����������������������ָ����
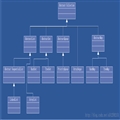
java�ļ��Ͽ����ȫ��⣨ͼ��
ǰ�ԣ����ݽṹ�Գ������������Զ��Ӱ�죬��������̵�C�����У����ݿ�ṹ��struct�������������������ı���У����ݽṹ�������������ģ����Ұ����жԸ����ݽṹ�����ķ�����
��Java�����У�Java���Ե�����߶Գ��õ����ݽṹ���㷨����һЩ�淶���ӿ�����ʵ�֣�����ʵ�ֽӿڵ��ࣩ�����г�����������ݽṹ�Ͳ������㷨��ͳ��ΪJava���Ͽ�ܣ�JavaCollectionFramework����
Java����Ա�ھ���Ӧ��ʱ�����ؿ������ݽṹ���㷨ʵ��ϸ�ڣ�ֻ��Ҫ����Щ�ഴ������һЩ����Ȼ��ֱ��Ӧ�þͿ����ˣ������ʹ������˱��Ч�ʡ�

?
1. ��˵Set��List:
1.1. Set�ӽӿ�:���������ظ���List�ӽӿ�:���������ظ�Ԫ�ء�����������
Set������Ԫ��Ч�ʵ��£�ɾ���Ͳ���Ч�ʸߣ������ɾ����������Ԫ��λ�øı䡣<��Ӧ���� HashSet,TreeSet>
List�����������ƣ�List���Զ�̬����������Ԫ��Ч�ʸߣ�����ɾ��Ԫ��Ч�ʵͣ���Ϊ����������Ԫ��λ�øı䡣<��Ӧ���� ArrayList,LinkedList��Vector>
Set��List�������ࣺ
2.2.?<ʵ���Ƚ�>
HashSet���Թ�ϣ������ʽ���Ԫ�أ�����ɾ���ٶȺܿ졣
ArrayList����̬���飬LinkedList����������������ջ��
Vector��һ���ϵĶ�̬���飬���߳�ͬ���ģ�Ч�ʺܵͣ�һ�㲻��ʹ��
1.Collection�ӿ�
Collection��������ļ��Ͻӿڣ�һ��Collection����һ��Object����Collection��Ԫ�أ�Elements����һЩ Collection������ͬ��Ԫ�ض���һЩ���С�һЩ���������һЩ���С�JavaSDK���ṩֱ�Ӽ̳���Collection���࣬JavaSDK�ṩ����Ǽ̳���Collection�ġ��ӽӿڡ���List��Set��
����ʵ��Collection�ӿڵ�������ṩ�����������캯���������Ĺ��캯�����ڴ���һ���յ�Collection����һ�� Collection�����Ĺ��캯�����ڴ���һ���µ�Collection������µ�Collection�봫���Collection����ͬ��Ԫ�ء���һ�����캯�������û�����һ��Collection��
��α���Collection�е�ÿһ��Ԫ�أ�����Collection��ʵ��������Σ�����֧��һ��iterator()�ķ������÷�������һ�������ӣ�ʹ�øõ����Ӽ�����һ����Collection��ÿһ��Ԫ�ء����͵��÷����£�
Iteratorit=collection.iterator();//���һ��������
while(it.hasNext()){
Objectobj=it.next();//�õ���һ��Ԫ��
}
��Collection�ӿ������������ӿ���List��Set��
2.List�ӿ�
List�������Collection��ʹ�ô˽ӿ��ܹ���ȷ�Ŀ���ÿ��Ԫ�ز����λ�á��û��ܹ�ʹ��������Ԫ����List�е�λ�ã������������±꣩������List�е�Ԫ�أ���������Java�����顣
������Ҫ�ᵽ��Set��ͬ��List��������ͬ��Ԫ�ء�
���˾���Collection�ӿڱر���iterator()�����⣬List���ṩһ��listIterator()����������һ�� ListIterator�ӿڣ��ͱ���Iterator�ӿ���ȣ�ListIterator����һЩadd()֮��ķ������������ӣ�ɾ�����趨Ԫ�أ�������ǰ����������
ʵ��List�ӿڵij�������LinkedList��ArrayList��Vector��Stack��
2.1.LinkedList��
LinkedListʵ����List�ӿڣ�����nullԪ�ء�����LinkedList�ṩ�����get��remove��insert������ LinkedList���ײ���β������Щ����ʹLinkedList�ɱ�������ջ��stack�������У�queue����˫����У�deque����
ע��LinkedListû��ͬ���������������߳�ͬʱ����һ��List��������Լ�ʵ�ַ���ͬ����һ������������ڴ���Listʱ����һ��ͬ����List��
Listlist=Collections.synchronizedList(newLinkedList(...));
2.2.ArrayList��
ArrayListʵ���˿ɱ��С�����顣����������Ԫ�أ�����null��ArrayListû��ͬ����
size��isEmpty��get��set��������ʱ��Ϊ����������add��������Ϊ��̯�ij���������n��Ԫ����ҪO(n)��ʱ�䡣�����ķ�������ʱ��Ϊ���ԡ�
ÿ��ArrayListʵ������һ��������Capacity���������ڴ洢Ԫ�ص�����Ĵ�С��������������Ų���������Ԫ�ض��Զ����ӣ����������㷨��û�ж��塣����Ҫ�������Ԫ��ʱ���ڲ���ǰ���Ե���ensureCapacity����������ArrayList����������߲���Ч�ʣ��Զ����жϳ��Ⱥ�����Ҳ���˷�ʱ���ѽ������
��LinkedListһ����ArrayListҲ�Ƿ�ͬ���ģ�unsynchronized��������չ�Ķ�����java.util.concurrent���ж����CopyOnWriteArrayList�ṩ���̰߳�ȫ��Arraylist�����ǵ�����add��set�ȱ仯����ʱ����ͨ��Ϊ�ײ����鴴���µĸ���ʵ�ֵģ����ԱȽϺķ���Դ
��Դ���ڴˣ�publicboolean?add(E e) {
finalReentrantLock?lock =this.lock;
lock.lock();
try?{
Object[] elements = getArray();
int?len = elements.length;
Object[] newElements = Arrays.copyOf(elements,len + 1);
newElements[len] = e;
setArray(newElements);
return?true;
}?finally?{
lock.unlock();
}
}����
�����������Ƶ�����������������ȱ仯��д����ģ��������ʱ�����ֱ�����������Լ����е�ͬ������Ч��Ҫ�ã�������Ҳ��������nullԪ�أ�
2.3.Vector��
Vector�dz�����ArrayList������Vector��ͬ���ġ���Vector������Iterator����Ȼ��ArrayList������ Iterator��ͬһ�ӿڣ����ǣ���ΪVector��ͬ���ģ���һ��Iterator�������������ڱ�ʹ�ã���һ���̸߳ı���Vector��״̬�����磬���ӻ�ɾ����һЩԪ�أ�����ʱ����Iterator�ķ���ʱ���׳�ConcurrentModificationException����˱��벶����쳣��ͨ��ʹ��capacity��ensurecapacity�����Լ�capacityIncrement������Ż��洢���������ǰ�潲������Vector��Iterator��listIterator��������ĵ�����֧��fail-fast���ƣ���������ʹ�õ������Ĺ������������߳�����map����ô���׳�ConcurrentModificationException���������νfail-fast���ԡ��ٷ��Դ˵�˵����?java.util?���е�������������?fail-fast������������ζ�����Ǽ����߳��ڼ��������н��е���ʱ�����ϲ�������������ݡ����?fail-fast���������ڵ��������н����˸��IJ�������ô�����׳�?ConcurrentModificationException�����Dz��ɿ��쳣����
2.4.Stack��
Stack�̳���Vector��ʵ��һ������ȳ��Ķ�ջ��Stack�ṩ5������ķ���ʹ��Vector���Ա�������ջʹ�á�������push��pop����������peek�����õ�ջ����Ԫ�أ�empty�������Զ�ջ�Ƿ�Ϊ�գ�search�������һ��Ԫ���ڶ�ջ�е�λ�á�Stack�մ������ǿ�ջ��
stack?�м����Ƚ�ʵ�õķ���
boolean
empty()?
���Զ�ջ�Ƿ�Ϊ�ա�
E
peek()?
�鿴��ջ�����Ķ������Ӷ�ջ���Ƴ�����
E
pop()?
�Ƴ���ջ�����Ķ�����Ϊ�˺�����ֵ���ظö���
E
push(Eitem)
����ѹ���ջ������
int
search(Objecto)
���ض����ڶ�ջ�е�λ�ã��� 1 Ϊ������
?
