ�С��������������Ҳ�����ˣ�����ȫ����ʾҲ�����ˣ������С��Ļ�������ø�������Ҳ�����ˣ������ק������Ҳ�����ˣ������в�ȫ����ȫҲ�����ˣ���ô��ܰ�Ĭ�ϱ���ij��� Unicode �ɣ�һ���ƴ��ڴӶ�ʮ��ǰ�� 3.x ʱ�����õ������ Windows 7�������� DOS ��command.com��������cmd.exe��������ô�����ˣ�Ҳû����������ʲôʵ�ʵĸĽ����Dz��������������еij���Ա�����ø������� IDE“����� code”������Ҫ�������ˣ�
�������� Windows �Ѿ���ȫʹ�� UTF-16 ��Ϊ����ʵ�ֵĽ��죬cmd.exe��Ȼ��ʹ��ϵͳĬ�ϵĴ���ҳ���������뵽��Ψһ���ɾ���Ϊ�˱��ֺ���ǰ�� non-Unicode �������——����������Ҳ̫���˰ɣ�
�������й���� Windows 8 �Ľ������û�����ڣ�����������������ѹ����������cmd.exe����������ø�����Щ������������ȥ�ˣ�˵��������ľ�����
����ǰ�� Python �Ĵ�����Ϣ���ᵽ�˸��ļ�cp437.py����Ȼ�� cp437 ʲô�ģ��Ǿ�һ���� Python ����ͼ�� Unicode �ַ���ת������������� 437 ����ҳ��Ӣ��/������ʱ���˴���
����Ϊʲô Python Ҫ��һ���ö˶˵� Unicode �ַ���ת���� cp437 �أ����������ͨ����Ϊ��������cmd.exe����ն˻�����ִ�еġ����ҵ�Ӣ��ϵͳ�ϣ����Ļ����ҳ�� 437��Ӣ��/���������Ӵ����е� Unicode �ַ�������� cp437 ����һ��ת�������� Python ��������ʵ�ֵģ����Ի��� Python �׳�һ����������ֱ���ڿ���̨���һ�����롣
���������뵽�Ľ����������Ȼ�Ǹı䵱ǰcmd.exe�Ļ����ҳ�� UTF-8 Unicode��
chcp.com 65001�������ҵ��ǣ���� Python ������ֱ�ӱ����ˣ�
Fatal Python error: Py_Initialize: can't initialize sys standard streams LookupError: unknown encoding: cp65001 This application has requested the Runtime to terminate it in an unusual way. Please contact the application's support team for more information. LookupError: unknown encoding: cp65001
��������һ�²�������Python 3.2 Ŀǰ����֧�� Windows ����� cp65001����˵ 65001 ����ҳ������ UTF-8 ������壩
��������˵�Dz�֧�֣�����˵�� bug ������Щ����Ϊִ��֮�� Windows ������һ�������˵“python.exe�Ѿ�ֹͣ��Ӧ”��……
�������ǣ����Ÿı����ҳ�� GBK��
chcp.com 936�������ȴ�ǣ�
Invalid code page����Windows ��������һ����Ч�Ĵ���ҳ��Ϊʲô��
����������ʲô
�������ˣ���������cmd.exe����������˲����Ķ������� IDLE ����һ�ԡ�
�����Ҳ�֪���ж��� Linux ����Աд Python ��ʱ����õ� IDLE��������Щϰ�����ն�+�ı��༭�����û���˵��IDLE �������Ǹ��ؽ�Ҫ�ĸ���Ʒ��Ҳ�����Ķ�λֻ������������ѧ�����ŵ�һ������������
�������������ױ����Ǻ��Ե�һ���ǣ�IDLE �����Ǹ���ƽ̨�Ļ���������ζ��������������֧�� Unicode��ֻҪϵͳ������Ӧ�����壩������������ִ�г����������ض��ն˻����ľ�������һ���� Windows �Ϻ���Ҫ����Ϊcmd.exe������ʵ����̫��ˣ����Թ��ƺܶ����� Windows �½���ִ�� Python ��ʱ���ǻ�ѡ�� IDLE �ġ�
�������� IDLE�����ǿ���Ҫ����һ����� Windows ϵͳ�����Ĭ�ϱ��뷽ʽ��ʲô��Python 3 ����������������
>>> sys.stdout.encoding; locale.getpreferredencoding () 'cp1252' 'cp1252'
������һ��sys.stdout.encoding��ָ������ı��룬�ڶ���locale.getpreferredencoding����ϵͳ���ػ����õı��롣������������ġ��������ǿ����������ڵ�ǰ����������ͬ�ģ�����Ĭ�ϵ�cp1252��Ҳ���Ǵ�˵�е�“ANSI”����ҳ��
�������������Ѿ�֪�� IDLE ��һ����ȫ��ƽ̨�Ļ����������� IDLE ����� Unicode �ַ����Եõ��� Linux ������ͬ����г�Ľ����
>>> print ('��ã�����')��ã���������˳�㿴��“��ã�����”�� UTF-8 ����� GBK ��ʲô�����ǿ�����������뷽ʽ�������ֻ�õ������Ľ��������Ҳ�����õ��������Կ�����5 ��ȫ���ַ��� UTF-8 �������� 15 ���ֽڣ�ÿ���ַ�ռ 3 bytes���� GBK �������� 10 ���ֽڣ�ÿ���ַ�ռ 2 bytes��
������Ȼû��ʲôʵ�ʵ��������������ǿ���ע���UTF-8 ������ַ������� GBK ����ģ�������������ʱ��Ҳ���У���Ϊ���ܻ���������ֽڳ��ȣ����� GBK �²��Ϸ�����֮ GBK �����ַ������� UTF-8 ���룬��Ϊ����Ч�ַ�ֵ�Ĵ��ڡ�
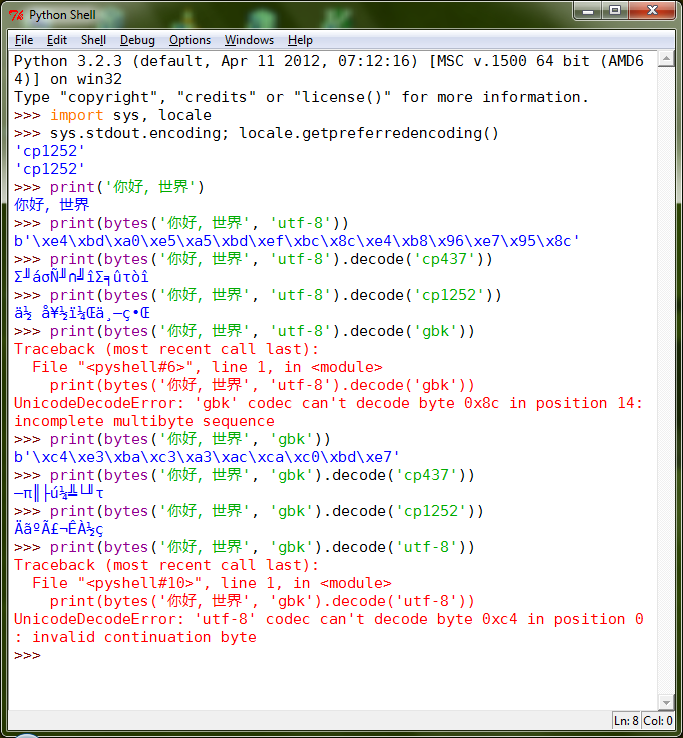
�������� IDLE ������“��ã�����”���ֱ������ϸ������������ǿ��Իص�cmd.exe���濴һ��������γ�������н���ˣ�
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys, locale if __name__ == '__main__': print(sys.stdout.encoding, locale.getpreferredencoding ()) try: print('������') except Exception as err: print(str (err))
