一晃眼,有两年没有写博客了,回顾前两年,各种奔波,各种忙碌,也有不少的收获。从今天开始,我要把这些收获都分享在这里。
其实这两年,对我影响最大的是开发流程。总所周知,一个好的开发流程,对于项目的进行,更新和维护都起着至关重要的作用。Scrum适用于一些开发周期长,需求不明确,或者随时间渐进明确,频繁更新的项目。然而,现在国内的一些公司,甚至一些大公司,都对这块不太重视,或者做得不够透彻。从而程序猿们天天加班,苦不堪言。
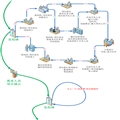
我们先来看张我通过实际经验画的图流程图,红色圈圈出来的是我认为比较容易忽略的部分,接下来一一说明。

1/2、项目决定启动后,第一步就是产品组准备需求,整理出需求文档。这个需求文档是需要多次会议协商总结出的。在需求前期,产品组可以自由发挥,把对产品的任何要求尽量详细地列出来,细节方面列不完整也没关系,但是对于产品的最终呈现出的效果,大的方向,要有一个彻底明确的说明,因为这个可能直接关系到产品架构的设计;然后进入需求中期,这个时候一定要引入技术经理以及技术主力,需要从技术角度去评估需求的可行性以及性价比,这让技术部门能够基本了解大的架构方向,(我曾经就有碰到过一个项目,由于产品组在美国,开发组在国内,产品组在没有和开发组彻底沟通的情况下,就把需求和客户达成共识,这之后使得我们技术部门十分被动,结果就是无法在规定时间上线,损失是小,在客户面前失信是大!);最后在需求后期,就可以出具项目需求初稿,这个初稿需要产品组根据时间要求以及客户要求,进行优先级划分,并将其划分为多个模块,分配给各个开发经理,制定Story或者backlog,再让开发经理细分task,分配给各个程序猿,从时间的角度,需要设定Sprint,并将各个story分配到各个Sprint中,一个Sprint的周期一般是2个星期(10个工作日),遇特殊情况可延长到3个星期。这个过程中,最关键的是怎么规划Sprint,这个时候,对story时间的估算是非常关键的。我们以前都是程序猿们和产品经理坐在一起,为每个story一一估算时间。比如说一个story由2个人完成,2个人当然需要在事先了解需求,然后在对方不知道的情况下,分别估算对这个2个人完成的story需要花费多少天/人次,如果两个人时间接近,就去较大的那个天数作为估算的时间,比如一个人估3天,一个人估2天,那么这个story估算的总时间就是3天/人*2人=6天;如果两个人的差距相当大,比如一个人估了2天,另外个人估了10天,那就有需要让两个人说明原因,在排除了干扰因素后,再次估算,最后得出一个合理的时间。项目经理需要根据估算的总时间来安排Sprint里的story。
这些都准备完成后,就可以进行项目开发阶段了。
3、因为我是微软平台的苦B程序猿,所以我接下来用到的都是微软的工具。首先要有一个代码版本控制软件,我要在这里说的是TFS。微软的TFS有两个版本,一个叫Team Foundation Server,一个叫Team Foundation Service,小弟都用过,所以来说明下两者的区别:Server版需要公司用自己的服务器部署,比较适合局域网内开发的项目,当然也可以部署在公网,优点是可以最大程度的customize;Service版是部署在微软云上,由微软托管的,比较适合跨区域中小型公司(缺少硬件支持的),优点是方便,和office365账号绑定,公网也可以访问,缺点是无法自定义流程模板。其他功能都是一样的。其实无论那个版本的TFS,功能都是非常强大的,完全可以满足敏捷开发项目需要。我曾听有人抱怨TFS只能给程序猿用,项目组又不装VS,不用用它来开task啊,开bug什么的,然后又去买了JIRA什么的专门给项目组用的流程控制工具,其实没必要,TFS有个service portal,类似于sharepoint的站点,可以用它来给项目组用,两个版本都有,非常好用。当然JIRA也是非常不错的,我们当时也是两个一起用,JIRA在自定义流程上面还是相当不错的,我们用JIRA来做部署流程控制以及运维流程控制等与代码本身关联不深的流程控制。
TFS在对代码版本及质量管理方面是很有优势的,我们会把sprint,story,task等等统统在开发阶段开始前录入TFS,这些都是TFS默认的模板,我们也可以自己更换或者修改模板,遗憾的是service版没法改。具体怎么修改可以参考MSDN。
然后我们可以通过规则,强制在check in代码的时候绑定task/bug/issue,以及强制写comment以及check in notes,这些都相当重要。当然,代码不能随随便便就能check in啊,最好需要有个人review,这个时候,我们可以先Shelve代码,然后可以指定一个人来给你review代码,review代码的人可以通过TFS自带的比较工具,比较shelve的代码和最新的代码间的区别,也可以给代码片段写comment,最后决定是否可以提交和需要打回去,重新shelve。有人会觉得,这个好麻烦啊,不是会影响进度。我要说的是,如果没有这个环节,或许你可以很快速的完成开发,但别忘了,代码不是写完就算了的,代码的质量也是相当重要的,谁都不想,项目进入测试环节因为某个不该发生的问题而影响一轮测试,也不想在项目上线之后,因为性能问题,再来review所有代码,找到性能瓶颈......
顺便说下测试,测试不比开发轻松,一般测试分为smoke test,regression test,fuzz test,load test/performance test,security test。前两个不多说了,很熟悉了,后面三个很容易被忽视,但是却非常重要。有一句真理:任何一个软件,永远都存在bug,任何一种测试都无法把所有bug都找出来!因此,我们需要在测试阶段尽可能地将简单明显的bug统统找出来,这样剩下的只是在特定情况下才会特别发生的bug。smoke test和regression test是为了找简单明显的bug,而fuzz,load,security等等测试是用来找出特定情况下的bug。fuzz能够很好地验证软件的健壮成都,它通过随机无序的任意输入,测试系统的内部应对及输出;load能够让系统在某个压力下测试系统的稳定性能,从而评估该系统/软件可以给多少人用,需要多少服务器,以及找出性能瓶颈,从而优化代码;安全测试可以测试系统的安全性,关于安全微软还有一套完整的流程叫SDL,就不详述了。我们以前公司一直想做自动化测试,fuzz和load是可以自动化的,但是功能性测试做自动化比较困难,VS自身有针对web服务的自动化测试项目模板,有兴趣可以了解下。但个人觉得还不算理想中那种自动化。反正有大批测试妹子,全自动化了,公司里不就少了很多妹子,哈哈,扯远了。。。
再说下发布,在分布式的发布体系下,比较头疼的是,从QA到UAT,在到Staging和Production,各个环境可能需要不同的配置参数,尤其是SOA的系统,在分布式部署的时候,服务地址的配置通常非常头疼,最简单的方法是用配置文件的自动转换功能,也有公司自己做配置管理工具的,也有把配置移到数据库的。个人觉得,有条件的可以自己开发套适合自己的配置工具,但是我作为一个从简主义者,我针对SOA系统,我的方法是这样的:首先,在每个环境的服务器集群之中,搞一台机器专门做内部的DNS服务器,我们在dns服务器上为每一个需要分布式部署的service定义一个内部域名,然后在配置文件中,都用这些预先定义好的内部域名,如果需要本地测试,可以修改自己机器的host文件,map到127.0.0.1或者具体的局域网IP地址,包括数据库地址也是可以这么做(这种方法对Azure SQL无效),然后发布到任何一个环境都不需要改跟地址有关的配置;对于一些跟环境相关的其他应用程序配置,本人建议存储到数据库或者做一个专门的配置服务。当在Staging上发布并测试完成后,Production就不要再发布了,通过交换绑定的IP地址来实现切换,具体如何实现是IT的事情,这里不说了。
4、终于一个阶段开发完成,可以顺利进入测试阶段了,这个时候,下个阶段的新需求就又来了,然后又是重复的步骤,估时间,sprint,story,写代码,测试,发布。
5、当产品上线后,肯定会遇到不少特定情况出现的bug,为了发现bug,要有监控系统,这又是一个大话题,暂时略过,然后发现问题后,要能够重现,然后需要评估问题的严重程度,然后根据协商结果,决定是否需要立马修复,还是进入下个发布周期修复,如果是需要立马修复的就要做hotfix,开maintainence window,走一边UAT-〉Staging-〉Production的过程,QA可以不走,因为有可能下个阶段的开发已经在QA上测试,如果下个阶段的开发已经在UAT上了,那么这么急的hotfix也没有意义了,如果下个阶段已在UAT,prod又出现无法运行的后果,那么把production再切会之前的在staging上的版本吧。关于数据库,staging和prod应该是需要工具来同步的。
先说那么多,很多细节还是需要不同的团队不同的人员做一些调整。总结的不对之处,还望指正!