?
?
3.?set�ӿڣ�
Set������Collection��ȫһ���Ľӿڣ����û���κζ���Ĺ��ܣ�����ǰ����������ͬ��List��ʵ����Set����Collection,ֻ����Ϊ��ͬ��(���Ǽ̳����̬˼��ĵ���Ӧ�ã����ֲ�ͬ����Ϊ��)Set�������ظ���Ԫ��(��������ж�Ԫ����ͬ���Ϊ����)
Set : ����Set��ÿ��Ԫ�ض�������Ψһ�ģ���ΪSet�������ظ�Ԫ�ء�����Set��Ԫ�ر��붨��equals()������ȷ�������Ψһ�ԡ�Set��Collection����ȫһ���Ľӿڡ�Set�ӿڲ���֤ά��Ԫ�صĴ����ұ任��ɫ������������Ƶõ������ص㣩
HashSet : �������������ظ�Ԫ�أ�����֤����������Ԫ�ص�˳�����Լ������������Կ���������ֶ�˳����������IJ�һ������������ֵΪnull��Ԫ�أ������ֻ����һ��nullԪ�أ��������ظ������
?
TreeSet : ����ʵ������ȹ��ܵļ��ϣ����ڽ�����Ԫ�����ӵ�������ʱ���Զ�����ij�ֱȽϹ�������뵽����Ķ��������У�����֤�ü���Ԫ����ɰ��ա��������С�
a)���ڶԴ�����Ϣ���м�����ʱ��TreeSet��AraayList����Ч�ʣ��ܱ�֤��log(n)��ʱ������ɣ���
b)TreeSet��ʵ�����νṹ���洢��Ϣ�ģ�ÿ���ڵ㶼�ᱣ��һ��ָ����ֱ�ָ�ڵ㣬���֧���ҷ�֧����Ƚ϶��ԣ�ArrayList����һ������Ԫ�صļ������ˣ�����Ϊ��ˣ���ռ���ڴ�ҲҪ��ArrayList��һЩ��
c)��TreeSet����Ԫ��Ҳ��ArrayListҪ��һЩ����Ϊ��Ԫ�ز��뵽ArrayList������λ��ʱ��ƽ��ÿ��Ҫ�ƶ�һ����б�����ҪO(n)��ʱ�䣬 ��TreeSet��ȱ�����ѯ���ѵ�ʵʩֻ��ҪO(log(n))���ձ�Ķ��ǣ�set��ѯ��������죬list��ѯ�죬������, .TODO:��һ���һ�дһ���㷨�������¾������һ������
LinkedHashSet : ����HashSet�IJ�ѯ�ٶȣ����ڲ�ʹ������ά��Ԫ�ص�˳��(����Ĵ���)��������ʹ�õ���������Setʱ������ᰴԪ�ز���Ĵ�����ʾ��
?
?
PS:set�м����ȽϺ��ķ���:
removeAll(Collection<?> c)
�Ƴ� set ����Щ������ָ�� collection �е�Ԫ�أ���ѡ��������
boolean retainAll(Collection<?> c)
������ set ����Щ������ָ�� collection �е�Ԫ�أ���ѡ��������
containsAll(Collection<?> c)
����� set ����ָ�� collection ������Ԫ�أ��� true��
4.Queue���ݽṹ
�ⷽ��֪ʶ�漰���̱߳Ƚ϶࣬���̻߳����Ŀ���ο���ƪ����
http://blog.csdn.net/a512592151/article/details/38454745
5.Map�Ĺ��ܷ���
javaΪ���ݽṹ�е�ӳ�䶨����һ���ӿ�java.util.Map;�����ĸ�ʵ����,�ֱ���HashMap Hashtable LinkedHashMap?��TreeMap
Map��Ҫ���ڴ洢��ֵ�ԣ����ݼ��õ�ֵ����˲��������ظ�,������ֵ�ظ���
Hashmap ��һ�� ��õ�Map,�����ݼ���HashCode ֵ�洢����,���ݼ�����ֱ�ӻ�ȡ����ֵ�����кܿ�ķ����ٶȡ�HashMap���ֻ����һ����¼�ļ�ΪNull;����������¼��ֵΪ Null;HashMap��֧���̵߳�ͬ��������һʱ�̿����ж���߳�ͬʱдHashMap;���ܻᵼ�����ݵIJ�һ�¡������Ҫͬ���������� Collections��synchronizedMap����ʹHashMap����ͬ��������.
Hashtable ��HashMap����,��ͬ����:����������¼�ļ�����ֵΪ��;��֧���̵߳�ͬ��������һʱ��ֻ��һ���߳���дHashtable,���Ҳ������Hashtale��д��ʱ��Ƚ�����
LinkedHashMap�����˼�¼�IJ���˳������Iterator����LinkedHashMapʱ���ȵõ��ļ�¼�϶����Ȳ����.�ڱ��� ��ʱ����HashMap����
TreeMap�ܹ���������ļ�¼���ݼ�����,Ĭ���ǰ���������Ҳ����ָ������ıȽ���������Iterator ����TreeMapʱ���õ��ļ�¼���Ź���ġ�
?
class="java" name="code">package com.hxw.T2;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
public class MapTester {
public static void init(Map map) {
if (map != null) {
String key = null;
for (int i = 5; i > 0; i--) {
key = new Integer(i).toString() + ".0";
map.put(key, key.toString());
// Map�еļ��Dz��ظ��ģ��������������ֵһ���ļ�¼��
// ��ô�����ļ�¼�Ḳ���Ȳ���ļ�¼
map.put(key, key.toString() + "0");
}
}
}
public static void output(Map map) {
if (map != null) {
Object key = null;
Object value = null;
// ʹ�õ���������Map�ļ������ݼ�ȡֵ
Iterator it = map.keySet().iterator();
while (it.hasNext()) {
key = it.next();
value = map.get(key);
System.out.println("key: " + key + "; value: " + value);
}
// ����ʹ�õ���������Map�ļ�¼Map.Entry
Map.Entry entry = null;
it = map.entrySet().iterator();
while (it.hasNext()) {
// һ��Map.Entry����һ����¼
entry = (Map.Entry) it.next();
// ͨ��entry���Ի�ü�¼�ļ���ֵ
// System.out.println("key: " + entry.getKey() + "; value: " +
// entry.getValue());
}
}
}
public static boolean containsKey(Map map, Object key) {
if (map != null) {
return map.containsKey(key);
}
return false;
}
public static boolean containsValue(Map map, Object value) {
if (map != null) {
return map.containsValue(value);
}
return false;
}
public static void testHashMap() {
Map myMap = new HashMap();
init(myMap);
// HashMap�ļ�����Ϊnull
myMap.put(null, "ddd");
// HashMap��ֵ����Ϊnull
myMap.put("aaa", null);
output(myMap);
}
public static void testHashtable() {
Map myMap = new Hashtable();
init(myMap);
// Hashtable�ļ�����Ϊnull
// myMap.put(null,"ddd");
// Hashtable��ֵ����Ϊnull
// myMap.put("aaa", null);
output(myMap);
}
public static void testLinkedHashMap() {
Map myMap = new LinkedHashMap();
init(myMap);
// LinkedHashMap�ļ�����Ϊnull
myMap.put(null, "ddd");
// LinkedHashMap��ֵ����Ϊnull
myMap.put("aaa", null);
output(myMap);
}
public static void testTreeMap() {
Map myMap = new TreeMap();
init(myMap);
// TreeMap�ļ�����Ϊnull
// myMap.put(null,"ddd");
// TreeMap��ֵ����Ϊnull
// myMap.put("aaa", null);
output(myMap);
}
public static void main(String[] args) {
System.out.println("����HashMap");
MapTester.testHashMap();
System.out.println("����Hashtable");
MapTester.testHashtable();
System.out.println("����LinkedHashMap");
MapTester.testLinkedHashMap();
System.out.println("����TreeMap");
MapTester.testTreeMap();
Map myMap = new HashMap();
MapTester.init(myMap);
System.out.println("�³�ʼ��һ��Map: myMap");
MapTester.output(myMap);
// ���Map
myMap.clear();
System.out.println("��myMap clear��myMap����ô? " + myMap.isEmpty());
MapTester.output(myMap);
myMap.put("aaa", "aaaa");
myMap.put("bbb", "bbbb");
// �ж�Map�Ƿ����ij������ijֵ
System.out.println("myMap������aaa? "
+ MapTester.containsKey(myMap, "aaa"));
System.out.println("myMap����ֵaaaa? "
+ MapTester.containsValue(myMap, "aaaa"));
// ���ݼ�ɾ��Map�еļ�¼
myMap.remove("aaa");
System.out.println("ɾ����aaa��myMap������aaa? "
+ MapTester.containsKey(myMap, "aaa"));
// ��ȡMap�ļ�¼��
System.out.println("myMap�����ļ�¼��: " + myMap.size());
}
}
����map ���������ַ�����
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//��һ�֣��ձ�ʹ�ã�����ȡֵ
System.out.println("ͨ��Map.keySet����key��value��");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//�ڶ���
System.out.println("ͨ��Map.entrySetʹ��iterator����key��value��");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//�����֣��Ƽ���������������ʱ
System.out.println("ͨ��Map.entrySet����key��value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//������
System.out.println("ͨ��Map.values()�������е�value�������ܱ���key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
?
