 class="topic_img" alt=""/>
class="topic_img" alt=""/>
针对目前火爆的2048游戏,有人实现了一个 AI 程序,可以以较大概率(高于 90%)赢得游戏,并且作者在 stackoverflow 上简要介绍了 AI 的算法框架和实现思路。但是这个回答主要集中在启发函数的选取上,对 AI 用到的核心算法并没有仔细说明。这篇文章将主要分为两个部分,第一部分介绍其中用到的基础算法,即 Minimax 和 Alpha-beta 剪枝;第二部分分析作者具体的实现。

基础算法
2048 本质上可以抽象成信息对称双人对弈模型(玩家向四个方向中的一个移动,然后计算机在某个空格中填入 2 或4)。这里“信息对称”是指在任一时刻对弈双方对格局的信息完全一致,移动策略仅依赖对接下来格局的推理。作者使用的核心算法为对弈模型中常用的带 Alpha-beta 剪枝的 Minimax。这个算法也常被用于如国际象棋等信息对称对弈 AI 中。
下面先介绍不带剪枝的 Minimax。首先本文将通过一个简单的例子说明 Minimax 算法的思路和决策方式。
现在考虑这样一个游戏:有三个盘子A、B和C,每个盘子分别放有三张纸币。A放的是1、20、50;B放的是5、10、100;C放的是1、5、20。单位均为“元”。有甲、乙两人,两人均对三个盘子和上面放置的纸币有可以任意查看。游戏分三步:
其中甲的目标是最后拿到的纸币面值尽量大,乙的目标是让甲最后拿到的纸币面值尽量小。
下面用 Minimax 算法解决这个问题。
一般解决博弈类问题的自然想法是将格局组织成一棵树,树的每一个节点表示一种格局,而父子关系表示由父格局经过一步可以到达子格局。Minimax 也不例外,它通过对以当前格局为根的格局树搜索来确定下一步的选择。而一切格局树搜索算法的核心都是对每个格局价值的评价。Minimax 算法基于以下朴素思想确定格局价值:
上面的表述有些抽象,下面看具体示例。
下图是上述示例问题的格局树:

注意,由于示例问题格局数非常少,我们可以给出完整的格局树。这种情况下我可以找到 Minimax 算法的全局最优解。而真实情况中,格局树非常庞大,即使是计算机也不可能给出完整的树,因此我们往往只搜索一定深度,这时只能找到局部最优解。
我们从甲的角度考虑。其中正方形节点表示轮到我方(甲),而三角形表示轮到对方(乙)。经过三轮对弈后(我方-对方-我方),将进入终局。黄色叶结点表示所有可能的结局。从甲方看,由于最终的收益可以通过纸币的面值评价,我们自然可以用结局中甲方拿到的纸币面值表示终格局的价值。
下面考虑倒数第二层节点,在这些节点上,轮到我方选择,所以我们应该引入可选择的最大价值格局,因此每个节点的价值为其子节点的最大值:
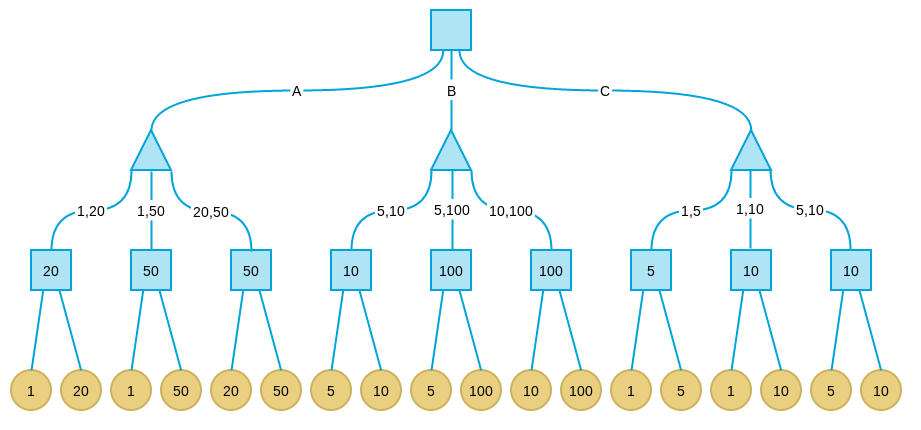
这些轮到我方的节点叫做 max 节点,max 节点的值是其子节点最大值。
倒数第三层轮到对方选择,假设对方会尽力将局势引入让我方价值最小的格局,因此这些节点的价值取决于子节点的最小值。这些轮到对方的节点叫做 min 节点。
