网络编程一直是经久不衰的话题,今天就网络编程里面一些问题做个总结,由于UDP相对于TCP的处理问题比较简单,所以这次总结的都是有关TCP的。
很多人认为单台服务器的最大TCP连接数是65536也就是受限于服务器的端口的数量 如果服务器想开6W以上的TCP连接就要绑定多个IP。其实这是一个重大的错误认识,其实按照TCP/IP协议的规定,确定一个连接的唯一标识是一个4元组 <本地IP,本地端口,远程IP,远程端口>,因为服务器绑定的端口和IP是固定的(一般进程都只绑定一个端口和IP),所以决定连接的因素就是客户机器的远程IP和远程端口 ,与服务器端口数量根本没有任何关系,也就是说客户机的IP范围和端口号范围才是决定连接的重要因素,我们知道IP地址的范围是2^32个(这里IP和端口不考虑保留问题),端口的数量是2^16个 那么服务器保持的最大连接数的理论值是2^32*2^16=2^48 。不过,难道服务器端真的能开那么多连接么,答案是要看服务器有多少物理内存。也就是说物理内存的大小才是决定服务器能开多少连接的决定因数(当然也和操作系统的设置有关 例如:最大文件句柄的数量,但总体来说是受限于物理内存),如果只有1G的物理内存想开100W的连接这是不可能的。我们知道建立一个socket连接和打开一个文件一样,是由操作系统建立一个文件句柄,文件句柄指向一个称为文件对象的windows内核对象 ,创建文件对象的数量决定了TCP的最大连接数,也可以这么认为:对于有限的资源 服务器最大的TCP连接数是操作系统能打开文件的最大数量,如果系统资源足够大时那么最大就是2^48。
为了证明服务端的I连接数P和端口没有关系 我写了一个测试程序,该程序为了屏蔽线程栈消耗的内存采用了.net 封装好的IOCP的方式。
客户端测试机使用了3台普通的PC机 ,三台台器分别与服务器保持5W,4W,1W个连接,统计服务端的连接数是否是10W。
程序代码如下:
1. 服务端代码:
class="csharpcode"> /// <summary> /// IOCP soket /// </summary> class Server { private Socket connSocket; //统计连接总数 private static int count; public Server() { connSocket = new Socket(SocketType.Stream, ProtocolType.Tcp); IPAddress ip = IPAddress.Parse("192.168.1.123"); IPEndPoint endPoint = new IPEndPoint(ip, 6530); connSocket.Bind(endPoint); connSocket.Listen(50000); } /// <summary> /// 接收客户端连接 /// </summary> public void Start() { IAsyncResult acceptResult=null; acceptResult = connSocket.BeginAccept(AcceptCallback, connSocket); } private void AcceptCallback(IAsyncResult ar) { Socket accetpSocket = ar.AsyncState as Socket; if(accetpSocket==null) { return; } Socket receiveSocket= accetpSocket.EndAccept(ar); //打印连接数 count++; Console.WriteLine("连接数:{0}",count); Start(); Receieve(receiveSocket); } /// <summary> /// 接收发送的数据 /// </summary> /// <param name="receiveSocket">接收数据的socket</param> private void Receieve(Socket receiveSocket) { byte[] buffer = new byte[28]; receiveSocket.BeginReceive(buffer, 0, buffer.Length, SocketFlags.None, (state) => { Socket receive = state.AsyncState as Socket; try { int length = receive.EndReceive(state); Console.WriteLine(Encoding.Unicode.GetString(buffer)); Receieve(receive); } catch (SocketException socketEx) { receive.Dispose(); } }, receiveSocket); } }
2. 客户端代码:
/// <summary> /// 测试客户端 /// </summary> class Program { static List<Socket> socketList = new List<Socket>(); static void Main(string[] args) { for (int i = 0; i < 40000;i++) { Socket socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp); int port = 6530; IPAddress ip = IPAddress.Parse("192.168.1.123");//本地 socket.Connect(ip, port); socketList.Add(socket); } Console.ReadKey(); } }
3.测试结果:
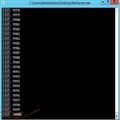
(1)Server运行结果:

