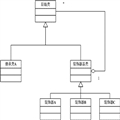
xml的
解析一般分为两种方式,一种是SAX事件流的方式,另外一种是基于DOM的xml文档树结构解析,SAX是一边解析一边加载,而DOM需要一次性将
XML文件全部加载到
内存中,再解析构建成文档数的模式。
首先看一下基于DOM的
XML解析和创建。
案例xml内容:
引用
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<employees>
<employee>
<name>ddviplinux</name>
<sex>m</sex>
<parents>
<father>xxx</father>
<mother>yyy</mother>
</parents>
</employee>
</employees>
1.首先定一个方法
接口:
class="java" name="code">
import org.w3c.dom.Document;
public interface XmlDocument {
public void createDocument(String fileName);
public void parserDocument(String fileName);
}
里面包含了创建和解析的方法定义。
2.实现这个接口:
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.PrintWriter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerFactoryConfigurationError;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import com.ailk.xmlparserdemon.intf.XmlDocument;
public class DomXmlDemon implements XmlDocument {
Document document;
static String fileName;
public void init(){
try {
DocumentBuilderFactory builderFactory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=builderFactory.newDocumentBuilder();
[b] this.document=builder.newDocument();[/b] } catch (ParserConfigurationException e) {
e.printStackTrace();
}
}
/**
* DOM方式生成xml文件
*/
public void createDocument(String fileName) {
Element root=this.document.createElement("employees");
this.document.appendChild(root);
Element employee=this.document.createElement("employee");
Element name=this.document.createElement("name");
name.appendChild(this.document.createTextNode("ddviplinux"));
employee.appendChild(name);
Element sex=this.document.createElement("sex");
sex.appendChild(this.document.createTextNode("m"));
employee.appendChild(sex);
Element parents=this.document.createElement("parents");
Element father=this.document.createElement("father");
father.appendChild(this.document.createTextNode("xxx"));
parents.appendChild(father);
Element mother=this.document.createElement("mother");
mother.appendChild(this.document.createTextNode("yyy"));
parents.appendChild(mother);
employee.appendChild(parents);
root.appendChild(employee);
try {
DOMSource source=new DOMSource(this.document);
TransformerFactory tf=TransformerFactory.newInstance();
Transformer transf=tf.newTransformer();
transf.setOutputProperty(OutputKeys.ENCODING, "UTF-8");//设置编码格式
transf.setOutputProperty(OutputKeys.INDENT, "yes");//设置是否在格式化时添加多于的空格
PrintWriter pw=new PrintWriter(new FileOutputStream(fileName));
StreamResult result=new StreamResult(pw);
transf.transform(source, result);
System.out.println("生成文件成功:"+fileName);
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerFactoryConfigurationError e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void parserDocument(String fileName) {
try {
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
[b] Document document=db.parse(fileName);[/b]
NodeList employees=document.getChildNodes();
for(int i=0;i<employees.getLength();i++){
Node employee=employees.item(i);
NodeList employeeInfo=employee.getChildNodes();
for(int j=0;j<employeeInfo.getLength();j++){
Node node=employeeInfo.item(j);
NodeList employeeMeta=node.getChildNodes();
for(int k=0;k<employeeMeta.getLength();k++){
System.out.println(employeeMeta.item(k).getNodeName()+" : "+employeeMeta.item(k).getTextContent());
}
}
}
System.out.println("解析完毕!");
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args){
DomXmlDemon dom=new DomXmlDemon();
DomXmlDemon.fileName="E:\\OneNote\\dom.xml";
dom.init();
dom.createDocument(fileName);
dom.parserDocument(fileName);
}
}
从上面的实现方法中,我们可以看出来,不管是在解析或者是生成的时候,首先都需要或许到一个documentbuilder,而这里面用到了一个工厂方法,直接获取:
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();