一:面向对象设计中最简单的部分与最难的部分
如果说事务脚本是 面向过程 的,那么领域模型就是 面向对象 的。面向对象的一个很重要的点就是:“把事情交给最适合的类去做”,即:“你得在一个个领域类之间跳转,才能找出他们如何交互”,Martin Flower 说这是面向对象中最难的部分,这具有误导的成份。确切地说,我们作为程序员如果已经掌握了 OOD 和 OOP 中技术手段,那么如何寻找类之间的关系,可能就成了最难的部分。但在实际的情况中,即便我们不是程序员,也总能描述一件事情(即寻求关系),所以,找 对象之间的关系 还真的并不是程序员最关系的部分,从技术层面来讲,寻找类之间的关系因为与具体的编码技巧无关,所以它现在对于程序员的我们来说,应该是最简单的部分,技术手段才是这里面的最难部分。
好,切入正题。
二:构筑类之间的关系(最简单部分)
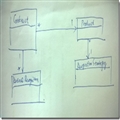
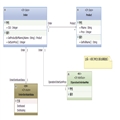
先来完成最简单的部分,即找关系。也就是说,按照所谓的关系,我们来重构 事务脚本 中的代码。上篇“你在用什么思想编码:事务脚本 OR 面向对象?”中同样的需求,如果用领域模式来做的话,我们大概可以这样设计:

(备注:Product 和 RecognitionStrategy 为 * –> 1 的关系是因为 一种确认算法可以被多个产品的实例对象使用)
从下面的示例代码我们就可以看到这点:
class RevenueRecognition
{
private double amount;
private DateTime recognizedOn;
public RevenueRecognition(double amount, DateTime recognizedOn)
{
this.amount = amount;
this.recognizedOn = recognizedOn;
}
public double GetAmount()
{
return this.amount;
}
public bool IsRecognizedBy(DateTime asOf)
{
return asOf.CompareTo(this.recognizedOn) > 0 || asOf.CompareTo(this.recognizedOn) == 0;
}
}class Contract
{
// 多 对 1 的关系,* -> 1。即:一个产品可有多个合同订单
private Product product;
private long id;
// 合同金额
private double revenue;
private DateTime whenSigned;
// 1 对 多 的关系, 1 -> *
private List<RevenueRecognition> revenueRecognitions = new List<RevenueRecognition>();
public Contract(Product product, double revenue, DateTime whenSigned)
{
this.product = product;
this.revenue = revenue;
this.whenSigned = whenSigned;
}
public void AddRevenueRecognition(RevenueRecognition r)
{
revenueRecognitions.Add(r);
}
public double GetRevenue()
{
return this.revenue;
}
public DateTime GetWhenSigned()
{
return this.whenSigned;
}
// 得到哪天前入账了多少
public double RecognizedRevenue(DateTime asOf)
{
double re = 0.0;
foreach(var r in revenueRecognitions)
{
if(r.IsRecognizedBy(asOf))
{
re += r.GetAmount();
}
}
return re;
}
public void CalculateRecognitions()
{
product.CalculateRevenueRecognitions(this);
}
}class Product
{
private string name;
private RecognitionStrategy recognitionStrategy;
public Product(string name, RecognitionStrategy recognitionStrategy)
{
this.name = name;
this.recognitionStrategy = recognitionStrategy;
}
public void CalculateRevenueRecognitions(Contract contract)
{
recognitionStrategy.CalculateRevenueRecognitions(contract);
}
public static Product NewWordProcessor(string name)
{
return new Product(name, new CompleteRecognitionStrategy());
}
public static Product NewSpreadsheet(string name)
{
return new Product(name, new ThreeWayRecognitionStrategy(60, 90));
}
public static Product NewDatabase(string name)
{
return new Product(name, new ThreeWayRecognitionStrategy(30, 60));
}
}abstract class RecognitionStrategy
{
public abstract void CalculateRevenueRecognitions(Contract contract);
}class CompleteRecognitionStrategy : RecognitionStrategy
{
public override void CalculateRevenueRecognitions(Contract contract)
{
contract.AddRevenueRecognition(new RevenueRecognition(contract.GetRevenue(), contract.GetWhenSigned()));
}
}class ThreeWayRecognitionStrategy : RecognitionStrategy
{
private int firstRecognitionOffset;
private int secondRecognitionOffset;
public ThreeWayRecognitionStrategy(int firstRoff, int secondRoff)
{
this.firstRecognitionOffset = firstRoff;
this.secondRecognitionOffset = secondRoff;
}
public override void CalculateRevenueRecognitions(Contract contract)
{
contract.AddRevenueRecognition(
new RevenueRecognition(contract.GetRevenue() / 3, contract.GetWhenSigned()));
contract.AddRevenueRecognition(
new RevenueRecognition(contract.GetRevenue() / 3, contract.GetWhenSigned().AddDays(firstRecognitionOffset)));
contract.AddRevenueRecognition(
new RevenueRecognition(contract.GetRevenue() / 3, contract.GetWhenSigned().AddDays(secondRecognitionOffset)));
}
}
正像我说的,以上的代码是最简单部分,每个 OOP 的初学者都能写出这样的代码来。但是我心想,即便我们能写出这样的代码来,我们恐怕都不会心虚的告诉自己:是的,我正在进行领域驱动开发吧。
那么,真正难的部分是什么?
