����Kafka �Ƿֲ�ʽ����-������Ϣϵͳ��������� LinkedIn ��˾������֮���Ϊ Apache ��Ŀ��һ���֡�Kafka ��һ���ֲ�ʽ�ģ��ɻ��ֵģ����౸�ݵij־��Ե���־��������Ҫ���ڴ�����Ծ����ʽ���ݡ�
�����ڴ�����ϵͳ�У�����������һ�����⣬�������������ɸ�����ϵͳ��ɣ�������Ҫ�ڸ�����ϵͳ�и����ܣ����ӳٵIJ�ͣ��ת����ͳ����ҵ��Ϣϵͳ�����Ƿdz��ʺϴ��ģ�����ݴ�����Ϊ������ͬʱ�㶨����Ӧ�ã���Ϣ��������Ӧ�ã������ļ�����־��Kafka �ͳ����ˡ�Kafka �������������ã�
����Kafka ��Ҫ�ص㣺
����Kayka ���ܹ���
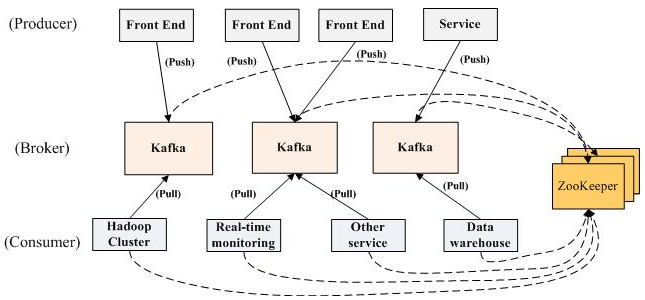
����Kayka ������ܹ��dz�������ʽ�ֲ�ʽ�ܹ���producer��broker��kafka���� consumer �������ж����Producer��consumer ʵ�� Kafka ע��Ľӿڣ����ݴ� producer ���͵� broker��broker �е�һ���м仺��ͷַ������á�broker �ַ�ע�ᵽϵͳ�е� consumer��broker �����������ڻ��棬����Ծ�����ݺ����ߴ���ϵͳ֮��Ļ��档�ͻ��˺ͷ������˵�ͨ�ţ��ǻ��ڼ������ܣ�������������ص� TCP Э������������������
������Ϣ���������̣�
����Kayka ����ƣ�
����1��������
������������ kafka ��Ҫʵ�ֵĺ���Ŀ��֮һ��Ϊ�� kafka ��������һЩ��ƣ�
�������ؾ���
������ȡϵͳ
�������� kafka broker ��־û����ݣ�broker û���ڴ�ѹ������ˣ�consumer �dz��ʺϲ�ȡ pull �ķ�ʽ�������ݣ��������¼���ô���
��������չ��
��������Ҫ���� broker ���ʱ�������� broker ���� zookeeper ע�ᣬ�� producer �� consumer �����ע���� zookeeper �ϵ� watcher ��֪��Щ�仯������ʱ����������
����Kayka ��Ӧ�ó�����
����1. ��Ϣ����
����������������Ϣϵͳ��˵��Kafka �и��õ������������õķ��������༰�ݴ��ԣ����� Kafka ��Ϊ��һ���ܺõĴ��ģ��Ϣ����Ӧ�õĽ����������Ϣϵͳһ����������Խϵͣ�������Ҫ��С�Ķ˵�����ʱ�������������� Kafka �ṩ��ǿ��ij־��Ա��ϡ����������Kafka ����������ͳ��Ϣϵͳ���� ActiveMR �� RabbitMQ��
����2. ������
����Kafka ����һ��Ӧ�ó����Ǹ����û����ҳ�桢������������Ϊ���Է���-���ĵ�ģʽʵʱ��¼����Ӧ�� topic ���ô��Щ������������õ��Ϳ�������һ����ʵʱ��������ʵʱ��أ���ŵ� hadoop/����cangku.html" target="_blank">���ݲֿ��ﴦ����
����3. Ԫ��Ϣ���
������Ϊ������¼�ļ��ģ����ʹ�ã����㼯��¼һЩ������Ϣ����������Ϊ��ά���ʵ����ݼ�ذɡ�
����4. ��־�ռ�
������־�ռ����棬��ʵ��Դ��Ʒ�кܶ࣬���� Scribe��Apache Flume���ܶ���ʹ�� Kafka ������־�ۺϣ�log aggregation������־�ۺ�һ����˵�Ǵӷ��������ռ���־�ļ���Ȼ��ŵ�һ�����е�λ�ã��ļ��������� HDFS�����д�����Ȼ�� Kafka ���Ե��ļ���ϸ�ڣ�����������س����һ������־���¼�����Ϣ��������� Kafka ���������ӳٸ��ͣ�������֧�ֶ�����Դ�ͷֲ�ʽ���ݴ�������������־Ϊ���ĵ�ϵͳ���� Scribe ���� Flume ��˵��Kafka �ṩͬ����Ч�����ܺ���Ϊ���Ƶ��µĸ��ߵ������Ա�֤���Լ����͵Ķ˵����ӳ١�
