一直以来,都以为,想在Win上提交hadoop集群的作业,必须得在eclipse上安装hadoop-eclipse-plugin插件才可以提交,但最近与同事交流,发现其实,不一定必须安装hadoop的eclipse插件,才能提交。今天试了一把,发现果然可以不用安装插件也可以正确提交作业到集群上,故在此总结一下。
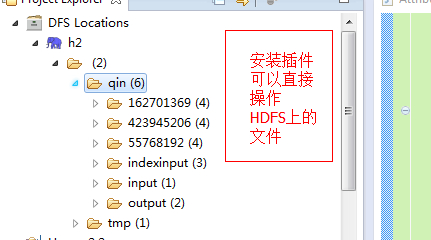
既然,无须安装hadoop的eclipse插件,就能提交hadoop作业,那为毛,还出现了这个插件呢? 其实安装插件除了能直接提交作业外,还有一个比较方便的功能,就是能直接在eclipse上对HDFS上的文件,进行删除,上传,新建目录等,这一点是不安装插件做不到的,当然,如果你不需要这些操作,那么就无所谓了,仅仅提交个作业而已。
 下面说下,如何在eclipse上使用无插件提交hadoop作业,(在hadoop集群的8088界面上可以看到提交的作业信息是否成功)。
下面说下,如何在eclipse上使用无插件提交hadoop作业,(在hadoop集群的8088界面上可以看到提交的作业信息是否成功)。
序号操作说明1eclipse IDE散仙在这里是4.2版本的eclipse2hadoop2.2的64位完整包散仙在这里放在D盘根目录下3修改源码org/apache/hadoop/mapred/YARNRunner.java,改变linux与windows的路径不一致bug散仙已经修改好,文末散仙会上传这个修改好的类4把linux集群上的配置文件,core-site.xml,hdfs-site.xml,mapred.site.xml和yarn-site.xml文件,放在src根目录下,另外在D盘hadoop的/etc/hadoop目录下,覆盖一下注意一致5编写wordcount的MR例子,开始测试入门测试6高富帅工程师一名主角7配置hadoop的win上的环境变量HADOOP_HOME只配置这一个即可
上面的操作都完成后,就可以进行测试了,散仙在这里的WordCount源码如下:
class="java" name="code">package com.mywordcount;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FilenameFilter;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
/***
*
* Hadoop2.2.0 无插件提交集群作业
*
* @author qindongliang
*
* hadoop技术交流群: 376932160
*
*
* */
public class MyWordCount2 {
/**
* Mapper
*
* **/
private static class WMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable count = new IntWritable(1);
private Text text = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String values[] = value.toString().split("#");
// System.out.println(values[0]+"========"+values[1]);
count.set(Integer.parseInt(values[1]));
text.set(values[0]);
context.write(text, count);
}
}
/**
* Reducer
*
* **/
private static class WReducer extends
Reducer<Text, IntWritable, Text, Text> {
private Text t = new Text();
@Override
protected void reduce(Text key, Iterable<IntWritable> value,
Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable i : value) {
count += i.get();
}
t.set(count + "");
context.write(key, t);
}
}
public static void printEnv(Job job) {
Configuration conf = job.getConfiguration();
System.out.println("###########################################");
System.out.println("fs.defaultFS:" + conf.get("fs.defaultFS"));
System.out.println("mapred.job.tracker:"
+ conf.get("mapred.job.tracker"));
System.out.println("mapreduce.framework.name" + ":"
+ conf.get("mapreduce.framework.name"));
System.out.println("yarn.nodemanager.aux-services" + ":"
+ conf.get("yarn.nodemanager.aux-services"));
System.out.println("yarn.resourcemanager.address" + ":"
+ conf.get("yarn.resourcemanager.address"));
System.out.println("yarn.resourcemanager.scheduler.address" + ":"
+ conf.get("yarn.resourcemanager.scheduler.address"));
System.out.println("yarn.resourcemanager.resource-tracker.address"
+ ":"
+ conf.get("yarn.resourcemanager.resource-tracker.address"));
System.out.println("yarn.application.classpath" + ":"
+ conf.get("yarn.application.classpath"));
System.out.println("zkhost:" + conf.get("zkhost"));
System.out.println("namespace:" + conf.get("namespace"));
System.out.println("project:" + conf.get("project"));
System.out.println("collection:" + conf.get("collection"));
System.out.println("shard:" + conf.get("shard"));