2.1 领域模型 对于程序员来说真正困难或者困惑的部分
是领域模型本身怎么和其它模块(或者其它层)进行交互,这些交互或者说关系是:
1:领域模型 自身具备些什么语言层面的特性;
2:领域模型 和 领域模型 之间的关系;
3:领域模型 和 Repository 的关系;
4:工作单元 和 领域模型 及 Repository 的关系;
5:领域模型 的缓存;
6:领域模型 和 会话之间的关系;
三:那些交互与关系
3.1 领域模型 自身具备些什么语言层面的特性
先看代码:
public class User2 : DomainObj
{
#region Field
#endregion#region Property
#endregion
#region 领域自身逻辑
#endregion
#region 领域服务
#endregion
}
对于一个领域模型来说,从语言层面来讲,它具备 5 方面的特性:
1:有父类,放置公共的属性之类的内容,同时,存在一个父类,也表示它不是一个 值对象(领域概念中的值对象);
2:有实例字段;
3:有实例属性;
4:领域自身逻辑,非 static 方法,有 public 的和 非public;
5:领域服务,static 方法,可独立出去放置到对应的 服务类 中;
现在,我们具体展开一下。不过,为了展开讲,我们必须提供一个稍稍完整的 User2 的例子,它在真正的项目是这个样子的:
public class User2 : DomainObj
{
#region Field
private Organization2 organization;private List<YhbjTest> myTests;
private List<YhbjClass> myClasses;
#endregion
#region Property
public override IRepository RootRep
{
get { return RepRegistory.UserRepository; }
}public string UserName { get; private set; }
public string Password { get; private set; }
/* 演示了同时存在 Organization 和 OrganizationId 两个属性的情况 */
public string OrganizationId { get; private set; }public Organization2 Organization
{
get
{
if (organization == null && !string.IsNullOrEmpty(OrganizationId))
{
organization = Organization2.FindById(OrganizationId);
}return organization;
}
}/* 演示了存在 列表 属性的情况 */
public List<YhbjClass> MyClasses
{
get
{
if (myClasses == null)
{
myClasses = YhbjClass.GetClassesByUserId(this);
}return myClasses;
}
}public List<YhbjTest> MyTests
{
get
{
/* 我的考试来自两个地方,1:班级、项目上的考试;2:选人的考试;
* 故,有两种设计方法
* 1:选人的考试没有疑议;
* 2:班级、项目考试,可以从本模型的 Classes -> Projects -> Tests 获取;
* 3:也可以直接从数据库得到获取;
* 在这里的实际实现,采用第 2 种做法。因为:
* 1:数据本身是缓存的,第一获取的时候,貌似存在多次查询,但是一旦获取就缓存了;
* 2:存在很多地方的数据一致性问题,采用方法 3 貌似快速了,但会带来不可知 BUG ;
* 3:即便将来考试还有课程上的考试,可以很方便的获取,不然还需要重改 SQL;
*/
if (myTests == null)
{
myTests = new List<YhbjTest>();/* 加指定人的考试,这些考试没有对应的 项目 和 班级*/
myTests.AddRange(YhbjTest.GetTestsByUserId(this.Id));/* 加班级的考试,有对应的 班级 */
foreach (var c in MyClasses)
{
myTests.AddRange(c.Tests);
foreach (var t in c.Tests)
{
t.SetOwnerClass(c);
}/* 加项目的考试,有对应的 班级 和 项目,代码略 */
}
}/* 其它逻辑 */
foreach (var test in myTests)
{
if (test.TestHistory == null)
{
test.SetHistory(MyTestHistories
.FirstOrDefault(p => p.TestId == test.Id && p.UserId == this.Id));
}
}return myTests;
}
}
#endregion#region 领域自身逻辑
public void InitWithOrganization(Organization2 o)
{
/* 在这个方法中不用 MakeDirty,因为相当于初始化分为两步进行了
*/
this.organization = o;
}
/* 不需要对外开放的逻辑,使用 internal*/
internal virtual void UpdateOnline(string loginTime, string token, string loginIp, string loginPort)
{
/* 这样做的好处是什么呢?