最后,根节点是 max 节点,因此价值取决于叶子节点的最大值。最终完整赋值的格局树如下:
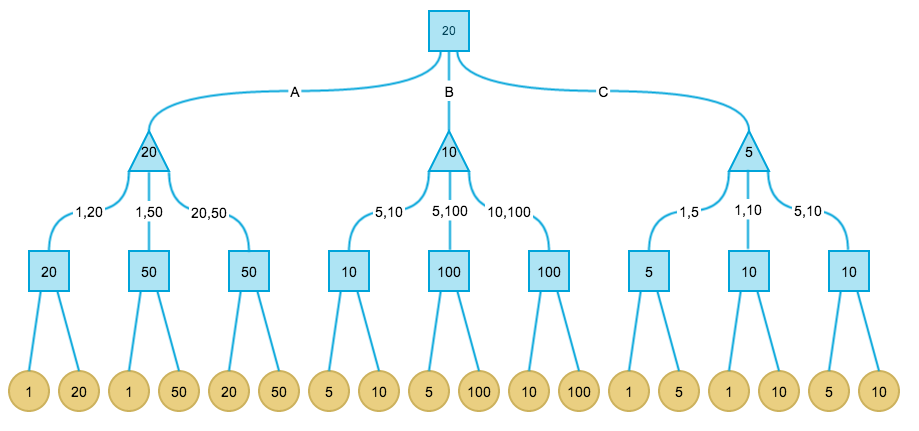
总结一下 Minimax 算法的步骤:
在上面的例子中,根节点的价值为 20,表示如果对方每一步都完美决策,则我方按照上述算法可最终拿到 20 元,这是我方在 Minimax 算法下最好的决策。格局转换路径如下图红色路径所示:

对于真实问题中的 Minimax,再次强调几点:
简单的 Minimax 算法有一个很大的问题就是计算复杂性。由于所需搜索的节点数随最大深度呈指数膨胀,而算法的效果往往和深度相关,因此这极大限制了算法的效果。
Alpha-beta 剪枝是对 Minimax 的补充和改进。采用 Alpha-beta 剪枝后,我们可不必构造和搜索最大深度D内的所有节点,在构造过程中,如果发现当前格局再往下不能找到更好的解,我们就停止在这个格局及以下的搜索,也就是剪枝。
Alpha-beta 基于这样一种朴素的思想:时时刻刻记得当前已经知道的最好选择,如果从当前格局搜索下去,不可能找到比已知最优解更好的解,则停止这个格局分支的搜索(剪枝),回溯到父节点继续搜索。
Alpha-beta 算法可以看成变种的 Minimax,基本方法是从根节点开始采用深度优先的方式构造格局树,在构造每个节点时,都会读取此节点的 alpha 和 beta 两个值,其中 alpha 表示搜索到当前节点时已知的最好选择的下界,而 beta 表示从这个节点往下搜索最坏结局的上界。由于我们假设对手会将局势引入最坏结局之一,因此当 beta 小于 alpha 时,表示从此处开始不论最终结局是哪一个,其上限价值也要低于已知的最优解,也就是说已经不可能此处向下找到更好的解,所以就会剪枝。
下面同样以上述示例介绍 Alpha-beta 剪枝算法的工作原理。我们从根节点开始,详述使用 Alpha-beta 的每一个步骤:
搜索第四层,到达叶子节点,采用评价函数得到此节点的评价值为1。
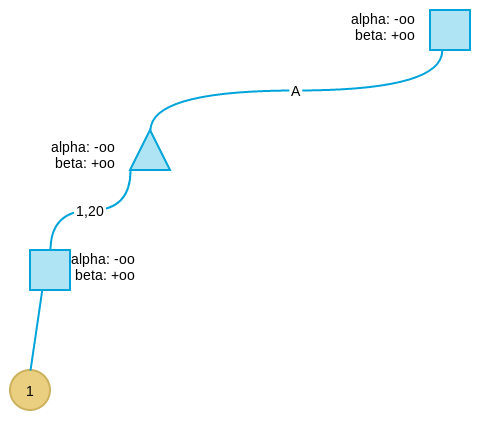
此叶节点的父节点为 max 节点,因此更新其 alpha 值为1,表示此节点取值的下界为1。
由于其父节点(第二层最左节点)为 min 节点,因此更新其父节点 beta 值为 20,表示这个节点取值最多为 20。
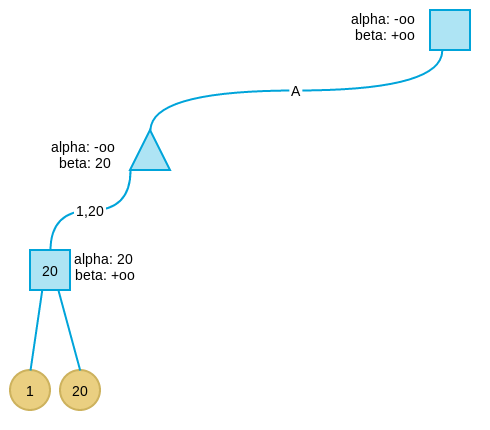
搜索第二层最左节点的第二个孩子及其子树,按上述逻辑,得到值为 50(注意第二层最左节点的 beta 值要传递给孩子)。由于 50 大于 20,不更新 min 节点的 beta 值。
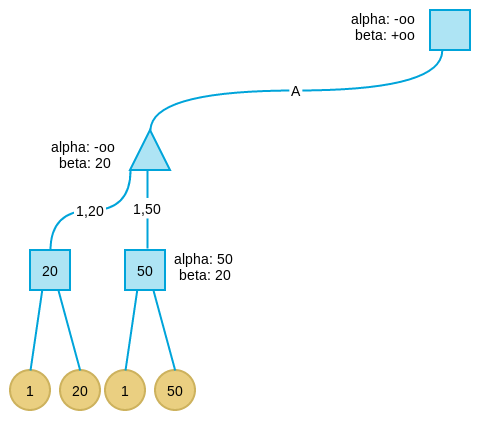
搜索第二层最左节点的第三个孩子。当看完第一个叶子节点后,发现第三个孩子的 alpha=beta,此时表示这个节点下不会再有更好解,于是剪枝。
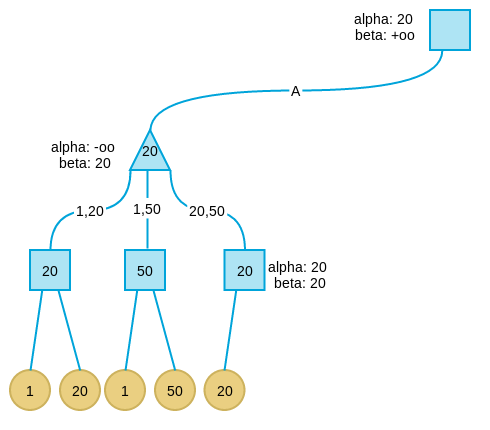
