一致性哈希算法的Java实现
?
关于一致性哈希算法的原理,网上有很多介绍,在此只是简单介绍一下,不做详细说明。
?
一致性哈希算法是分布式系统中常用的算法,比如有N台缓存服务器,你需要将数据缓存到这N台服务器上。一致性哈希算法可以将数据尽可能平均的存储到N台缓存服务器上,提高系统的负载均衡,并且当有缓存服务器加入或退出集群时,尽可能少的影响现有缓存服务器的命中率,减少数据对后台服务的大量冲击。
?
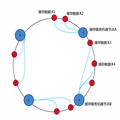
一致性哈希算法的基本原理,把数据通过hash函数映射到一个很大的环形空间里,如下图所示:

?
?
?
A、B、C、D 4台缓存服务器通过hash函数映射环形空间上,数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如缓存数据:K1对应到了图中所示的位置,然后沿顺时针找到一个机器节点A,将K1存储到A节点上,K2存储到A节点上,K3、K4存储到B节点上。
?
?
?
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:

?
?
?
?
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
?
?
?
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
?

?
?
?
?
?
引入“虚拟节点”后,映射关系就从 {对象 ->节点 }转换到了 {对象 ->虚拟节点 }。图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,提高了平衡性,因此不会造成“雪崩”现象。
?
?
?
说完了一致性哈希算法的基本原理,下面说一下一致性哈希算法的JAVA实现。
?
?
?
首先定义一个hash函数接口:HashFunction
?
class="java" name="code">/**
* hash 函数接口
*
* @author sundoctor
*
*/
public interface HashFunction {
/**
* hash函数
*
* @param key
* @return
*/
Long hash(String key);
}
?
?
HashFunction一个实现,定义HashFunction接口,为了方便大家根据业务需要实现自己的hash函数。
?
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
public class HashFunctionImpl implements HashFunction {
/**
* MurMurHash算法,是非加密HASH算法,性能很高,碰撞率低
*/
@Override
public Long hash(String key) {
ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN);
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return h;
}
}
?
?
一致性哈希算法的JAVA简单实现:
?
?
import java.util.Collection;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHash<T> {
private final HashFunction hashFunction;// hash 函数接口
private final int numberOfReplicas;// 每个机器节点关联的虚拟节点个数
private final SortedMap<Long, T> circle = new TreeMap<Long, T>();// 环形虚拟节点
/**
*
* @param hashFunction
* hash 函数接口
* @param numberOfReplicas
* 每个机器节点关联的虚拟节点个数
* @param nodes
* 真实机器节点
*/
public ConsistentHash(HashFunction hashFunction, int numberOfReplicas, Collection<T> nodes) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
/**
* 增加真实机器节点
*
* @param node
*/
public void add(T node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
circle.put(this.hashFunction.hash(node.toString() + i), node);
}
}
/**
* 删除真实机器节点
*
* @param node
*/
public void remove(T node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
circle.remove(this.hashFunction.hash(node.toString() + i));
}
}
/**
* 取得真实机器节点
*
* @param key
* @return
*/
public T get(String key) {
if (circle.isEmpty()) {
return null;
}
long hash = hashFunction.hash(key);
if (!circle.containsKey(hash)) {
SortedMap<Long, T> tailMap = circle.tailMap(hash);// 沿环的顺时针找到一个虚拟节点
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash); // 返回该虚拟节点对应的真实机器节点的信息
}
}
?
?
测试:
?
Node类模拟真实机器节点,保存节点的IP、名称、端口等
?
?
/**
* 物理机节点模拟类,保存节点的IP、名称、端口等信息
*
* @author sundoctor
*
* @param <T>
*/
public class Node<T> {
private String ip;// IP
private String name;// 名称
public Node(String ip, String name) {
this.ip = ip;
this.name = name;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* 复写toString方法,使用节点IP当做hash的KEY
*/
@Override
public String toString() {
return ip;
}
}
?
?
测试类:
?
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.UUID;
public class Test {
private static final String IP_PREFIX = "192.168.1.";// 机器节点IP前缀
/**
* @param args
*/
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String, Integer>();// 每台真实机器节点上保存的记录条数
List<Node<String>> nodes = new ArrayList<Node<String>>();// 真实机器节点
// 10台真实机器节点集群
for (int i = 1; i <= 10; i++) {
map.put(IP_PREFIX + i, 0);// 每台真实机器节点上保存的记录条数初始为0
Node<String> node = new Node<String>(IP_PREFIX + i, "node" + i);
nodes.add(node);
}
HashFunction hashFunction = new HashFunctionImpl(); // hash函数实例
ConsistentHash<Node<String>> consistentHash = new ConsistentHash<Node<String>>(hashFunction, 100, nodes);// 每台真实机器引入100个虚拟节点
// 将5000条记录尽可能均匀的存储到10台机器节点
for (int i = 0; i < 5000; i++) {
// 产生随机一个字符串当做一条记录,可以是其它更复杂的业务对象,比如随机字符串相当于对象的业务唯一标识
String data = UUID.randomUUID().toString() + i;
// 通过记录找到真实机器节点
Node<String> node = consistentHash.get(data);
// 再这里可以能过其它工具将记录存储真实机器节点上,比如MemoryCache等
// ...
// 每台真实机器节点上保存的记录条数加1
map.put(node.getIp(), map.get(node.getIp()) + 1);
}
// 打印每台真实机器节点保存的记录条数
for (int i = 1; i <= 10; i++) {
System.out.println(IP_PREFIX + i + "节点记录条数:" + map.get("192.168.1." + i));
}
}
}
?
?
运行测试类Test,输出:
?
192.168.1.1节点记录条数:474
192.168.1.2节点记录条数:489
192.168.1.3节点记录条数:468
192.168.1.4节点记录条数:501
192.168.1.5节点记录条数:412
192.168.1.6节点记录条数:473
192.168.1.7节点记录条数:598
192.168.1.8节点记录条数:521
192.168.1.9节点记录条数:493
192.168.1.10节点记录条数:571
?
?
?
从以上输出可以看到,记录很均匀的分布在10机器节点。
?
?
?