* createnew 方法用户不负责自己的持久化,而是由事务代码进行负责
* 但是 createnew 方法会标识自己为 new,即 makenew 方法调用
* 然后,由于 ut 用的都是同一个 ut,所以在事务这里 commit 了
* 就是 commit 了 根 和 非根
* 这里也同时演示了多个领域对象共用一个 ut
*/
this.UnitOfWork = new UnitOfWork();
UserOnline2 userOnline2Old = UserOnline2.GetUserOnline(this.UserName);
if (userOnline2Old != null)
{
userOnline2Old.UnitOfWork = this.UnitOfWork;
userOnline2Old.Delete();
}UserOnline2 = UserOnline2.CreateNew(UserName, loginIp, loginPort);
UnitOfWork.RegisterNew(UserOnline2);
UnitOfWork.Commit();
}/* 对外开放的逻辑,使用 public */
public List<YhbjTest> GetMyTest(string testName, int type, int page, int size, out int totalCount)
{
IEnumerable<YhbjTest> expName = from p in MyTests orderby p.CreateTime descending select p;
IEnumerable<YhbjTest> expState = null;switch (type)
{
case 0:
/* 未考
* 需要排除掉 有效期 之外
*/
expState =
from p in expName
where
p.StartTime <= DateTime.Now &&
p.EndTime >= DateTime.Now &&
(this.MyTestHistories.Exists(q => q.TestId == p.Id) == false
|| (this.MyTestHistories.Exists(q => q.TestId == p.Id) == true && this.myTestHistories.Find(h => h.TestId == p.Id).TestState != 1)) &&
p.AuditState == AuditState.Audited
select p;
break;
default:
throw new ArgumentOutOfRangeException();
}var re = expState.ToList();
totalCount = re.Count;
return re.Skip((page - 1) * size).Take(size).ToList();
}public YhbjTest StartTest(string testId)
{
// 逻辑略
}#endregion
/// <summary>
/// 1:服务是无状态的,所以是 static 的
/// 2:服务是公开的,所以是 public 的
/// 3:服务实际是可以创建专门的服务类的,这里为了演示需要,就放在一起了
/// </summary>
#region 领域服务/* 这两个字段演示其实服务部分的代码是随意的 */
private static readonly CookieWrapper CookieWrapper;private static readonly HttpWrapper HttpWrapper;
static User2()
{CookieWrapper = new CookieWrapper();
HttpWrapper = new HttpWrapper();
}/* 内部的方法当然是私有的 */
private static List<PaperQuestionStrategy3> GetUserPaperByUserAndTest(User2 user2, YhbjTest test)
{
var x = RepRegistory.UserRepository.FindTestUserPaper(user2, test);
return x;
}/* 获取领域对象的方法,全部属于领域服务部分,再次强调是静态的 */
public static User2 GetUserByName(string username)
{
var user = (RepRegistory.UserRepository).FindByName(username);
return user as User2;
}
/* 领域对象的获取和产生,还有另外的做法,就是在对象工厂中生成,但这不属于本文要阐述的范畴 */
public static User2 CreateCreater(
string creatorOrganizationId, string creatorOrganizationName, string id, string name)
{
var user = new User2 { Id = id, Name = name, UnitOfWork = new UnitOfWork() };
user.MakeNew();
return user;
}
#endregion
}
请仔细查看上面代码,为了本文接下来的阐述,上面的代码几乎都是有意义的,我已经很精简了。好了,基于上面这个例子,我们展开讲:
1:父类
public abstract class DomainObj
{
public Key Key { get; set; }/// <summary>
/// 根仓储
/// TIP: 因为是充血模式,所以每个领域模型都有一个根仓储
/// 用于提交自身的变动
/// </summary>
public abstract IRepository RootRep { get; }protected DomainObj()
{
}public UnitOfWork UnitOfWork { get; set; }
