为什么说NoSQL重要
SQL语言和关系型数据库(MySQL,PostgreSQL,Oracle,等等)是通用的数据解决方案,占用绝大多数的市场。不过在最近兴起的NoSQL运动中,涌现出来了一批具备高可用性,支持线性扩展,支持Map/Reduce操作等等特性的数据产品,它们具有如下特性:
频繁的写入操作,相对较少的读取统计信息的操作(比如一个web访问计数器)应该使用基于内存的key/value存储系统,比如Redis,或者是具备本地更新特性的文档存储系统,如MongoDB。
海量数据(比如cangku.html" target="_blank">数据仓库中需要分析的数据)适合与存储在一个schmaless,分布式的文件存储系统中,如Hadoop。
存储二进制文件(比如mp3或者pdf文档)并且能够直接为用户的浏览器提供下载功能,可以使用Amazon S3。
临时性的数据(比如网站的session,分布式的锁信息,等等)适合存储在Memcache。
如果希望数据具备高可用性,并且能够将数据丢失的风险降到最低,同时整个系统具备线性扩展的能力,可以考虑使用Cassandra和HBase。
使用这些数据产品并不是要取代原有的数据产品,而是为不同的应用场景提供更多的选择。
提供最适合的数据存储方案 - 如何选择合适的NoSQL产品?
NoSQL代表着:选择合适的方案处理合适的业务场景。上面介绍的几种NoSQL应用场景也许能够帮助我们选择合适的数据存储方案,网上也有不少值得参考的资源。和其他的技术方案一样,选择适合你们的业务场景才是最重要的。
绝大多数的应用都会有非常复杂的应用场景,如何找出一款NoSQL产品能够适用所用的需求?答案是搭配使用多款NoSQL产品,传统数据库中的One-For-All的情况在NoSQL中是不存在的。比如下图中,我们可以在一个网站中使用下面四款数据产品来提供服务:
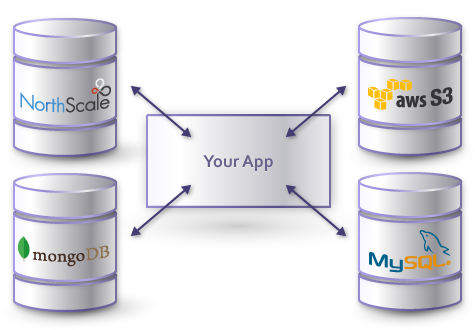
MySQL用于存储敏感的数据,比如用户的资料,交易的信息等等。
MongoDB用于存储大量的,相对不敏感的数据,比如博客文章的内容,文章访问次数等等。
Amazon S3用于存储用户上传的文档,图片,音乐等等数据。
Memcached用于存储临时性的信息,比如缓存HTML页面等。
选择多样的数据存储方案同样有利于提升我们对于NoSQL的数据产品的理解,从大量的解决方案中选择最适合我们使用的产品,而不是把眼光仅仅放在某一款产品中。
最适合的才是最好的。
再论NoSQL
目前市场上的关系型数据库都是在多年前设计出来的,在设计这些关系型数据库中的时候,磁盘存储是廉价的,而内存和cpu的资源是昂贵的。而在今天再去考虑这个问题就不一样了,内存和cpu都已经不再昂贵,同时具备线性扩展的特性又显得尤为重要。
NoSQL的数据产品倾向于使用内存作为首先的存储。比如Redis和Memcached,几乎都是在内存中完成的所有的操作。又比如Cassandra和HBase这样的系统,它们使用了memtable的技术,使得所有写入的数据先缓存到内存中,等到内存中积累了一定量的数据后,再一次性异步写入到磁盘中。
Database-as-a-Service
目前提供Infrastructure-as-a-service的比如Amazon EC2,Google App Engine,Rackspace Cloud,未来将会出现Database-as-a-Service。目前已经有类似的服务提供商,比如MongoHQ (MongoDB),Cloudant (CouchDB),和Amazon RDS(MySQL)。它们提供了数据的存储,管理和扩展服务,让我们更加专注应用程序本身。

未来无限美好。
原文链接:http://www.cnblogs.com/gpcuster/archive/2010/10/20/1857138.html