?
3����������
*List��Set��Map�����ж���һ����ΪObject�ͱ�
*Collection��List��Set��Map���ǽӿڣ�����ʵ������
�̳������ǵ� ArrayList, Vector, HashTable, HashMap�Ǿ���class����Щ�ſɱ�ʵ������
*vector����ȷ��֪���������еĶ�������ʲô�ͱ�vector�����б߽��顣
?
����Collections
Collections����Լ������һ�������ࡣ�ṩ��һϵ����̬����ʵ�ֶԸ��ּ��ϵ������������߳���ȫ���Ȳ�����
�൱�ڶ�Array�������Ʋ������ࡪ��Arrays��
�磬Collections.max(Collection coll); ȡcoll������Ԫ�ء�
Collections.sort(List list); ��list��Ԫ������
�ġ����ѡ��
1���������Array��������ȡ
* ��������ܳ��ж������ã�ָ������ָ�룩�������ǽ�������Ϣcopyһ��������ijλ�á�
* һ�����������������ڣ�����ʧ�˸ö�����ͱ���Ϣ��
2��
* �ڸ���Lists�У���õ���������ArrayList��Ϊȱʡѡ�������롢ɾ��Ƶ��ʱ��ʹ��LinkedList()��
Vector���DZ�ArrayList��������Ҫ��������ʹ�á�
* �ڸ���Sets�У�HashSetͨ������TreeSet�����롢���ң���ֻ�е���Ҫ����һ��������������У�����TreeSet��
TreeSet���ڵ�Ψһ���ɣ��ܹ�ά������Ԫ�ص�����״̬��
* �ڸ���Maps��
HashMap���ڿ��ٲ��ҡ�
* ��Ԫ�ظ����̶�����Array����ΪArrayЧ������ߵġ�
���ۣ���õ���ArrayList��HashSet��HashMap��Array�����ң�����Ҳ������һ�����ɣ���TreeXXX��������ġ�
?
ע�⣺
1��Collectionû��get()������ȡ��ij��Ԫ�ء�ֻ��ͨ��iterator()����Ԫ�ء�
2��Set��Collectionӵ��һģһ���Ľӿڡ�
3��List������ͨ��get()������һ��ȡ��һ��Ԫ�ء�ʹ��������ѡ��һ�Ѷ����е�һ����get(0)...��(add/get)
4��һ��ʹ��ArrayList����LinkedList�����ջstack������queue��
5��Map�� put(k,v) / get(k)��������ʹ��containsKey()/containsValue()����������Ƿ���ij��key/value��
HashMap�����ö����hashCode�������ҵ�key��
* hashing
��ϣ����ǽ��������Ϣ����һЩת���γ�һ����һ����intֵ�����ֵ�洢��һ��array�С�
���Ƕ�֪�����д洢�ṹ�У�array�����ٶ������ġ����ԣ����Լ��ٲ��ҡ�
?
������ײʱ����arrayָ����values����������ÿ��λ����������һ��������
6��Map��Ԫ�أ����Խ�key���С�value���е�����ȡ������
ʹ��keySet()��ȡkey���У���map�е�����keys����һ��Set��
ʹ��values()��ȡvalue���У���map�е�����values����һ��Collection��
Ϊʲôһ������Set��һ������Collection��������Ϊ��key���Ƕ�һ���ģ�value�����ظ���
?