回顾上次写博客至今都有4个多月了,最近工作比较的忙没时间写博文。以后会多坚持写博文,与大家分享下最近遇到的问题。最近因为项目需要,研究了下用C#开发TTS。下面把大体的思路给大家说说,希望对大家有所帮助。
首先需要了解下MS的SAPI,它是微软的语音API。它包括了语音识别SR引擎和语音合成SS引擎两种语音引擎。等下会给大家看下语音合成SS引擎。它由不同的版本,操作系统的不同使用的版本不同,不过我喜欢使用其他的合成语音包,比如:NeoSpeech公司的合成语音包。回过头来,MS 的SAPI的版本有:5.1、5.3和5.4。具体用途如下:
1. Windows Speech SDK 5.1版本支持xp系统和server 2003系统,需要下载安装。XP系统默认只带了个Microsoft Sam英文男声语音库,想要中文引擎就需要安装Windows Speech SDK 5.1。下载地址:http://www.microsoft.com/download/en/details.aspx?id=10121
2. Windows Speech SDK 5.3版本支持Vista系统和Server 2008系统,已经集成到系统里。Vista和Server 2003默认带Microsoft lili中文女声语音库和Microsoft Anna英文女声语音库。
3. Windows Speech SDK 5.4版本支持Windows7系统,也已经集成到系统里,不需要下载安装。Win7系统同样带了Microsoft lili中文女声语音库和Microsoft Anna英文女声语音库。Microsoft lili支持中英文混读。
到这里环境就准备好了,接下来讲诉下开发TTS要用到的类,我使用的是.net类库提供的语音类System.Speech.Synthesis.SpeechSynthesizer,使用前需要添加引用:System.Speech。该类的主要方法、属性、事件如下:
方法:
GetInstalledVoices():获取当前系统中安装的语音播放人,返回一个VoiceInfo对象集合,具体的对象有在控制面板中,语音项可以查看。Xp默认是Microsoft Sam。
SelectVoice(string):选择当前朗读的人员,参数是朗读者名称,如:Microsoft Sam
SpeakAsync(string):开始进行异步朗读,参数是朗读的文本。
Speak(string):开始进行朗读,参数是朗读的文本。这里我没有弄懂SpeakAsync和Speak的区别,我试了下效果都一样。
Pause():暂停正在播放朗读。
Resume():继续播放暂停的朗读。
SetOutputToWaveFile(string):保存语音文件,调用该方法后需要调用Speak方法。参数是保存文件的路径。如:d:/124.wav或d:/123.MP3
SetOutputToNull():保存文件结束语句,必须调用该语句,否则生产的语音文件无法播放。
属性:
Rate:播放语速,-10~10
Volume:音量调节:0~100
Voice:正在使用某个人员播放,返回:VoiceInfo对象。
事件:
SpeakCompleted:朗读完成事件,朗读完成后会触发该时间。可以在该事件中处理播放完成后的流程。
SpeakStarted:朗读开始事件。
SpeakProgress:朗读过程事件,可以继续一些进度条处理。
。。。。
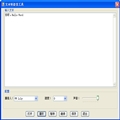
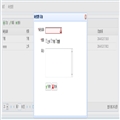
其他属性、方法、事件用得少就不多讲了,自己看下API就知道了。具体代码我就不贴上来了,因为是公司内部资料。有什么问题可以给我留言,我们共同探讨。界面如下:



有个问题,不知道是什么原因,要播放的内容:欢迎致电12345客服服务系统,它把12345给我朗读成:1万2千3百4十五。这个问题还在解决中,谁知道麻烦给我留下言,谢谢。