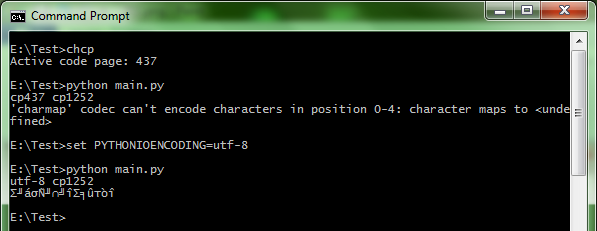
��������ͨ��chcpȷ�ϣ�cmd.exe�ĵ�ǰ�����ҳ�� 437��Ӣ��/������������ IDLE ��� 1252��ANSI�������������ҵ� Windows ��� non-Unicode ���������������“Ӣ��/����”��Ե�ʡ�
�����������еĽ���ǣ�
cp437 cp1252 'charmap' codec can't encode characters in position 0-4: character maps to <undefined>
�������Կ���sys.stdout.encodingʵ���Ͼ��ǵ�ǰ�����»����ҳ��ֵ��locale.getpreferredencoding ()û�䣬��Ȼ��ϵͳĬ�ϵ� cp1252��
����֮���׳����쳣��������Ԥ��֮�еģ������ǰһ����Python ���� Unicode �ַ���ת���� cmd �ն��µ� cp437 ����ҳ���롣�������ַ���������û�ж�Ӧ�� cp437 ����ģ����� Python ������
����Google һ��'charmap' codec can't encode characters in position 0-4: character maps to <undefined>��������� Stack Overflow �ϣ������ᵽ�˽���ķ���������һ������PYTHONIOENCODING�Ļ���������
����PYTHONIOENCODING ��������
������ν��PYTHONIOENCODING���ȿ�����Ϊ�����������ڣ�Ҳ������Ϊ Python �������в������ݡ�������ָ�� Python ��������������stdin/stdout/stderr���ı��롣��ע��������벻��ָԴ����ı��룬�� Python ����ͷ������# -*- coding: utf-8 -*-�������£�
������û�������������ʱ
������ǰ��������Python ����ͼ���ڲ� Unicode ������ַ���ת���ɵ�ǰִ�г�����ն˻�������ʹ�õı��뷽ʽ��sys.stdout.encoding������������ڵ�ǰ����ҳ 437 ��cmd.exe��˵����ֻ����Ӣ�����ֵ��ַ���ת�� cp437 ����û���κ����⣻����һ�������������ַ���Ӣ��/������ 437 ����ҳ���Ȼ���Ҳ�����Ӧ�ı���ģ����� Python �ͻᱨ����
���������ǰ����ҳ��� 65001��Python 3.2 ����������DZ���ʵ���ϵ����⡣�����µ� Python 3.3 beta ���Ѿ������˶� cp65001 ��֧�֡�
�����������������������ʱ
����ͨ��
set PYTHONIOENCODING=utf-8������PowerShell �£�
$env:PYTHONIOENCODING = "utf-8"����PYTHONIOENCODINGָ���ı��뷽ʽ�Ḳ��ԭ����sys.stdout.encoding�������PYTHONIOENCODING����Ϊ utf-8����ô Python ����� Unicode �ַ�����ʱ��ͻ��� UTF-8 ������൱��ʲôҲ��ת����
�����ٴ�ִ�и� Python ������һ�� Python ���ٳ����Զ�ת�� Unicode �������ַ��� cp437 �еĶ�Ӧ�ַ�������ɹ����У�sys.stdout.encoding����� utf-8���ַ�������������룺
utf-8 cp1252Σ�`áσÑ�`∩�aîΣ�Yûτòî������������֮ǰ�� IDLE �н� UTF-8 ������ı�ǿ���� cp437 ����õ��Ľ������ȫ��ͬ�ģ�
>>> print(bytes ('��ã�����', 'utf-8') .decode ('cp437')) Σ�`áσÑ�`∩�aîΣ�Yûτòî
����Python ֱ�Ӱ� UTF-8 ������ַ���������� cp437 ����ҳ���նˣ��൱��ǿ���� cp437 ������ UTF-8 �ı�������������������롣
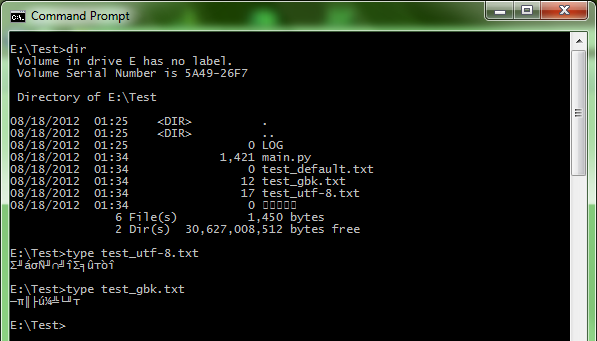
�������ı��༭��дһ��������“��ã�����”���ļ����� UTF-8 ���뱣�档��cmd.exe��ͨ�� type ��ʾ���������������ͬ�ġ�
����cmd.exe �� PowerShell ISE ����֮���Ա�
�����ڵ�ǰ�������ã�Ӣ��/�������£�����ִ��chcp.com��ʾ�ĵ�ǰ�����ҳ���� 437��
����ֻ�� cmd �� Python ��sys.stdout.encodingĬ���� cp437��������ҳ��ͬ����PowerShell ISE ��sys.stdout.encoding���� cp1252��ANSI����
����locale.getpreferredencoding��Զ��ϵͳ����Ĭ�ϵ� cp1252������һ��ϵͳȫ��ֵ��
����cmd ���������ģ�������ȷ��ʾ�ļ�ϵͳ�е������ļ�����PowerShell ISE �ܹ��������ģ�����ʾ�����ļ�����
������ȱ�� 936 ����ҳ������£����߶����ܹ�ͨ��ִ���ű��� type �ļ�������ȷ��ʾ�����ַ��������� GBK ���� UTF-8������������롣
����Ϊʲô Windows ��ȱ�� GBK ����ҳ��
�����ص�������Ǹ�����������Ϊʲôִ��chcp.com 936�����л��� GBK ����ҳ��Ϊʲôcmd.exe�� PowerShell �ﲻ��������ʾ���ģ�
��������������Ұ�˼������⡣���˼���Сʱ�ҵ���ԭ�����֮����Ϊ Windows ��“���������”���ò��ԡ�
����“Language for non-Unicode programs”���ѡ��Ǽ������ģ����ԾͲ����� GBK���ֶ�chcp.comҲ�������ô���ҳ��Ч�����Ա���Ҫ�ڿ�����������óɼ������ģ������������Ч��
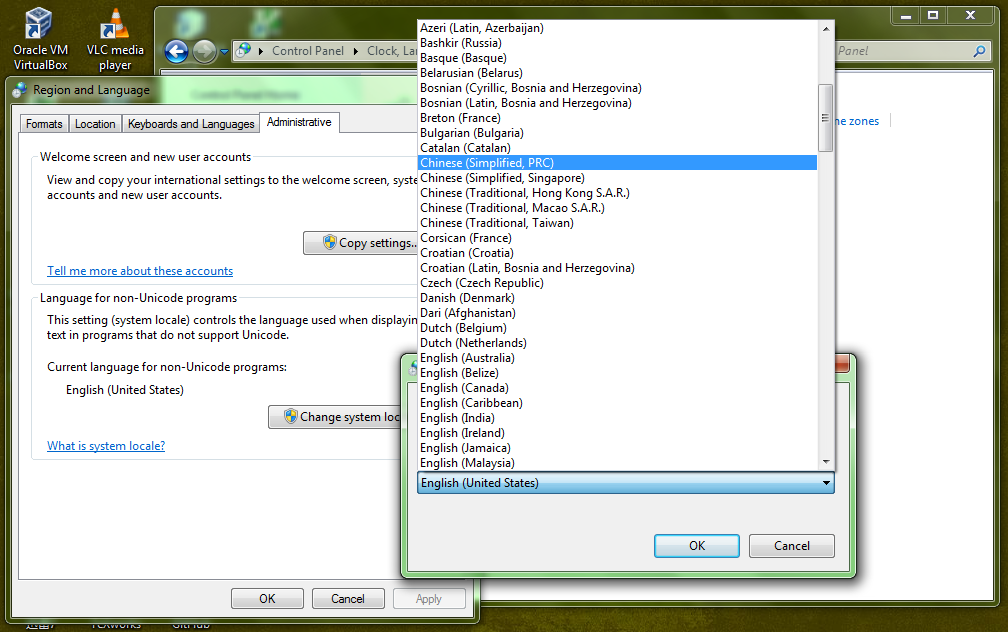
�����ðɣ��������ˣ�Ϊʲô����ֻ�ܵ�ѡ������Ҽ���ʹ�� 936��GBK�������Ӧ�ó�������ʹ�� 932����������Ӧ�ó����ѵ�ÿ�ζ�Ҫ������������������Ϊʲô���Dz��ܸ�һ����ϸ�Ĵ���ҳ�б����û���ѡ����Ҫʱ���Զ�̬���أ�
����Windows ��Ƶ�����֮�������������㲻ȥ���� system locale Ϊ���IJ����������� non-Unicode ������������ַ������Dz�����ֵģ�ֻ����ʾ��һ��������cmd.exe�

�������� Vim �set fileencodings=utf-8,gbk����GBK ������ı��� UTF-8 ������ı���һ������ʾ��������˵ Vim Ӧ�ò����� non-Unicode �����……˭֪���أ�����
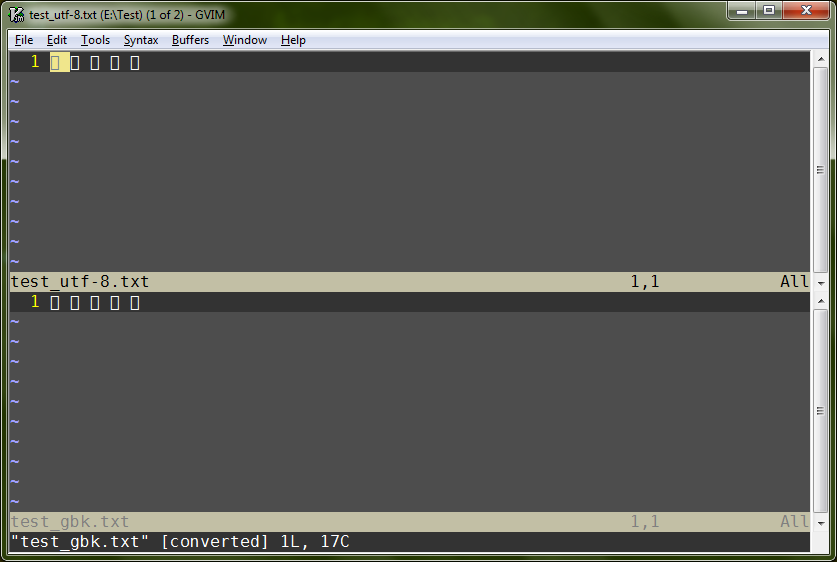
�����Ĺ�"Language for non-Unicode programs”Ϊ���IJ�������ϵͳ֮��Vim ������ʾ������

�����ٽ�cmd.exe��Ĭ�ϻ����ҳ 936����� Python ��������Ҳ����ȷ����ˣ�

����Ҳ�� Windows ���ֵ��۵��������Ϊ���ǵ�Ӣ���û�һ�㲻����Ҫ����� Unicode �ʹ���ҳ�ַ�������ô�����Խ�ʡϵͳ����ʱ�䣿˭֪���أ�Windows �û�������ϲ������ν��“����ʱ���”��Ϊ����ϵͳ���ܵ�ָ������……
�����л��� cp65001��UTF-8 Unicode����PYTHONIOENCODING���ó� utf-8��������˵���ַ�ʽ��Ӧ�ó����⣬�����������ô��������������������ͼ��ʾ�������������Ϊʲô�ˣ���֮ Windows ���涫���ĸ��ӳ̶�����������������Զ�����ܹ�������……
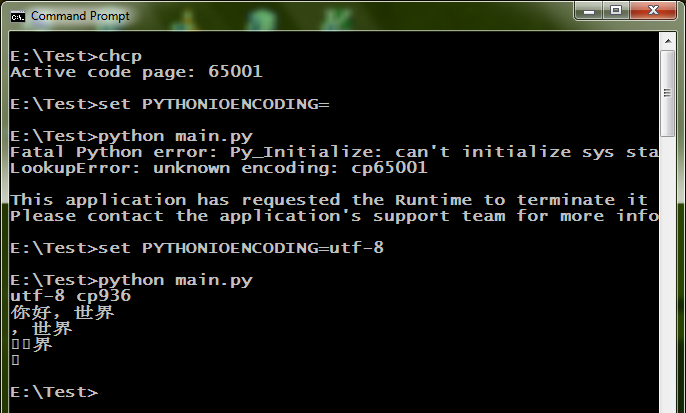
����Python ���˱��������������……
�����ļ���
open ('�ļ�������'�� 'w')����Python �ж��ļ�ϵͳ�IJ����������Dz���Ĭ�ϱ���Ӱ��ģ�ֻҪsys.getfilesystemencoding ()�Ľ���� utf-8���ִ� Linux������ mbcs���ִ� Windows NT ϵͳ�ϣ������߱����϶��� Unicode ���롣
�����ļ��������
�����ļ���д�����ڱ�I/O����˺ͻ�������PYTHONIOENCODING�ء�
for c in ['utf-8', 'gbk']: with open ('test_%s.txt' % c, 'w', encoding=c) as output: try: output.write ('������\n') except Exception as err: print('\nWriting to file using %s:\n' % c, str (err))
���������� open ()����ʽָ�������ı��뷽ʽ��encoding='utf-8'��encoding='gbk'�������“��ã�����”�����������ı����κ�ƽ̨�϶�Ӧ���ܹ��õ���ȷ�Ľ����
����Ȼ�����ڣ�
with open ('test_default.txt', 'w') as output: try: output.write ('������\n') except Exception as err: print('\nWriting to file using default encoding:\n', str (err))
��������û��ָ�����뷽ʽ��Python ���Զ�ʹ��ϵͳĬ�ϵı��뷽ʽ��������������ϵͳĬ�ϱ����� cp437 �� cp1252�����������ַ�����Щ����ҳ����Ȼ�����ڶ�Ӧֵ��Python ���׳�һ����Ϥ�Ĵ���
File "c:\Python32\lib\encodings\cp437.py", line 19, in encode return codecs.charmap_encode (input,self.errors,encoding_map)[0] UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-1: character maps to <undefined>
������Ȼ����ϵͳĬ�ϱ���Ϊ cp936��GBK��ʱ������
output.write ('������')��������
print ('��ã�����')����������������������Ϊ“��ã�����”��� Unicode �ַ����ǿ��Ա���ȫת���� GBK �еĶ�Ӧ����ġ�
����һЩ�ܽ��˼��
������Ȼ Python 3 ʹ�� Unicode ������ַ����������ڿ�ƽ̨�ij�������ȻҪȡ��ϵͳ��Ĭ�ϱ������ں�����������Ϊ���������е��ն˻�����֧��ȫ���� Unicode �ַ�����
if sys.stdout.isatty () default_encoding = sys.stdout.encoding else default_encoding = locale.getpreferredencoding ()
�������ۺ�ʱ����Ҫ������������ print ()�� stdout ��� Unicode �ַ��������ij��Ҫ����� Unicode �ַ������磬�����֣���ϵͳĬ�ϱ�����ַ��������磬����ҳ 437����û�У�Python ��ʱ�ͻ��׳�һ����������ʵ�ڴ�ʱ���������뿴���ľ��棬������ϣ����ʹ��ʱ�����һЩ����������룬����������Ҳ����ȷ���С�����Ƶ���ع��ߵ�������˵����ʹ�����ն˵Ĺ�ϵ��ʱ����ȷ��ʾ��Ƶ���ƣ������Ⲣ��̫���أ���Ϊ�������ǿ���ץȡ����Ƶ����д����ȷ���ļ��ġ�
�����ڳ����л�ȡ��ϵͳĬ�ϵ�default_encoding�����ǾͿ���ǿ���������� Unicode �ַ������б��룬���ٱ����� Python ���Զ�ת������п��ܻ��׳��Ĵ���——��Ȼ�������ֻ�ǵõ�һ�����롣����һ�ִ�����ʽ�Ƕ����������ַ��������Ǿ���������ȥ������ǡ�
�������DZȽ�Ը�⿴��������ǣ��������������ֻ��������ģ���������е� Windows �û�Ⱥ��ʹ�õĴ���ҳ�� 936��GBK��——�����ڳ�����ʹ�� Unicode �ַ����ɣ���������������κ����⡣
�������ǣ��������ȷ��Ҫ������ Unicode �ı��������ĸ�����ҳ�ַ����ķ�Χ���У����ģ����ģ�ϣ�����ģ��������ģ�����……�����ģ����ʱ��ͱ��뿼�ǵ������ϻ���“���뷽ʽ����”������ˡ���Ȼ����õĽ����ʽҲ���ǣ������û���ȥ���Ĵ���ҳ��ȥ����ʲô 437��500��936��1252……��ѹ�������֣�ȥ���� Bush hid the facts���ӵ�����������⡢���뷽ʽ��˻��ҺͲ�һ�µ� Windows��תͶһ����������IJ���ϵͳ�ɡ