图3.1
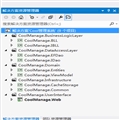
(2)Tcpview监视的连接:

图3.2
(3)server占用资源情况:

图3.3
根据图3.1的结果可以看出, 服务端接受的连接数为10W ,所以说 最大TCP连接数与服务端的端口的数量没关系,而且根据图3.2得知服务端的端口是保持不变的,变的只是客户端的IP和端口,所以一个连接的唯一标识就是一个4元组 <本地IP,本地端口,远程IP,远程端口>。
进一步分析,我们假定该程序所有的内存都是连接占用的,根据图3.3可以看出10W个连接占用了 200 M内存,也就是每个连接占用了 2kb 在物理内存4G的32操作系统下开起连接数最大约为100W(用户模式使用了2G的寻址空间),但是即使有4G的物理内存也未必能开启50W个连接,因为在内核模式的地址空间分为分页内存池和非分页内存池(用户模式下总是分页的),文件对象这个windows内核对象是存储在内核模式下的非分页内存池,所谓非分页内存池就是该内存区始终在物理内存而不会在磁盘文件的页交换文件中,而内核模式的分页内存池也占用了一部分物理内存,导致整个内核模式的非分页内存池不能达到2G,所以100W个连接在32位操作系统是也无法开启。那么在64位操作系统上,理论上内存大的话是没有限制的,亚马逊曾经测试过node.js的连接数 100W个连接占用了16G的内存(.net程序没有测过100W的内存情况,所以4G的100W个连接只是推测,和实际情况可能差别较大) http://blog.caustik.com/2012/08/19/node-js-w1m-concurrent-connections/。
最后还要补充一句:服务器的性能和处理多少连接数没关系,即使100W个连接只是连接而不发送数据,服务器只是浪费点内存,如果100W个同时发送数据,那么服务器可能会处理不过来,处理不过来只是相对于而言,如果发送的每个连接消息非常小,服务器的配置好,而且服务端处理消息的逻辑相对简单,那可能会处理过来,相反 一个连接只发送一条消息,但服务器处理这条消息的逻辑非常复查,比如要做个几分钟的大型的计算,那么服务器也是处理不过来的。所以对于服务端来说 一味的追求多少连接数是不可取的,主要还是要衡量处理消息的逻辑。
TCP/IP协议限制了每个连接的最大传输速度。而且使各大连接的速度保持一直,所以说不考虑服务端的处理速度等其他因数,多个连接的发送数据速度要比单个连接的快,所以迅雷采用了多线程下载的方式。当然,我们实际开发中要采用多少个连接需要根据服务端对每个连接的处理能力进行测算,找出一个平衡点。
在.net平台之间进行通讯时可以忽略主机字节序的问题,.net平台统一采用了小端法,如果需要跨平台传输,就需要统一字节序,一般有两种方案:
1.采用字符串的形式,注意UNICODE编码的字符串占2个字节,所以同样会有字节序的问题,所以应该使用ANSCI的字符串。
2.都采用大端或小端,在报文里用一个字节做个表识来表明主机的字节序。
因为TCP属于流式传输,所以没有数据边界,所以我们不知道每次发送数据的长度,所以每次接受数据时可能是两个包或者可能是一个不完整的包,这就我们需要处理TCP断包和粘包这两个场景,一般解决方案是在头部前4个字节来标识整个数据包的长度,接受数据时先接受4个字节的长度,然后根据解析出的包长进行循环接收直到数据包接完整为止,注意接收前4个字节的包长是也要进行循环接受直到接满4个字节。
有时候数据包传输过程中会出现错误,一般都是校验CRC是否完整来校验包的正确性。一旦数据包出现错误一般有两种测试处理:第一是直接丢弃整个包, 该方法简单但可能会失去某些比较重要的数据。 第二个是对根据报文对整个包进行遍历把可能没有错误的数据保持下来,但是该方案比较麻烦。
最后一句感言:无论什么平台和语言,基础知识都是通用的,制约发展的因素不是我们会哪几种语言,而是我们运用基础知识去解决实际问题的能力。