����5. ������
��������������ܱȽ϶࣬Ҳ�ܺ����⡣�����ռ������ݣ����ṩ֮��Խӵ� Storm ��������ʽ�����ܽ��д������ܶ��û��Ὣ��Щ��ԭʼ topic �������ݽ��н��Դ��������ܣ���������������ķ�ʽת�����µ� topic ���ټ�������Ĵ���������һ�������Ƽ��Ĵ������̣��������ȴ� RSS ����Դ��ץȡ���µ����ݣ�Ȼ���䶪��һ������“����”�� topic �У�����������������Ҫ��������ݽ�������������ظ��������ݻ���ɾ���ظ����ݣ�����ٽ�����ƥ��Ľ���������û��������һ�������� topic ֮�⣬������һϵ�е�ʵʱ���ݴ��������̡�Strom �� Samza �Ƿdz�������ʵ��������������ת���Ŀ�ܡ�
����6. �¼�Դ
�����¼�Դ��һ��Ӧ�ó�����Ƶķ�ʽ���÷�ʽ��״̬ת�Ʊ���¼Ϊ��ʱ��˳������ļ�¼���С�Kafka ���Դ洢��������־���ݣ���ʹ������Ϊһ�������ַ�ʽ��Ӧ����˵���ѵĺ�̨�����綯̬���ܣ�News feed����
����7. �־�����־��commit log��
����Kafka ����Ϊһ���ⲿ�ij־�����־�ķֲ�ʽϵͳ�ṩ����������־�����ڽڵ�䱸�����ݣ���Ϊ���Ͻڵ����ݻظ��ṩһ������ͬ���Ļ��ơ�Kafka ����־ѹ������Ϊ�����÷��ṩ���������������÷��У�Kafka ������ Apache BookKeeper ��Ŀ��
����Kayka �����Ҫ�㣺
����1��ֱ��ʹ�� linux �ļ�ϵͳ�� cache������Ч�������ݡ�
����2������ linux Zero-Copy ��߷������ܡ���ͳ�����ݷ�����Ҫ���� 4 ���������л������� sendfile ϵͳ����֮������ֱ�����ں�̬������ϵͳ�������л�����Ϊ 2 �Ρ����ݲ��Խ����������� 60% �����ݷ������ܡ�Zero-Copy ��ϸ�ļ���ϸ�ڿ��Բο���https://www.ibm.com/developerworks/linux/library/j-zerocopy/
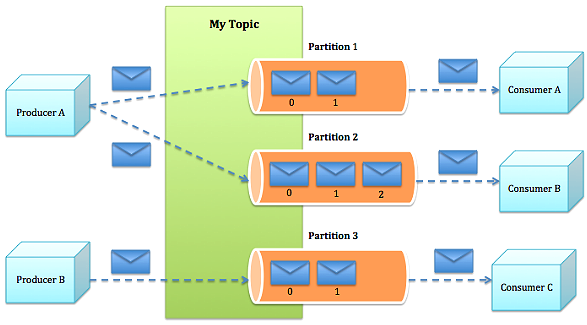
����3�������ڴ����ϴ�ȡ����ΪO(1)��kafka �� topic ��������Ϣ������ÿ�� topic ������� part��ition����ÿ�� part ��Ӧһ���� log���ж�� segment ��ɡ�ÿ�� segment �д洢������Ϣ������ͼ������Ϣ id ������λ�þ�����������Ϣ id ��ֱ�Ӷ�λ����Ϣ�Ĵ洢λ�ã����� id ��λ�õĶ���ӳ�䡣ÿ�� part ���ڴ��ж�Ӧһ�� index����¼ÿ�� segment �еĵ�һ����Ϣƫ�ơ������߷���ij�� topic ����Ϣ�ᱻ���ȵķֲ������ part �ϣ����������û�ָ���Ļص��������зֲ�����broker �յ�������Ϣ����Ӧ part �����һ�� segment �����Ӹ���Ϣ����ij�� segment �ϵ���Ϣ�����ﵽ����ֵ����Ϣ����ʱ�䳬����ֵʱ��segment �ϵ���Ϣ�ᱻ flush �����̣�ֻ�� flush �������ϵ���Ϣ�����߲��ܶ��ĵ���segment �ﵽһ���Ĵ�С���������� segment д���ݣ�broker �ᴴ���µ� segment��
����4����ʽ�ֲ�ʽ�������е� producer��broker �� consumer �����ж������Ϊ�ֲ�ʽ�ġ�Producer �� broker ֮��û�и��ؾ�����ơ�broker �� consumer ֮������ zookeeper ���и��ؾ��⡣���� broker �� consumer ������ zookeeper �н���ע�ᣬ�� zookeeper �ᱣ��������һЩԪ������Ϣ�����ij�� broker �� consumer �����˱仯������������ broker �� consumer ����õ�֪ͨ��
�����ο����ϣ�


