class="topic_img" alt=""/>
class="topic_img" alt=""/>
2011 年小规模试水
这一阶段的主要工作是建立了一个小的集群,并导入了少量用户进行测试。为了满足用户的需求,我们还调研了任务调度系统和数据交换系统。
我们使用的版本是当时最新的稳定版,Hadoop 0.20.203 和 Hive 0.7.1。此后经历过多次升级与 Bugfix。现在使用的是 Hadoop 1.0.3+ 自有 Patch 与 Hive 0.9+ 自有 Patch。考虑到人手不足及自己的 Patch 不多等问题,我们采取的策略是,以 Apache 的稳定版本为基础,尽量将自己的修改提交到社区,并且应用这些还没有被接受的 Patch。因为现在 Hadoop 生态圈中还没有出现一个类似 Red Hat 地位的公司,我们也不希望被锁定在某个特定的发行版上,更重要的是 Apache Jira 与 Maillist 依然是获取 Hadoop 相关知识、解决 Hadoop 相关问题最好的地方(Cloudera 为 CDH 建立了私有的 Jira,但人气不足),所以没有采用 Cloudera 或者 Hortonworks 的发行版。目前我们正对 Hadoop 2.1.0 进行测试。
在前期,我们团队的主要工作是 ops+solution,现在 DBA 已接手了很大一部分 ops 的工作,我们正在转向 solution+dev 的工作。
我们使用 Puppet 管理整个集群,用 Ganglia 和 Zabbix 做监控与报警。
集群搭建好,用户便开始使用,面临的第一个问题是需要任务级别的调度、报警和工作流服务。当用户的任务出现异常或其他情况时,需要以邮件或者短信的方式通知用户。而且用户的任务间可能有复杂的依赖关系,需要工作流系统来描述任务间的依赖关系。我们首先将目光投向开源项目 Apache Oozie。Oozie 是 Apache 开发的工作流引擎,以 XML 的方式描述任务及任务间的依赖,功能强大。但在测试后,发现 Oozie 并不是一个很好的选择。
Oozie 采用 XML 作为任务的配置,特别是对于 MapReduce Job,需要在 XML 里配置 Map、Reduce 类、输入输出路径、Distributed Cache 和各种参数。在运行时,先由 Oozie 提交一个 Map only 的 Job,在这个 Job 的 Map 里,再拼装用户的 Job,通过 JobClient 提交给 JobTracker。相对于 Java 编写的 Job Runner,这种 XML 的方式缺乏灵活性,而且难以调试和维护。先提交一个 Job,再由这个 Job 提交真正 Job 的设计,我个人认为相当不优雅。
另一个问题在于,公司内的很多用户,希望调度系统不仅可以调度 Hadoop 任务,也可以调度单机任务,甚至 Spring 容器里的任务,而 Oozie 并不支持 Hadoop 集群之外的任务。
所以我们转而自行开发调度系统 Taurus(https://github.com/dianping/taurus)。Taurus 是一个调度系统, 通过时间依赖与任务依赖,触发任务的执行,并通过任务间的依赖管理将任务组织成工作流;支持 Hadoop/Hive Job、Spring 容器里的任务及一般性任务的调度/监控。

图 1 Taurus 的结构图
图 1 是 Taurus 的结构图,Taurus 的主节点称为 Master,Web 界面与 Master 在一起。用户在 Web 界面上创建任务后,写入 MySQL 做持久化存储,当 Master 判断任务触发的条件满足时,则从 MySQL 中读出任务信息,写入 ZooKeeper;Agent 部署在用户的机器上,观察 ZooKeeper 上的变化,获得任务信息,启动任务。Taurus 在 2012 年中上线。
另一个迫切需求是数据交换系统。用户需要将 MySQL、MongoDB 甚至文件中的数据导入到 HDFS 上进行分析。另外一些用户要将 HDFS 中生成的数据再导入 MySQL 作为报表展现或者供在线系统使用。
