用redis实现支持优先级的消息队列
为什么需要消息队列
系统中引入消息队列机制是对系统一个非常大的改善。例如一个web系统中,用户做了某项操作后需要
发送邮件通知到用户邮箱中。你可以使用
同步方式让用户等待邮件发送完成后反馈给用户,但是这样可能会因为网络的不确定性造成用户长时间的等待从而影响用户体验。
有些场景下是不可能使用同步方式等待完成的,那些需要后台花费大量时间的操作。例如极端
例子,一个
在线编译系统任务,后台编译完成需要30分钟。这种场景的设计不可能同步等待后在回馈,必须是先反馈用户随后
异步处理完成,再等待处理完成后根据情况再此反馈用户与否。
另外适用消息队列的情况是那些系统处理能力有限的情况下,先使用队列机制把任务暂时存放起来,系统再一个个轮流处理掉排队的任务。这样在系统吞吐量不足的情况下也能稳定的处理掉高并发的任务。
消息队列可以用来做排队机制,只要系统需要用到排队机制的地方就可以使用消息队列来作。
rabbitmq的优先级做法
目前成熟的消息队列产品有很多,著名的例如rabbitmq。它使用起来相对还是比较简单的,功能也相对比较丰富,一般场合下是完全够用的。但是有个很烦人的就是它不支持优先级。
例如一个发邮件的任务,某些特权用户希望它的邮件能够更加及时的发送出去,至少比普通用户要优先对待。默认情况下rabbitmq是无法处理掉的,扔给rabbitmq的任务都是FIFO先进先出。但是我们可以使用一些变通的技巧来支持这些优先级。创建多个队列,并为rabbitmq的
消费者设置相应的路由规则。
例如默认情况下有这样一个队列,我们拿list来模拟 [task1, task2, task3],消费者轮流按照FIFO的原则一个个拿出task来处理掉。如果有高优先级的任务进来,它也只能跟在最后被处理[task1, task2, task3, higitask1]. 但是如果使用两个队列,一个高优先级队列,一个普通优先级队列。 普通优先级[task1, task2, task3], 高优先级[hightask1 ] 然后我们设置消费者的路由让消费者随机从任意队列中取数据即可。
并且我们可以定义一个专门处理高优先级队列的消费者,它空闲的时候也不处理低优先级队列的数据。这类似
银行的VIP柜台,普通客户在银行取号排队,一个VIP来了他虽然没有从取号机里拿出一个排在普通会员前面的票,但是他还是可以更快地直接走VIP通道。
使用rabbitmq来做支持优先级的消息队列的话,就像是上面所述同银行VIP会员一样,走不同的通道。但是这种方式只是相对的优先级,做不到绝对的优先级控制,例如我希望某一个优先级高的任务在绝对
意义上要比其他普通任务优先处理掉,这样上面的方案是行不通的。因为rabbitmq的消费者只知道再自己空闲的情况下从自己关心的队列中“随机”取某一个队列里面的第一个数据来处理,它没法控制优先取找哪一个队列。或者更加细粒度的优先级控制。或者你系统里面设置的优先级有10多种。这样使用rabbitmq也是很难实现的。
但是如果使用redis来做队列的话上面的需求都可以实现。
使用redis怎么做消息队列
首先redis它的设计是用来做缓存的,但是由于它自身的某种特性使得他可以用来做消息队列。它有几个阻塞式的API可以使用,正是这些阻塞式的API让他有做消息队列的能力。
试想一下在”数据库解决所有问题“的思路下,不使用消息队列也是可以完成你的需求的。我们把任务全部存放在数据库然后通过不断的轮询方式来取任务处理。这种做法虽然可以完成你的任务但是做法很粗劣。但是如果你的数据库
接口提供一个阻塞的方法那么就可以避免轮询操作了,你的数据库也可以用来做消息队列,只不过目前的数据库还没有这样的接口。
另外做消息队列的其他特性例如FIFO也很容易实现,只需要一个List对象从头取数据,从尾部塞数据即可实现。
redis能做消息队列得益于他list对象blpop brpop接口以及Pub/Sub(发布/订阅)的某些接口。
他们都是阻塞版的,所以可以用来做消息队列。
redis消息队列优先级的实现
一些基础redis基础知识的说明
redis> blpop tasklist 0
"im task 01"
这个例子使用blpop命令会阻塞方式地从tasklist列表中取头一个数据,最后一个参数就是等待
超时的时间。如果设置为0则表示无限等待。另外redis存放的数据都只能是string类型,所以在任务传递的时候只能是传递字符串。我们只需要简单的将负责数据
序列化成json格式的字符串,然后消费者那边再转换一下即可。
这里我们的示例语言使用python,链接redis的库使用redis-py. 如果你有些编程基础把它切换成自己喜欢的语言应该是没问题的。
1.简单的FIFO队列
import redis, time
def handle(task):
print task
time.sleep(4)
def main():
pool = redis.ConnectionPool(host='localhost', port=6379, db=0)
r = redis.Redis(connection_pool=pool)
while 1:
result = r.brpop('tasklist', 0)
handle(result[1])
if __name__ == "__main__":
main()
上例子即使一个最简单的消费者,我们通过一个无限
循环不断地从redis的队列中取数据。如果队列中没有数据则没有超时的阻塞在那里,有数据则取出往下执行。
一般情况取出来是个复杂的字符串,我们可能需要将其格式化后作为再传给处理函数,但是为了简单我们的例子就是一个普通字符串。另外例子中的处理函数不做任
何处理,仅仅sleep 用来模拟耗时的操作。
我们另开一个redis的客户端来模拟生产者,自带的客户端就可以。多往tasklist 队列里面塞上一些数据。
redis> lpush tasklist 'im task 01'
redis> lpush tasklist 'im task 02'
redis> lpush tasklist 'im task 03'
redis> lpush tasklist 'im task 04'
redis> lpush tasklist 'im task 05'
随后在消费者端便会看到这些模拟出来的任务被挨个消费掉。
2.简单优先级的队列
假设一种简单的需求,只需要高优先级的比低优先级的任务率先处理掉。其他任务之间的顺序一概不管,这种我们只需要在在遇到高优先级任务的时候将它塞到队列的前头,而不是push到最后面即可。
因为我们的队列是使用的redis的 list,所以很容易实现。遇到高优先级的使用rpush 遇到低优先级的使用lpush
redis> lpush tasklist 'im task 01'
redis> lpush tasklist 'im task 02'
redis> rpush tasklist 'im high task 01'
redis> rpush tasklist 'im high task 01'
redis> lpush tasklist 'im task 03'
redis> rpush tasklist 'im high task 03'
随后会看到,高优先级的总是比低优先级的率先执行。但是这个方案的缺点是高优先级的任务之间的执行顺序是先进后出的。
3.较为完善的队列
例子2中只是简单的将高优先级的任务塞到队列最前面,低优先级的塞到最后面。这样保证不了高优先级任务之间的顺序。
假设当所有的任务都是高优先级的话,那么他们的执行顺序将是相反的。这样明显违背了队列的FIFO原则。
不过只要稍加改进就可以完善我们的队列。
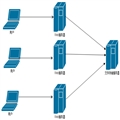
跟使用rabbitmq一样,我们设置两个队列,一个高优先级一个低优先级的队列。高优先级任务放到高队列中,低的放在低优先队列中。redis和rabbitmq不同的是它可以要求队列消费者从哪个队列里面先读。
def main():
pool = redis.ConnectionPool(host='localhost', port=6379, db=0)
r = redis.Redis(connection_pool=pool)
while 1:
result = r.brpop(['high_task_queue', 'low_task_queue'], 0)
handle(result[1])
上面的代码,会阻塞地从'high_task_queue', 'low_task_queue'这两个队列里面取数据,如果第一个没有再从第二个里面取。
所以只需要将队列消费者做这样的改进便可以达到目的。
redis> lpush low_task_queue low001
redis> lpush low_task_queue low002
redis> lpush low_task_queue low003
redis> lpush low_task_queue low004
redis> lpush high_task_queue low001
redis> lpush high_task_queue low002
redis> lpush high_task_queue low003
redis> lpush high_task_queue low004
通过上面的测试看到,高优先级的会被率先执行,并且高优先级之间也是保证了FIFO的原则。
这种方案我们可以支持不同阶段的优先级队列,例如高中低三个级别或者更多的级别都可以。
4.优先级级别很多的情况
假设有个这样的需求,优先级不是简单的高中低或者0-10这些固定的级别。而是类似0-99999这么多级别。那么我们第三种方案将不太合适了。
虽然redis有sorted set这样的可以排序的数据类型,看是很可惜它没有阻塞版的接口。于是我们还是只能使用list类型通过其他方式来完成目的。
有个简单的做法我们可以只设置一个队列,并保证它是按照优先级排序号的。然后通过二分查找法查找一个任务合适的位置,并通过 lset 命令插入到相应的位置。
例如队列里面包含着写优先级的任务[1, 3, 6, 8, 9, 14],当有个优先级为7的任务过来,我们通过自己的二分
算法一个个从队列里面取数据出来反和目标数据比对,计算出相应的位置然后插入到指定地点即可。
因为二分查找是比较快的,并且redis本身也都在
内存中,理论上速度是可以保证的。但是如果说数据量确实很大的话我们也可以通过一些方式来
调优。
回想我们第三种方案,把第三种方案
结合起来就会很大程度上减少开销。例如数据量十万的队列,它们的优先级也是随机0-十万的区间。我们可以设置10个或者100个不同的队列,0-一万的优先级任务投放到1号队列,一万-二万的任务投放到2号队列。这样将一个队列按不同等级拆分后它单个队列的数据就减少许多,这样二分查找匹配的效率也会高一点。但是数据所占的资源基本是不变的,十万数据该占多少内存还是多少。只是系统里面多了一些队列而已。