好几天没有更新了,给关心这个系列的朋友们说声抱歉。今天我们开始第二节,项目功能分析。因为这个背单词软件虽说功能比较简单,但要真正实现起来也挺麻烦的。所以今天我们首先分析一下这个应用的功能,然后逐条慢慢实现。
PS:这款应用已经上线91助手,百度移动应用和应用宝,有兴趣下来研究的可以百度搜索“悦词i背单词91”就可找到,我想真正用一下这个应用再看这个教程会有比较直观的理解。好废话不多讲,进入正题。
功能分析:
功能1、查单词。
实现方法:金山词霸开放平台提供了一个开放API,通过Http访问金山词霸API提供的URL,可以获得一个XML文档,这个文档就包含了要查询的单词的释义、例句、音标、声音的地址。通过解析该XML就可以获得单词的所有信息。
所用到的技术:
1)Http访问网络,并下载网络文件
2)对SD卡进行操作,从SD卡(这里的SD卡是指手机默认的存储卡,因为有些手机既 能能插SD卡又有内部存储,这里不涉及这个问题)中读取文件,和把从网络下载的文件存进 SD卡。
3)解析XML文件
4)播放音乐(这个我后来封装成了一个类,专门从网络上查询某个单词,解析XML文 件,并且将下载的Mp3文件存在SD卡中,然后播放该Mp3文件)
5)数据库,这里涉及到第一个数据库,每查找一个单词之后,就会将该单词和释义存储 到一个SQLite数据库中。这样一来,下一次查找这个单词时,先访问数据库,看看数据库中 有没有这个单词,若有,就不用访问网络了。
功能2、背单词。
实现方法:这里要用到第二个数据库,背单词的词库。我们需要一个存放单词的TXT文件,通过解析这个TXT文件,将要背的单词解析并存进数据库中,然后根据一定的规律弹出单词。
所用到的技术:
1)数据库,同前面的数据库技术相似;
2)对TXT文件中的单词进行解析,字符串解析函数;
3)单词状态机,设计一定的算法,按照一定的规律弹出单词,并进行背词操作。(这个确实挺麻烦)
4)文件浏览,做一个简易的文件浏览器,用于浏览SD卡中的单词源文件txt,然后导入词库。这个属于比较单独的一个功能。
功能3、设置界面
用于对背词软件的一些参数进行设置,比如播放英音还是美音?前后两个的单词的背词间隔是多少?导入词库设置?计划完成日期,以及当前课程的名称设置。
功能4、金山词霸每日一词
实现方法:这里要用到第三个数据库(就是数据库的一个表table),用于记录使用者的信息,如当前日期,当日期有更新时,应用会自动访问网络,获取最新的额每日一句,并且呈现在主界面上;当前背单词的完成进度,今天已经背的单词,待完成的单词,以及根据计划完成日期算出今天应该的单词的任务,(关于这一点大家可以参考拓词的实现效果)
所用到的技术:
1)数据库技术;
2)Http访问网络,从网络下载图片并显示。
注意这一个功能虽然看似简单,但是,实现这个功能之后这个应用才显得活起来^^
好了以上就是这款应用的主要框架。今天我们就来开始实现第一个功能:查单词功能。
首先讲一下金山词霸API:浏览器输入http://open.iciba.com/就会出现啊如下界面:

点击词霸查词、并选择文档选项,http://open.iciba.com/?c=wiki,就可以看到如下界面:

再点击查词接口,就到了final page:

大家会注意到我们需要的东西:http://dict-co.iciba.com/api/dictionary.php?w=go&key=******** 这里的key是你自己申请的金山词霸开放平台的API key,申请界面在这里:
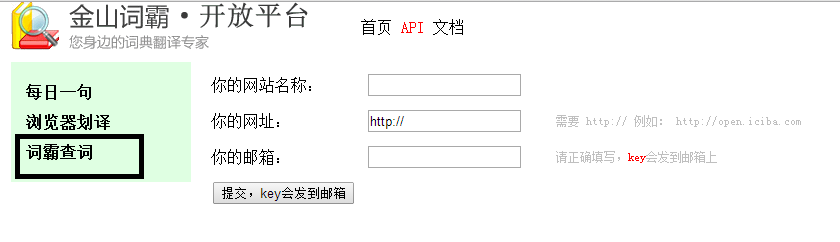
网址随便填即可
当你申请到金山API key之后,就可在浏览器输出上面的地址:http://dict-co.iciba.com/api/dictionary.php?w=go&key=这里换成你的API key.