public string Id { get; protected set; }
public string Name { get; protected set; }
protected void MakeNew()
{
UnitOfWork.RegisterNew(this);
}protected void MakeDirty()
{
UnitOfWork.RegisterDirty(this);
}protected void MakeRemoved()
{
UnitOfWork.RegisterRemoved(this);
}}
父类包含了,让一个 领域模型 成为 领域模型 所必备的那些特点,它有 标识映射(架构模式对象与关系结构模式之:标识域(Identity Field)),它持有 工作单元(),它负责调用 工作单元的API(换个角度说工作单元(Unit Of Work):创建、持有与API调用)。
如果我们的对象是一个 领域模型对象,那么它必定需要继承之这个父类;
2:有实例字段
有人可能会有疑问,不是有属性就可以了吗,为什么要有字段,一个理由是,如果我们需要 延迟加载(),就需要使用字段来进行辅助。我们在上面的源码中看到的 if XX == NULL ,这样的属性代码,就是延迟加载,其中使用到了字段。注意,如果使用了延迟加载,你应该会遇到序列化的问题,这是你需要注意的《延迟加载与序列化》。
3:有实例属性
属性是必然的,没有属性的领域模型很稀少的。有几个地方需要大家注意,
1:属性的 get 方法,可以是很复杂的,其地位相当于是领域自身逻辑;
2:set 方法,都是 private 的,领域对象自身负责自身属性的赋值;
3:在有必要的情况下,使用 延迟加载,这可能需要另外一个主题来讲;
4:延迟加载的那些属性,很多时候就是 导航属性,即 Organization 和 MyClasses 这样的属性,就是导航属性;
4:领域自身逻辑
领域自身逻辑,包含了应用系统大多数的业务逻辑,可以理解为:它就是传统 3 层架构中的业务逻辑层的代码。如果一段代码,你不知道把它放到哪里,那么,它多半就属于应该放在这里。注意,只有应该公开的那些方法,才 public;
5:领域服务
领域服务,可以独立出去,成为领域服务类。那么,什么样的代码是领域服务代码?第一种情况:
生成领域对象实例的方法,都应该是领域服务类。如 查询 或者 Create New。
在实际场景中,我们可能使用对象工厂来生成它们,这里为了纯粹的演示哪些是 领域自身逻辑,哪些是 领域服务,特意使用了领域类的 static 方法来生成领域对象。即:
领域对象,不能随便被外界生成,要严格控制其生成。所以领域父类的构造器,我们看到是 protected 的。
那么,实际上,除了上面这种情况外,任何代码都应该是 领域自身逻辑的。我在上面还演示了这样的一段代码:
private static List<PaperQuestionStrategy3> GetUserPaperByUserAndTest(User2 user2, YhbjTest test)
{
var x = RepRegistory.UserRepository.FindTestUserPaper(user2, test);
return x;
}
这段代码,实际上作为领域服务部分,就是错误的,它应该被放置在 YhbjTest 这个领域类中。
3.2 领域模型 和 领域模型 之间的关系
也就是说那些导航属性和领域模型有什么关系。导航属性必须都是延迟加载的吗?当然不是。比如, User 所在的 Organization,我们在在使用到用户这个对象的时候,几乎总是要使用到其组织信息,那么,我们在获取用户的时候,就应该立即获取到组织对象,那么,我们的持久化代码是这样的:
public override DomainObj Find(Key key)
{
var user = base.Find(key) as User2;
if (user == null)
{
//
string sql = @"
DECLARE @ORGID VARCHAR(32)='';
SELECT @ORGID=OrganizationId FROM [EL_Organization].[USER] WHERE ID=@Id
SELECT * FROM [EL_Organization].[USER] WHERE ID=@Id
SELECT * FROM [EL_Organization].[ORGANIZATION] WHERE ID=@ORGID";
var pms = new SqlParameter[]
{
new SqlParameter("@Id", key.GetId())
};var ds = SqlHelper.ExecuteDataset(CommandType.Text, sql, pms);
user = DataTableHelper.ToList<User2>(ds.Tables[0]).FirstOrDefault();
var o = DataTableHelper.ToList<Organization2>(ds.Tables[1]).FirstOrDefault();
if (user == null)
{
return null;
}user = Load(user);
// 注意,除了 Load User 还需要 Load Organization
user.InitWithOrganization(o);
Load(user.Organization);return user;
}return user;
}
可以看到,我们在一次 sql 执行的时候,就得到了 organization,然后,User2 类型中,有个属于领域自身逻辑方法:
public void InitWithOrganization(Organization2 o)
{
/* 在这个方法中不用 MakeDirty,因为相当于初始化分为两步进行了
*/
this.organization = o;
}
在这里要多说一下,如果不是初始化时候的改属性,如修改了用户的组织信息,就应该 MakeDirty。
注意,还有一个比较重要的领域自身逻辑,就是 SetOwned,如下:
public void SetOwnerClass(YhbjClass yhbjClass)