System.out.println("###########################################");
}
/**
* 载入hadoop的配置文件
* 兼容hadoop1.x和hadoop2.x
*
* */
public static void getConf(final Configuration conf) throws FileNotFoundException{
String HADOOP_CONF_DIR = System.getenv().get("HADOOP_CONF_DIR");
String HADOOP_HOME = System.getenv().get("HADOOP_HOME");
System.out.println("HADOOP_HOME:" + HADOOP_HOME);
System.out.println("HADOOP_CONF_DIR:" + HADOOP_CONF_DIR);//此处兼容hadoop1.x
//此处兼容hadoop2.x
if (HADOOP_CONF_DIR == null || HADOOP_CONF_DIR.isEmpty()) {
HADOOP_CONF_DIR = HADOOP_HOME + "/etc/hadoop";
}
//得到hadoop的conf目录的路径加载文件
File file = new File(HADOOP_CONF_DIR);
FilenameFilter filter = new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.endsWith("xml");
}
};
//获取hadoop的仅仅xml结尾的文件列表
String[] list = file.list(filter);
for (String fn : list) {
System.out.println("Loading Configuration: " + HADOOP_CONF_DIR
+ "/" + fn);
//循环加载xml文件
conf.addResource(new FileInputStream(HADOOP_CONF_DIR + "/" + fn));
}
//yarn的classpath路径,如果为空则加载拼接yarn的路径
if (conf.get("yarn.application.classpath", "").isEmpty()) {
StringBuilder sb = new StringBuilder();
sb.append(System.getenv("CLASSPATH")).append(":");
sb.append(HADOOP_HOME).append("/share/hadoop/common/lib/*")
.append(":");
sb.append(HADOOP_HOME).append("/share/hadoop/common/*").append(":");
sb.append(HADOOP_HOME).append("/share/hadoop/hdfs/*").append(":");
sb.append(HADOOP_HOME).append("/share/hadoop/mapreduce/*")
.append(":");
sb.append(HADOOP_HOME).append("/share/hadoop/yarn/*").append(":");
sb.append(HADOOP_HOME).append("/lib/*").append(":");
conf.set("yarn.application.classpath", sb.toString());
}
}
public static void main(String[] args) throws Exception { {
Configuration conf = new Configuration();
conf.set("mapreduce.job.jar", "myjob.jar");//此处代码,一定放在Job任务前面,否则会报类找不到的异常
Job job = Job.getInstance(conf, "345");
getConf(conf);
job.setJarByClass(MyWordCount2.class);
job.setMapperClass(WMapper.class);
job.setReducerClass(WReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String path = "/qin/output";
FileSystem fs = FileSystem.get(conf);
Path p = new Path(path);
if (fs.exists(p)) {
fs.delete(p, true);
System.out.println("输出路径存在,已删除!");
}
FileInputFormat.setInputPaths(job, "/qin/input");
FileOutputFormat.setOutputPath(job, p);
printEnv(job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
}
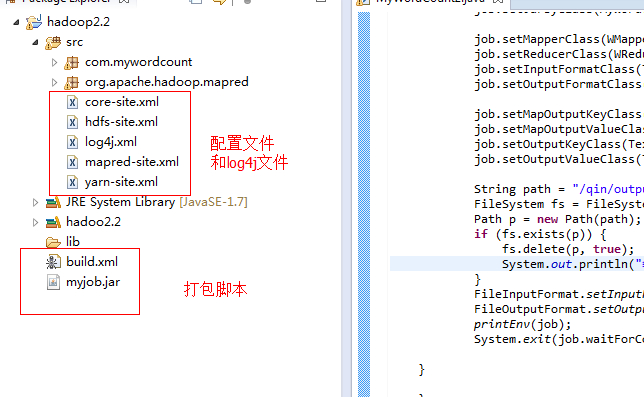
项目结构目录,截图如下:
 运行信息如下:
运行信息如下:
HADOOP_HOME:D:\hadoop-2.2.0
HADOOP_CONF_DIR:null
Loading Configuration: D:\hadoop-2.2.0/etc/hadoop/capacity-scheduler.xml
Loading Configuration: D:\hadoop-2.2.0/etc/hadoop/core-site.xml
Loading Configuration: D:\hadoop-2.2.0/etc/hadoop/hadoop-policy.xml
Loading Configuration: D:\hadoop-2.2.0/etc/hadoop/hdfs-site.xml
Loading Configuration: D:\hadoop-2.2.0/etc/hadoop/httpfs-site.xml
Loading Configuration: D:\hadoop-2.2.0/etc/hadoop/mapred-site.xml
Loading Configuration: D:\hadoop-2.2.0/etc/hadoop/yarn-site.xml
2014-06-25 20:40:08,419 WARN [main] conf.Configuration (Configuration.java:loadProperty(2172)) - java.io.FileInputStream@3ba08dab:an attempt to override final parameter: mapreduce.jobtracker.address; Ignoring.
输出路径存在,已删除!