我们首先调研了 Apache Sqoop,它主要用于 HDFS 与关系型数据库间的数据传输。经过测试,发现 Sqoop 的主要问题在于数据的一致性。Sqoop 采用 MapReduce Job 进行数据库的插入,而 Hadoop 自带 Task 的重试机制,当一个 Task 失败,会自动重启这个 Task。这是一个很好的特性,大大提高了 Hadoop 的容错能力,但对于数据库插入操作,却带来了麻烦。
考虑有 10 个 Map,每个 Map 插入十分之一的数据,如果有一个 Map 插入到一半时 failed,再通过 Task rerun 执行成功,那么 fail 那次插入的一半数据就重复了,这在很多应用场景下是不可接受的。而且 Sqoop 不支持 MongoDB 和 MySQL 之间的数据交换,但公司内却有这需求。最终我们参考淘宝的 DataX,于 2011 年底开始设计并开发了 Wormhole。之所以采用自行开发而没有直接使用 DataX 主要出于维护上的考虑,而且 DataX 并未形成良好的社区。
2012 年大规模应用
2012 年,出于成本、稳定性与源码级别维护性的考虑,公司的 Data Warehouse 系统由商业的 OLAP 数据库转向 Hadoop/Hive。2012 年初,Wormhole 开发完成;之后 Taurus 也上线部署;大量应用接入到 Hadoop 平台上。为了保证数据的安全性,我们开启了 Hadoop 的 Security 特性。为了提高数据的压缩率,我们将默认存储格式替换为 RCFile,并开发了 Hive Web 供公司内部使用。2012 年底,我们开始调研 HBase。

图 2 Wormhole 的结构图
Wormhole(https://github.com /dianping/wormhole)是一个结构化数据传输工具,用于解决多种异构数据源间的数据交换,具有高效、易扩展等特点,由 Reader、Storage、Writer 三部分组成(如图 2 所示)。Reader 是个线程池,可以启动多个 Reader 线程从数据源读出数据,写入 Storage。Writer 也是线程池,多线程的 Writer 不仅用于提高吞吐量,还用于写入多个目的地。Storage 是个双缓冲队列,如果使用一读多写,则每个目的地都拥有自己的 Storage。
当写入过程出错时,将自动执行用户配置的 Rollback 方法,消除错误状态,从而保证数据的完整性。通过开发不同的 Reader 和 Writer 插件,如 MySQL、MongoDB、Hive、HDFS、SFTP 和 Salesforce,我们就可以支持多种数据源间的数据交换。Wormhole 在大众点评内部得到了大量使用,获得了广泛好评。
随着越来越多的部门接入 Hadoop,特别是cangku.html" target="_blank">数据仓库(DW)部门接入后,我们对数据的安全性需求变得更为迫切。而 Hadoop 默认采用 Simple 的用户认证模式,具有很大的安全风险。
默认的 Simple 认证模式,会在 Hadoop 的客户端执行 whoami 命令,并以 whoami 命令的形式返回结果,作为访问 Hadoop 的用户名(准确地说,是以 whoami 的形式返回结果,作为 Hadoop RPC 的 userGroupInformation 参数发起 RPC Call)。这样会产生以下三个问题。
(1)User Authentication。假设有账号A和账号B,分别在 Host1 和 Host2 上。如果恶意用户在 Host2 上建立了一个同名的账号A,那么通过 RPC Call 获得的 UGI 就和真正的账号A相同,伪造了账号A的身份。用这种方式,恶意用户可以访问/修改其他用户的数据。
(2)Service Authentication。Hadoop 采用主从结构,如 NameNode-DataNode、JobTracker-Tasktracker。Slave 节点启动时,主动连接 Master 节点。Slave 到 Master 的连接过程,没有经过认证。假设某个用户在某台非 Hadoop 机器上,错误地启动了一个 Slave 实例,那么也会连接到 Master;Master 会为它分配任务/数据,可能会影响任务的执行。
(3)可管理性。任何可以连到 Master 节点的机器,都可以请求集群的服务,访问 HDFS,运行 Hadoop Job,无法对用户的访问进行控制。