{
this.OwnerClass = yhbjClass;
/* should not makeDirty, but if class repalced or removed, should makedirty*/
}
比如,领域模型 考试,就可能会有这个方法,考试本身需要知道:我属于哪个班级。
3.3 领域模型 和 Repository 之间的关系
第一,如果我们在使用 领域模型,我们必须使用 Repository 模式吗?答案是:当然不是,我们可以使用 活动记录模式(什么是活动记录,当前我们可以暂时理解为传统3层架构中的DAL层)。如果我们在使用 Repository ,那么,领域模型和 Respository 之间是什么关系呢?这里,有两点需要阐述:
第一点是,一般的做法,Repository 是被注入的,它可能被注入到系统的某个地方,示例代码是被注入到了类型 RepRegistory中。
领域模型要不要使用 Repository,我的答案是:要。
为什么,因为我们要让领域逻辑自己决定合适调用 Repository。
第二点是,每个领域模型都有一个 RootRep,用于自身以及把自身当成根的那些导航属性对象的持久化操作;
3.4 工作单元 和 领域模型 及 Repository 的关系
这一点比较复杂,我们单独在 《换个角度说工作单元(Unit Of Work):创建、持有与API调用》 进行了阐述。当然,跟 Repository 一样,使用 领域模型,必须使用 工作单元 吗?答案也是不是。只是,在使用 工作单元 后,更易于我们处理 领域模型 中的事务问题。
3.5 领域模型的缓存
缓存分为两类,第一类我们可以称之为 一级缓存,这对于客户端程序员来说,不可见,它被放置在 AbstractRepository 中,往往在当前请求中有用:
public abstract class AbstractRepository : IRepository
{
/* LoadedDomains 在有些文献中可以作为高速缓存,但是这个缓存可不是指的
* 业务上的那个缓存,而是 片段 的缓存,指在当前实例的生命周期中的缓存。
* 业务上的缓存在我们的系统中,由每个领域模型的服务部分自身持有。
*/
protected Dictionary<Key, DomainObj> LoadedDomains =
new Dictionary<Key, DomainObj>();public virtual DomainObj Find(Key key)
{
if (LoadedDomains.ContainsKey(key))
{
return LoadedDomains[key] as DomainObj;
}
else
{
return null;
}//return null;
}public abstract void Insert(DomainObj t);
public abstract void Update(DomainObj t);
public abstract void Delete(DomainObj t);
public void CheckLoaedDomains()
{
foreach (var m in LoadedDomains)
{
Console.WriteLine(m.Value);
}
}
/// <summary>
/// 当缓存内容发生变动时进行重置
/// </summary>
/// <param name="keyField">缓存key的id</param>
/// <param name="type">缓存的对象类型</param>
public void ResetLoadedDomainByKey(string keyId,Type type)
{
var key=new Key(keyId,type);
if (LoadedDomains.ContainsKey(key))
{
LoadedDomains.Remove(key);
}
}protected T Load<T>(T t) where T : DomainObj
{
var key = new Key(t.Id, typeof (T));
/* 1:这一句很重要,因为我们不会想要放到每个子类里去赋值
* 2:其次,如果子类没有调用 Load ,则永远没有 Key,不过这说得过去
*/
t.Key = key;if (LoadedDomains.ContainsKey(key))
{
return LoadedDomains[key] as T;
}
else
{
LoadedDomains.Add(key, t);
return t;
}//return t;
}protected List<T> LoadAll<T>(List<T> ts) where T : DomainObj
{
for (int i = 0; i < ts.Count; i++)
{
ts[i] = Load(ts[i]);
}return ts;
}
}
业务系统中的缓存,需要我们随着业务系统自身的特点,自己来创建,比如,如果我们针对 User2 这个领域模型建立缓存,就应该把这个缓存挂接到当前会话中。此处不表。
3.6 领域模型 与 会话之间的关系
这是一个有意思的话题,无论是理论上还是实际中,在一次会话当中(如果我们会话的参照中,可以回味下 ASP.NET 中的 Session,它们所表达的概念是一致的),只要会话不失效,那么 领域对象 的状态,就应该是被保持的。这里难的是,我们怎么来创建这个 Session。Session 回到语言层面,就是一个类,它可能会将领域对象保持在 内存中,或者文件中,或者数据库中,或者在一个分布式系统中(如 Memcached,《ASP.NET性能优化之分布式Session》)。
最简单的,我们可以使用 ASP.NET 的 Session 来保存我们的会话,然后把领域对象存储到这里。
四:总结
以上描述了让领域模型成为领域模型的一些最基本的技术手段。解决了这些技术手段,我们的开发才基本算是 DDD 的,才是面向领域模型的。解决了这些技术问题,接下来,我们才能毫无后顾之忧地去解决 Martin Flower 所说的最难的部分:“你得在一个个领域类之间跳转,才能找出他们如何交互”。