我发现,凡事任何事情,都要留个心,否则的话,就是看完了,也会忘记,我以前看了个笔试题,当时就是涉及到中文字符串的问题,结果,我就直接把人家的答案和总结拿来看了,也没去思考,结果,现在又碰到了这种问题,但是,我却忘得一干二净。
首先要了解中文字符有多种编码及各种编码的特征。,这里,作者抓住了,凡是中文转换成byte[]数组的时候,是负数,这么个规律,进行解答,(其实我的疑问是,我很想搞清楚,为什么中文转换成byte数组,结果就是负数,它到底是怎么编码的,我找了很久,都没有结果,但是,找到了一些有用的信息,也许,我以后对中文乱码的时候,不会素手无策了。)
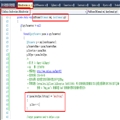
??? 假设n为要截取的字节数。
?????? p lic static void main(String[] args) throws Exception{
????????????? String str = "我a爱中华abc我爱传智def';
????????????? String str = "我ABC汉";
????????????? int num = trimGBK(str.getBytes("GBK"),5);
????????????? System.out.println(str.s string(0,num) );
?????? }
?????
?? p lic static int? trimGBK(byte[] b,int n){
????????????? int num = 0;
????????????? boolean bChineseFirstHalf = false;
????????????? for(int i=0;i<n;i++)
????????????? {
???????????????????? if(b[i]<0 && !bChineseFirstHalf){
??????????????????????????? bChineseFirstHalf = tr;
???????????????????? }else{
??????????????????????????? num++;
??????????????????????????? bChineseFirstHalf = false;?????????????????????????
???????????????????? }
????????????? }
????????????? return num;
?????? }
???? * 1、如果b[i]有63,不用转码; A-2
???? * 2、如果b[i]全大于0,那么为英文字符串,不用转码; B-1
???? * 3、如果b[i]有小于0的,那么已经乱码,要转码。 C-1
???? */
?String string = "啊";??
???????? byte by[] = string.getBytes();?
???????? for(int i=0;i<by.length;i++)
?????? System.out.println(by[i]);
???????? try {
??? by = string.getBytes("utf8");
?? } catch (UnsupportedEncodingException e) {
??? e.printStackTrace();
?? }
??? for(int i=0;i<by.length;i++)
??????? System.out.println(by[i]);
?? try {
??? by = string.getBytes("gb2312");
?? } catch (UnsupportedEncodingException e) {
??? // TODO Auto-generated catch block
??? e.printStackTrace();
?? }
???????? for(int i=0;i<by.length;i++)
??????? System.out.println(by[i]);
???????? try {
??? by = string.getBytes("iso-8859-1");
?? } catch (UnsupportedEncodingException e) {
??? // TODO Auto-generated catch block
??? e.printStackTrace();
?? }
???????? for(int i=0;i<by.length;i++)
??????? System.out.println(by[i]);
输出结果:
-80
-95
*
-27
-107
-118
*
-80
-95
*
63
转了一篇挺好的文章:关于Java编码问题
Java的编码问题挺烦的,以前总弄不清除,现在理了一下算是清晰一点。做个总结吧~
编码问题的由来
这个问题网上资料很多的,这里不多说了,推荐几篇吧。Java编码问题详解,计算机编码大全,转:谈谈Unicode编码,简要解释 S、UTF、BMP、BOM等名词。说的还是比较清楚了。下面主要用程序说说。
String是什么?
以前一直不清楚Java编码转来转去转的是啥。原来是因为不知道String是啥。在Java里,一个String就是一串Unicode编码的字符串。也就是说,Java在整个处理过程中,字符都是以Unicode编码的。具体使用的是UTF-16也就是双字节的Unicode编码。这就解释了Java中为啥有个16bit的char类型。String就是由一个个char组成的。一个char中存的就是一个对应字符的Unicode编码。
所以,Unicode在Java中成为一种“中间码”,因为他覆盖了基本上所有的字符。而其他编码的转换都可以通过他来完成。
PS:话说回来,用双字节的话还是无法覆盖整个字符集的(因为有UTF-32),所以以前曾怀疑过char是否真是用来放Unicode字符的,只有16的话以后扩展怎么办?现在确定了,扩展问题目前不用考虑。。。
转什么?怎么转?
这里再说一个东西――byte。为啥说它?因为所有的转来转去都是在转它。为啥转它?因为他是字符编码的最小单位。一个byte 是8bit,所有编码方式都是由整数个byte组成的。所以,同一个String的不同编码方式可以理解为同一个字符的不同byte数组表示而已。所以,自然而然我们就可以看到这样的代码了:
String S = “测试”
s.getBytes(“utf8″);
s.getBytes(“GB2312″);
s.getBytes(“GBK”);
通过这种方式就可以获得任何编码的byte数组。所以,在知道了一个byte[]数组,和它的编码方式的情况下,我们就能获得对应的String,所以有了下面的代码:
byte[] b = *****;
String s = new String(b, “utf8″);
s = new String(b, “gb2312″);
通过上面可以看出,从String可以获得任何编码的byte数组,但是从byte数组到String就要小心了,必须知道对应的编码方式才能进行。可以这么说,byte数组告诉了我们这个字符的内容,而编码方式告诉了我们如何去读这个byte数组才能获得我们需要的信息。
什么时候转?
一句话――有IO的时候。编码问题主要出现在文件读取,网络传输等,可以说只要有信息传递的地方都存在这个问题。而在Java中,所有信息的获取(发送)已经被抽象为“流”的概念,所以,这就解释了为什么Java的IO中又加入了Reader和Writer。就是为了能让上层直接面对你所需要的信息,即:字符(char);同时,提供统一的接口解决编码问题――想想看如果以上面String的形式来解决编码问题将会是一件多么可怕的事情~
一个sample:
p lic String dataReader(byte[] bytes, String charset) throws Exception {
Reader reader = new InputStreamReader(new ByteArrayInputStream(bytes), charset);
int c;
String result = “”
while( (c = reader.read()) != -1) {
result += (char)c;
}
reader.close();
return result;
}
p lic byte[] dateWriter(String val, String charset) throws Exception {
ByteArrayOutputStream out = new ByteArrayOutputStream(1024);
Writer writer = new OutputStreamWriter(out, charset);
char[] chars = val.toCharArray();
for (int i = 0; i < chars.length; i++) {
char c = chars[i];
writer.write(c);
}
writer.flush();
writer.close();
return out.toByteArray();
}
上面sample与前面的从String获取byte数组和从byte数组生成String功能是一样的。流的实现虽然复杂,但是因为流抽象,所以可以很容易的替换为其他数据来源(如文件,网络等),而不用更改相关的处理代码。
为什么是“?”号
编码转换出问题时,最常见的是一个“?”。原因是当出现Java不认识的编码时(即UTF-16不能编码),则对应为一个“\ffd”,对应“?”号。此时再转换为其他部分编码时,则为“3F”。
神奇的“ISO-8859-1”
其实并不神奇,只是有点特殊而已。此编码只针对单字节(一个byte)进行编码,所以编码具有还原性。即不论何种编码的byte数组,使用此编码编码后,再使用此编码解码,可以还原到原来的byte数组。这是其他编码方式所不具备的。
bit、byte、位、字节、汉字、字符
package com.suypower.chengyu.test;?
?
public class ByteTest {?
?
??? /**
???? * byte 8 bits -128 - + 127
???? * 1 bit = 1 二进制数据
???? * 1 byte = 8 bit
???? * 1 字母 = 1 byte = 8 bit(位)
???? * 1 汉字 = 2 byte = 16 bit
???? */?
??? public static void main(String[] args) {?
??????? // TODO Auto-generated method stub?
??????? byte b1 = 127;?
??????? byte b2 = -128;?
??????? byte b3 = 'a';?
??????? byte b4 = 'A'; // 一个字母 = 1 byte = 8 bit?
//????? byte b5 ='aa';? 这就错了?
//????? byte b6 ='中'; 这就错了 一个汉字 2个字节 16bit?
??????? short s1 = '啊'; // 一个汉字 2个字节 16bit short 是 16 bit位的?
//????? short s2 = '汉字';? // 2个汉字 4个字节 32 bit int 是32 bit的?
//????? int i1 = '汉字';? 但是 int 是数字类型的 , char 是 16 bit的 = 2 byte = 一个汉字?
??????? char c1 = '汗';?
//????? byte 转换 string?
??????? String string = "中文";?
??????? byte by[] = string.getBytes();?
??????? String str = new String(by);?
??????? System.out.println("str="+str);?
??? }?
?
}?
==================================================================================?
?
[Java-原创] bit、byte、位、字节、汉字、字符?
bit、byte、位、字节、汉字的关系?
?
?
??????? 1 bit???? = 1? 二进制数据?
??????? 1 byte? = 8? bit?
??????? 1 字母 = 1? byte = 8 bit?
??????? 1 汉字 = 2? byte = 16 bit?
?
?
1. bit:位?
??? 一个二进制数据0或1,是1bit;?
?
2. byte:字节?
??? 存储空间的基本计量单位,如:MySQL中定义 VARCHAR(45)? 即是指 45个字节;?
??? 1 byte = 8 bit?
?
3. 一个英文字符占一个字节;?
??? 1 字母 = 1 byte = 8 bit?
?
4. 一个汉字占2个字节;?
??? 1 汉字 = 2 byte = 16 bit?
?
5. 标点符号?
??? A>.? 汉字输入状态下,默认为全角输入方式;?
??? B>.? 英文输入状态下,默认为半角输入方式;?
?
??? C>.? 全角输入方式下,标点符号占2字节;?
??? D>.? 半角输入方式下,标点符号占1字节;?
?
??? 故:汉字输入状态下的字符,占2个字节 (但不排除,自己更改了默认设置);?
??????????? 英文输入状态下的字符,占1个字节 (但不排除,自己更改了默认设置);