这里多说一句,为什么选金山词霸API呢,其实有道词典也有开放API,但它提供的数据远不如金山词霸,最重要的一点:金山提供的单词的发音(金山真是够仗义的)
例如我们查一个hello,就可以在浏览器输入http://dict-co.iciba.com/api/dictionary.php?w=hello&key=这里换成你的API key. 就是把w=后面写成hello,注意首字母必须小写!
<dict num="219" id="219" name="219"> <key>hello</key> <ps>h?'l??</ps> <pron> http://res-tts.iciba.com/5/d/4/5d41402abc4b2a76b9719d911017c592.mp3 </pron> <ps>h??lo, h?-</ps> <pron> http://res.iciba.com/resource/amp3/1/0/5d/41/5d41402abc4b2a76b9719d911017c592.mp3 </pron> <pos>int.</pos> <acceptation>哈喽,喂;你好,您好;表示问候;打招呼;</acceptation> <pos>n.</pos> <acceptation>“喂”的招呼声或问候声;</acceptation> <pos>vi.</pos> <acceptation>喊“喂”;</acceptation> <sent> <orig> This document contains Hello application components of each document summary of the contents. </orig> <trans>此文件包含组成Hello应用程序的每个文件的内容摘要.</trans> </sent> <sent> <orig> In the following example, CL produces a combined source and machine - code listing called HELLO. COD. </orig> <trans>在下面的例子中, CL将产生一个命名为HELLO. COD的源代码与机器代码组合的清单文件.</trans> </sent> <sent> <orig>Hello! Hello! Hello! Hello! Hel - lo!</orig> <trans>你好! 你好! 你好! 你好! 你好!</trans> </sent> <sent> <orig>Hello! Hello! Hello! Hello ! I'm glad to meet you.</orig> <trans>你好! 你好! 你好! 你好! 见到你很高兴.</trans> </sent> <sent> <orig>Hello Marie. Hello Berlioz. Hello Toulouse.</orig> <trans>你好玛丽, 你好柏里欧, 你好图鲁兹.</trans> </sent> </dict>
这个XML中含有几个元素:key:单词本身; ps:第一个是英音音标,第二个是美音音标; pron第一个是英音的MP3地址,第二个是美音的;pos 词性; acception 词义;sent 例句; orig例句英语;trans例句中文翻译。我们要做的就是根据XML文件把这几个元素解析出来。
另外这里就涉及到了另一个问题:能不能查中文呢?一开始我也没搞出来,后来才发现了秘密查中文(或日文)需要在待查的词前面加上一个下划线 _ 即如 :_你好
搜索你好:http://dict-co.iciba.com/api/dictionary.php?w=_你好&key=这里换成你的API key ,得到结果
<dict num="219" id="219" name="219"> <key>你好</key> <fy>Hello</fy> <sent> <orig>Hello! Hello! Hello! Hello! Hel - lo!</orig> <trans>你好! 你好! 你好! 你好! 你好!</trans> </sent> <sent> <orig>Hello! Hello! Hello! Hello ! I'm glad to meet you.</orig> <trans>你好! 你好! 你好! 你好! 见到你很高兴.</trans> </sent> <sent> <orig>Hello Marie. Hello Berlioz. Hello Toulouse.</orig> <trans>你好玛丽, 你好柏里欧, 你好图鲁兹.</trans> </sent> <sent> <orig> B Hi Gao. How are you doing? It's good to meet you. </orig> <trans>B你好,高. 你好 吗 ?很高兴认识你.</trans> </sent> <sent> <orig> Grant: Hi , Tess. Hi , Jenna. Are you doing your homework? </orig> <trans>格兰特: 你好! 苔丝. 你好! 詹娜. 你们在做家庭作业 吗 ?</trans> </sent> </dict>
注意fy元素就是查询的意思,在解析XML文件时要考虑到这一点。
根据以上分析,我们首先需要访问网络,将这个xml文件下载下来并进行解析,下面我给出几个工具类:
访问网络类,注意对应的要在AndroidManifest.xml文件中添加访问网络权限。
package com.carlos.internet; import java.io.InputStream; import java.net.HttpURLConnection; import java.net.URL; public class NetOperator { public final static String iCiBaURL1="http://dict-co.iciba.com/api/dictionary.php?w="; public final static String iCiBaURL2="&key=你申请的APIkey,不要忘记了替换!!"; 注意! public static InputStream getInputStreamByUrl(String urlStr){ InputStream tempInput=null; URL url=null; HttpURLConnection connection=null; //设置超时时间 try{ url=new URL(urlStr); connection=(HttpURLConnection)url.openConnection(); //别忘了强制类型转换 connection.setConnectTimeout(8000); connection.setReadTimeout(10000); tempInput=connection.getInputStream(); }catch(Exception e){ e.printStackTrace(); } return tempInput; } }
这个类的功能就是根据给出的URL,从网络获得输入流,iCiBaURL1 和iCiBaURL2是用于构成查单词的URL的。iCiBaURL1+要查的单词+iCiBaURL2 就构成了金山查单词的URL
这里首先给出一个对象WordValue,该对象用来存放一个单词的信息:
public class WordValue { public String word=null,psE=null,pronE=null,psA=null,pronA=null, interpret=null,sentOrig=null,sentTrans=null; public WordValue(String word, String psE, String pronE, String psA, String pronA, String interpret, String sentOrig, String sentTrans) { super(); this.word = ""+word; this.psE = ""+psE; this.pronE = ""+pronE; this.psA = ""+psA; this.pronA = ""+pronA; this.interpret = ""+interpret; this.sentOrig = ""+sentOrig; this.sentTrans = ""+sentTrans; } public WordValue() { super(); this.word = ""; //防止空指针异常 this.psE = ""; this.pronE = ""; this.psA = ""; this.pronA = ""; this.interpret = ""; this.sentOrig = ""; this.sentTrans = ""; } public ArrayList<String> getOrigList(){ ArrayList<String> list=new ArrayList<String>(); BufferedReader br=new BufferedReader(new StringReader(this.sentOrig)); String str=null; try{ while((str=br.readLine())!=null){ list.add(str); } }catch(Exception e){ e.printStackTrace(); } return list; } public ArrayList<String> getTransList(){ ArrayList<String> list=new ArrayList<String>(); BufferedReader br=new BufferedReader(new StringReader(this.sentTrans)); String str=null; try{ while((str=br.readLine())!=null){ list.add(str); } }catch(Exception e){ e.printStackTrace(); } return list; } public String getWord() { return word; } public void setWord(String word) { this.word = word; } public String getPsE() { return psE; } public void setPsE(String psE) { this.psE = psE; } public String getPronE() { return pronE; } public void setPronE(String pronE) { this.pronE = pronE; } public String getPsA() { return psA; } public void setPsA(String psA) { this.psA = psA; } public String getPronA() { return pronA; } public void setPronA(String pronA) { this.pronA = pronA; } public String getInterpret() { return interpret; } public void setInterpret(String interpret) { this.interpret = interpret; } public String getSentOrig() { return sentOrig; } public void setSentOrig(String sentOrig) { this.sentOrig = sentOrig; } public String getSentTrans() { return sentTrans; } public void setSentTrans(String sentTrans) { this.sentTrans = sentTrans; } public void printInfo(){ System.out.println(this.word); System.out.println(this.psE); System.out.println(this.pronE); System.out.println(this.psA); System.out.println(this.pronA); System.out.println(this.interpret); System.out.println(this.sentOrig); System.out.println(this.sentTrans); } }
大家从成员变量的名字就可以看出,这个对象中的成员就对应从XML文件中解析出来的各个元素,大家可以在上面XML的介绍中找对应。
接下来是一个ContentHandler对象,用于对XML的解析:
public class JinShanContentHandler extends DefaultHandler{ public WordValue wordValue=null; private String tagName=null; private String interpret=""; //防止空指针异常 private String orig=""; private String trans=""; private boolean isChinese=false; public JinShanContentHandler(){ wordValue=new WordValue(); isChinese=false; } public WordValue getWordValue(){ return wordValue; } @Override public void characters(char[] ch, int start, int length) throws SAXException { // TODO Auto-generated method stub super.characters(ch, start, length); if(length<=0) return; for(int i=start; i<start+length; i++){ if(ch[i]=='\n') return; } //去除莫名其妙的换行! String str=new String(ch,start,length); if(tagName=="key"){ wordValue.setWord(str); }else if(tagName=="ps"){ if(wordValue.getPsE().length()<=0){ wordValue.setPsE(str); }else{ wordValue.setPsA(str); } }else if(tagName=="pron"){ if(wordValue.getPronE().length()<=0){ wordValue.setPronE(str); }else{ wordValue.setPronA(str); } }else if(tagName=="pos"){ isChinese=false; interpret=interpret+str+" "; }else if(tagName=="acceptation"){ interpret=interpret+str+"\n"; interpret=wordValue.getInterpret()+interpret; wordValue.setInterpret(interpret); interpret=""; //初始化操作,预防有多个释义 }else if(tagName=="orig"){ orig=wordValue.getSentOrig(); wordValue.setSentOrig(orig+str+"\n"); }else if(tagName=="trans"){ String