###########################################
fs.defaultFS:hdfs://h1:9000
2014-06-25 20:40:08,897 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
mapred.job.tracker:h1:8021
mapreduce.framework.name:yarn
yarn.nodemanager.aux-services:mapreduce_shuffle
yarn.resourcemanager.address:h1:8032
yarn.resourcemanager.scheduler.address:h1:8030
yarn.resourcemanager.resource-tracker.address:h1:8031
yarn.application.classpath:$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
zkhost:null
namespace:null
project:null
collection:null
shard:null
###########################################
2014-06-25 20:40:08,972 INFO [main] client.RMProxy (RMProxy.java:createRMProxy(56)) - Connecting to ResourceManager at h1/192.168.46.32:8032
2014-06-25 20:40:09,153 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(149)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2014-06-25 20:40:09,331 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(287)) - Total input paths to process : 1
2014-06-25 20:40:09,402 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(394)) - number of splits:1
2014-06-25 20:40:09,412 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - user.name is deprecated. Instead, use mapreduce.job.user.name
2014-06-25 20:40:09,412 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.jar is deprecated. Instead, use mapreduce.job.jar
2014-06-25 20:40:09,413 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
2014-06-25 20:40:09,413 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.mapoutput.value.class is deprecated. Instead, use mapreduce.map.output.value.class
2014-06-25 20:40:09,413 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
2014-06-25 20:40:09,414 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.job.name is deprecated. Instead, use mapreduce.job.name
2014-06-25 20:40:09,414 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
2014-06-25 20:40:09,414 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapreduce.inputformat.class is deprecated. Instead, use mapreduce.job.inputformat.class
2014-06-25 20:40:09,414 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
2014-06-25 20:40:09,414 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
2014-06-25 20:40:09,415 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapreduce.outputformat.class is deprecated. Instead, use mapreduce.job.outputformat.class
2014-06-25 20:40:09,416 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2014-06-25 20:40:09,416 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
2014-06-25 20:40:09,416 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.mapoutput.key.class is deprecated. Instead, use mapreduce.map.output.key.class
2014-06-25 20:40:09,416 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
2014-06-25 20:40:09,502 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(477)) - Submitting tokens for job: job_1403723552088_0016
2014-06-25 20:40:09,651 INFO [main] impl.YarnClientImpl (YarnClientImpl.java:submitApplication(174)) - Submitted application application_1403723552088_0016 to ResourceManager at h1/192.168.46.32:8032
2014-06-25 20:40:09,683 INFO [main] mapreduce.Job (Job.java:submit(1272)) - The url to track the job: http://h1:8088/proxy/application_1403723552088_0016/
2014-06-25 20:40:09,683 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1317)) - Running job: job_1403723552088_0016
2014-06-25 20:40:17,070 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1338)) - Job job_1403723552088_0016 running in uber mode : false
2014-06-25 20:40:17,072 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 0% reduce 0%
2014-06-25 20:40:23,232 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 100% reduce 0%
2014-06-25 20:40:30,273 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 100% reduce 100%
2014-06-25 20:40:30,289 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1356)) - Job job_1403723552088_0016 completed successfully
2014-06-25 20:40:30,403 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1363)) - Counters: 43
File System Counters
FILE: Number of bytes read=58
FILE: Number of bytes written=160123
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=136
HDFS: Number of bytes written=27
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4398
Total time spent by all reduces in occupied slots (ms)=4263
Map-Reduce Framework
Map input records=4
Map output records=4
Map output bytes=44
Map output materialized bytes=58
Input split bytes=98
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=58
Reduce input records=4
Reduce output records=3
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=94
CPU time spent (ms)=980
Physical memory (bytes) snapshot=310431744
Virtual memory (bytes) snapshot=1681850368
Total committed heap usage (bytes)=136450048
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=38
File Output Format Counters
Bytes Written=27
至此,我们已经可以成功的在无插件的环境里提交hadoop任务了,如果提交过程中,出现权限异常,可以在eclipse的run环境里配置,linux上安装hadoop的用户名即可,截图如下:
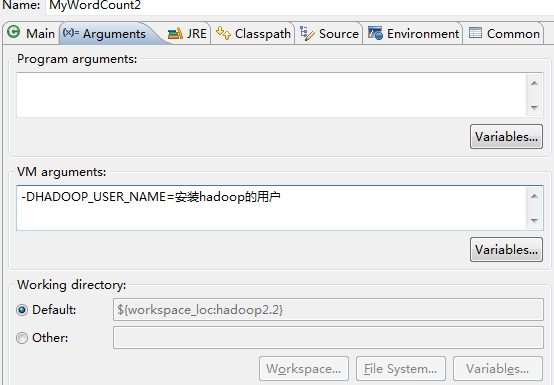 注意,一定是安装hadoop的用户,写成其他的用户,可能会导致没有权限访问HDFS上的数据,从而使提交的作业运行失败。
注意,一定是安装hadoop的用户,写成其他的用户,可能会导致没有权限访问HDFS上的数据,从而使提交的作业运行失败。

- 大小: 108 KB

- 大小: 283.4 KB

- 大小: 135.4 KB
![[原创]jquery+css3打造一款ajax分页插件](/Upload/SmallIMG/2014061810/C392BC951A1BADDB.jpg)