昨天的文章大致构建了一个data matrix, 并进行了数据清理。有一个遗留问题就是,如何将连续的Age属性离散化?
?
对于连续属性离散化,可以参考《数据挖掘导论》 2.3.6小节。
首先,我们试着将数据图形化,看看是否有明显的间隔区间。 画图依然使用JFreeChart来进行。
从肉眼的角度来分析,虽然没有太明显的区间,但是从分布上看,基本上能如下图进行划分:
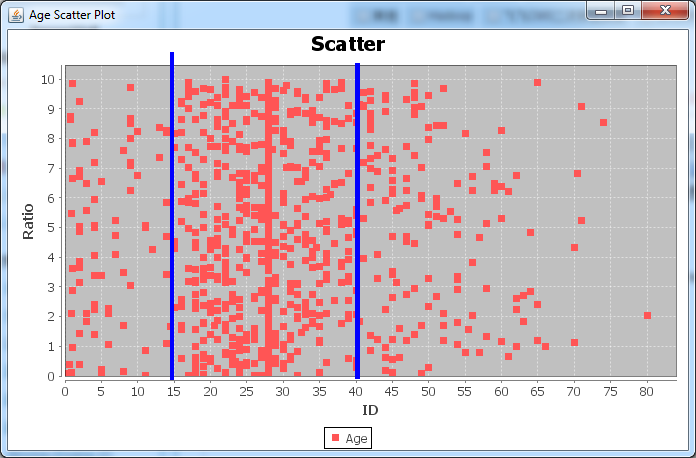
?
再来一张书上的原图进行对比:
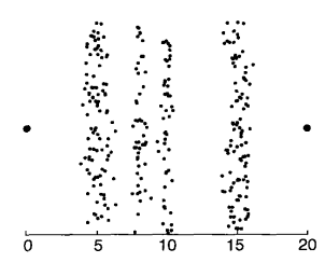
这一张图里面的分布区间就太明显了。
?
除了使用图形化的方式来进行离散化,还可以有其他的方法:
(1) 等宽: 比如Age: [0~15] [15~30] [30~45] ...
(2) 等频率/等深 :比如前100个样本成一个区间,101~200个成1个区间 ...
(3) K均值(K-Means) : 这个方法现在有点早~ 后面可以进一步优化的时候再采用这种方法进行Age属性划分
?
所以,现在Age的划分就按照:
[0:15), [15:40) [40:+∞)
?
最后附上今天refine过的dataClean方法
class="java" name="code">public static double[][] dataClean(List<String[]> list) {
double[][] dataMatrix = new double[list.size()][6];
List<Double> ageList = new ArrayList<Double>();
int startIndex = 0;
int Survived_INDEX = startIndex++;
int Pclass_INDEX = startIndex++;
int Sex_INDEX = startIndex++;
int Age_INDEX = startIndex++;
int SibSp_INDEX = startIndex++;
int Embarked_INDEX = startIndex++;
for(int i = 0; i < list.size(); i++){
String[] arr = list.get(i);
// Survived
dataMatrix[i][Survived_INDEX] = Integer.parseInt(arr[1]);
// Pclass
dataMatrix[i][Pclass_INDEX] = Integer.parseInt(arr[2]);
// Sex
if(arr[4].equals("male")) {
dataMatrix[i][Sex_INDEX] = 1;
} else {
dataMatrix[i][Sex_INDEX] = 2;
}
// Age
if(arr[5].length() == 0) {
dataMatrix[i][Age_INDEX] = -1; // 首先将缺失值设置为-1
} else {
dataMatrix[i][Age_INDEX] = Double.parseDouble(arr[5]);
ageList.add(Double.parseDouble(arr[5]));
}
// SibSp 将值大于2的归集为同一类
if(Integer.parseInt(arr[6]) >= 2 ) {
dataMatrix[i][SibSp_INDEX] = 2;
} else {
dataMatrix[i][SibSp_INDEX] = Integer.parseInt(arr[6]);
}
// Embarked C:1 Q:2 S:3 U:4
// 原始数据之中已经手动的将缺失值补充为U,不是CQS的值,也用4来代替
String embarked = arr[11];
if(embarked.equals("C")) {
dataMatrix[i][Embarked_INDEX] = 1;
} else if(embarked.equals("Q")) {
dataMatrix[i][Embarked_INDEX] = 2;
} else if(embarked.equals("S")) {
dataMatrix[i][Embarked_INDEX] = 3;
} else {
dataMatrix[i][Embarked_INDEX] = 4;
}
}
// 将Age=-1的值变成中位数
double[] ageArr = new double[ageList.size()];
for(int i = 0; i < ageArr.length; i++) {
ageArr[i] = ageList.get(i);
}
double median = StatUtils.percentile(ageArr, 50.0); //中位数
for(int i = 0; i < dataMatrix.length; i++) {
if(dataMatrix[i][3] == -1) {
dataMatrix[i][3] = median;
}
// 直接将Age离散化 [0:15), [15:40) [40:+∞)
if(dataMatrix[i][3] < 15) dataMatrix[i][3] = 1;
else if(dataMatrix[i][3] < 40) dataMatrix[i][3] = 2;
else dataMatrix[i][3] = 3;
}
return dataMatrix;
}
?
至此,第一步 数据预处理基本上完成。接下来应该做的就是构建一个决策树进行分类与预测了!
提交了一部分代码,可以到https://gitcafe.com/rangerwolf/Kaggle-Titanic 下载




![[Kaggle实战] Titanic 逃生预测 (3) - Age离散化](/Upload/SmallIMG/2014060212/96DD8971381BE64B.png)