temp=wordValue.getSentTrans()+str+"\n"; wordValue.setSentTrans(temp); }else if(tagName=="fy"){ isChinese=true; wordValue.setInterpret(str); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { // TODO Auto-generated method stub super.endElement(uri, localName, qName); tagName=null; } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { // TODO Auto-generated method stub super.startElement(uri, localName, qName, attributes); tagName=localName; } @Override public void endDocument() throws SAXException { // TODO Auto-generated method stub super.endDocument(); if(isChinese) return; String interpret=wordValue.getInterpret(); if(interpret!=null && interpret.length()>0){ char[] strArray=interpret.toCharArray(); wordValue.setInterpret(new String(strArray,0,interpret.length()-1)); //去掉解释的最后一个换行符 } } }
这里要注意的是:关于XML解析的基本知识我不想讲了,因为要讲这样细的话我三个月也完成不了这个系列。大家若有不懂的可以参考Mars 陈川老师的安卓开发视频教程,非常基础,入门必备。
关于XML解析基本就是用的他的的思路,但我想补充几点细节的东西:
1)不仅在startElement()之后会调用character()方法,在endElement()之后也会调用character90方法;
2)在具有多层的元素如上面的sent元素里面有嵌套了orig 和trans元素,此时character()方法并不会严格地在startElement之后就立即调用;
以上两点就会导致一个问题:会把多余的空行(换行符)也读取进来,所以我在程序中添加了清除换行的代码。请看注释。
3)这里也考虑了查英文的翻译结果是pos acception 而查中文的翻译结果是 fy ,可以看看上面ContentHandler中character()方法,这个方法是核心。
接下来就是一个XMLParser对象,该对象把XML解析用的SAXParserFactory等获取实例的工作封装起来,有了这个对象,解析XML时只需创建一个XMLParser对象,调用的该对象的parseJinShanXml()方法即可。
public class XMLParser { public SAXParserFactory factory=null; public XMLReader reader=null; public XMLParser(){ try { factory=SAXParserFactory.newInstance(); reader=factory.newSAXParser().getXMLReader(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } public void parseJinShanXml(DefaultHandler content, InputSource inSource){ if(inSource==null) return; try { reader.setContentHandler(content); reader.parse(inSource); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } public void parseDailySentenceXml(DailySentContentHandler contentHandler, InputSource inSource){ if(inSource==null) return; try { reader.setContentHandler(contentHandler); reader.parse(inSource); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
大家可以看到还有一个 parseDailySentenceXml()方法,这是解析每日一句的,暂时不用管它。
那么如何根据一个单词来获取它的XML并进行解析呢?即如何进行调用?方法如下:
public WordValue getWordFromInternet(String searchedWord){ WordValue wordValue=null; String tempWord=searchedWord; if(tempWord==null&& tempWord.equals("")) return null; char[] array=tempWord.toCharArray(); if(array[0]>256) //是中文,或其他语言的的简略判断 tempWord="_"+URLEncoder.encode(tempWord); InputStream in=null; String str=null; try{ String tempUrl=NetOperator.iCiBaURL1+tempWord+NetOperator.iCiBaURL2; in=NetOperator.getInputStreamByUrl(tempUrl); //从网络获得输入流 if(in!=null){ //new FileUtils().saveInputStreamToFile(in, "", "gfdgf.txt"); XMLParser xmlParser=new XMLParser(); InputStreamReader reader=new InputStreamReader(in,"utf-8"); //最终目的获得一个InputSource对象用于传入形参 JinShanContentHandler contentHandler=new JinShanContentHandler(); xmlParser.parseJinShanXml(contentHandler, new InputSource(reader)); wordValue=contentHandler.getWordValue(); wordValue.setWord(searchedWord); } }catch(Exception e){ e.printStackTrace(); } return wordValue; }
这是我从Dict类中截取的一个方法,注意这一个:tempWord="_"+URLEncoder.encode(tempWord); HttpURL中存在中文的话,会因为编码的问题产生乱码,所以先要对中文调用URLEncoder.encode()方法进行一下编码,这样才能得到正常的XML文件,这个问题当时困扰了我好久!
另外注意InputStream是二进制字节流,必须先经过InputStreamReader包装成字符流在创建InputSource对象,否则会出现编码异常,这个是我的一个经验。
调用这个方法就可以从网上获得要查询的单词的信息,并返回一个WordValue对象,然后我们再进行其它操作。
另外有一点必须强调:如果某个方法要访问网络,必须开辟一个子线程,在子线程里调用该方法!!!!!
今天就介绍到这里吧,这个项目要讲完还得不少时间,毕竟我写了三个星期。另外在在整个程序大体讲完之前我不打算共享源代码,希望大家能够体谅。写这个Blog的目的主要是分享一下经验和思路,而不是分享代码。