继续搜索B分支,当搜索完B分支的第一个孩子后,发现此时B分支的 alpha 为 20,beta 为 10。这表示B分支节点的最大取值不会超过 10,而我们已经在A分支取到 20,此时满足 alpha 大于等于 beta 的剪枝条件,因此将B剪枝。并将B分支的节点值设为 10,注意,这个 10 不一定是这个节点的真实值,而只是上线,B节点的真实值可能是5,可能是1,可能是任何小于 10 的值。但是已经无所谓了,反正我们知道这个分支不会好过A分支,因此可以放弃了。
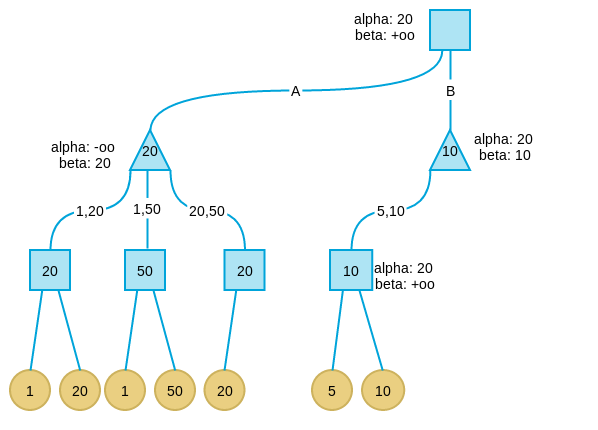
在C分支搜索时遇到了与B分支相同的情况。因此讲C分支剪枝。

此时搜索全部完毕,而我们也得到了这一步的策略:应该走A分支。
可以看到相比普通 Minimax 要搜索 18 个叶子节点相比,这里只搜索了 9 个。采用 Alpha-beta 剪枝,可以在相同时间内加大 Minimax 的搜索深度,因此可以获得更好的效果。并且 Alpha-beta 的解和普通 Minimax 的解是一致的。
针对 2048 游戏的实现
下面看一下 ov3y 同学针对 2048 实现的 AI。程序的 github 在这里,主要程序都在 ai.js 中。
上面说过 Minimax 和 Alpha-beta 都是针对信息对称的轮流对弈问题,这里作者是这样抽象游戏的:
如此 2048 游戏就被建模成一个信息对称的双人对弈问题。
作为算法的核心,如何评价当前格局的价值是重中之重。在 2048 中,除了终局外,中间格局并无非常明显的价值评价指标,因此需要用一些启发式的指标来评价格局。那些分数高的“好”格局是容易引向胜利的格局,而分低的“坏”格局是容易引向失败的格局。
作者采用了如下几个启发式指标。
单调性指方块从左到右、从上到下均遵从递增或递减。一般来说,越单调的格局越好。下面是一个具有良好单调格局的例子:

平滑性是指每个方块与其直接相邻方块数值的差,其中差越小越平滑。例如 2 旁边是 4 就比 2 旁边是 128 平滑。一般认为越平滑的格局越好。下面是一个具有极端平滑性的例子:

这个很好理解,因为一般来说,空格子越少对玩家越不利。所以我们认为空格越多的格局越好。
这个指标评价空格被分开的程度,空格越分散则格局越差。
具体来说,2048-AI 在评价格局时,对这些启发指标采用了加权策略。具体代码如下:
// try a 2 and 4 in each cell and measure how annoying it is // with metrics from eval var candidates = []; var cells = this.grid.availableCells (); var scores = { 2: [], 4: [] }; for (var value in scores) { for (var i in cells) { scores[value].push (null); var cell = cells[i]; var tile = new Tile (cell, parseInt (value, 10)); this.grid.insertTile (tile); scores[value][i] = -this.grid.smoothness () + this.grid.islands (); this.grid.removeTile (cell); } } // now just pick out the most annoying moves var maxScore =
Math.max (Math.max.apply (null, scores[2]), Math.max.apply (null, scores[4])); for (var value in scores) { // 2 and 4 for (var i=0; i<scores[value].length; i++) { if (scores[value][i] == maxScore) { candidates.push ( { position: cells[i], value: parseInt (value, 10) } ); } } }
在 2048-AI 的实现中,并没有限制搜索的最大深度,而是限制每次“思考”的时间。这里设定了一个超时时间,默认为 100ms,在这个时间内,会从 1 开始,搜索到所能达到的深度。相关代码:
// performs iterative deepening over the alpha-beta search AI.prototype.iterativeDeep = function () { var start = (new Date ()) .getTime (); var depth = 0; var best; do { var newBest = this.search (depth, -10000, 10000, 0 ,0); if (newBest.move == -1) { //console.log ('BREAKING EARLY'); break; } else { best = newBest; } depth++; } while ( (new Date ()) .getTime () - start < minSearchTime); //console.log ('depth', --depth); //console.log (this.translate (best.move)); //console.log (best); return best }
因此这个算法实现的效果实际上依赖于执行 javascript 引擎机器的性能。当然可以通过增加超时时间来达到更好的效果,但此时每一步行走速度会相应变慢。
目前这个实现作者声称成功合成 2048 的概率超过 90%,但是合成 4096 甚至 8192 的概率并不高。作者在 github 项目的 REAMDE 中同时给出了一些优化建议,这些建议包括:
参考文献