从 Hadoop 0.20.203 开始,社区开发了 Hadoop Security,实现了基于 Kerberos 的 Authentication。任何访问 Hadoop 的用户,都必须持有 KDC(Key Distribution Center)发布的 Ticket 或者 Keytab File(准确地说,是 Ticket Granting Ticket),才能调用 Hadoop 的服务。用户通过密码,获取 Ticket,Hadoop Client 在发起 RPC Call 时读取 Ticket 的内容,使用其中的 Principal 字段,作为 RPC Call 的 UserGroupInformation 参数,解决了问题(1)。Hadoop 的任何 Daemon 进程在启动时,都需要使用 Keytab File 做 Authentication。因为 Keytab File 的分发是由管理员控制的,所以解决了问题(2)。最后,不论是 Ticket,还是 Keytab File,都由 KDC 管理/生成,而 KDC 由管理员控制,解决了问题(3)。
在使用了 Hadoop Security 之后,只有通过了身份认证的用户才能访问 Hadoop,大大增强了数据的安全性和集群的可管理性。之后我们基于 Hadoop Secuirty,与 DW 部门一起开发了 ACL 系统,用户可以自助申请 Hive 上表的权限。在申请通过审批工作流之后,就可以访问了。
JDBC 是一种很常用的数据访问接口,Hive 自带了 Hive Server,可以接受 Hive JDBC Driver 的连接。实际上,Hive JDBC Driver 是将 JDBC 的请求转化为 Thrift Call 发给 Hive Server,再由 Hive Server 将 Job 启动起来。但 Hive 自带的 Hive Server 并不支持 Security,默认会使用启动 Hive Server 的用户作为 Job 的 owner 提交到 Hadoop,造成安全漏洞。因此,我们自己开发了 Hive Server 的 Security,解决了这个问题。
但在 Hive Server 的使用过程中,我们发现 Hive Server 并不稳定,而且存在内存泄漏。更严重的是由于 Hive Server 自身的设计缺陷,不能很好地应对并发访问的情况,所以我们现在并不推荐使用 Hive JDBC 的访问方式。
社区后来重新开发了 Hive Server 2,解决了并发的问题,我们正在对 Hive Server 2 进行测试。
有一些同事,特别是 BI 的同事,不熟悉以 CLI 的方式使用 Hive,希望 Hive 可以有个 GUI 界面。在上线 Hive Server 之后,我们调研了开源的 SQL GUI Client——Squirrel,可惜使用 Squirrel 访问 Hive 存在一些问题。
基于以上考虑,我们自己开发了 Hive Web,让用户通过浏览器就可以使用 Hive。Hive Web 最初是作为大众点评第一届 Hackathon 的一个项目被开发出来的,技术上很简单,但获得了良好的反响。现在 Hive Web 已经发展成了一个 RESTful 的 Service,称为 Polestar(https://github.com/dianping /polestar)。
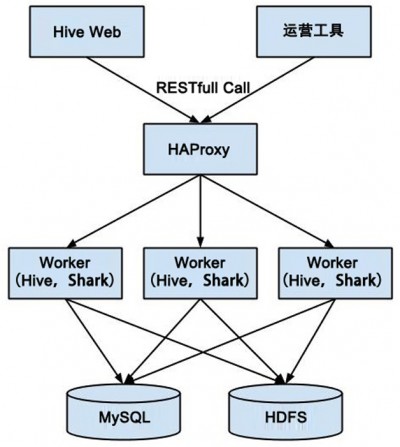
图 3 Polestar 的结构
图 3 是 Polestar 的结构图。目前 Hive Web 只是一个 GWT 的前端,通过 HAProxy 将 RESTfull Call 分发到执行引擎 Worker 执行。Worker 将自身的状态保存在 MySQL,将数据保存在 HDFS,并使用 JSON 返回数据或数据在 HDFS 的路径。我们还将 Shark 与 Hive Web 集成到了一起,用户可以选择以 Hive 或者 Shark 执行 Query。
一开始我们使用 LZO 作为存储格式,使大文件可以在 MapReduce 处理中被切分,提高并行度。但 LZO 的压缩比不够高,按照我们的测试,Lzo 压缩的文件,压缩比基本只有 Gz 的一半。
经过调研,我们将默认存储格式替换成 RCFile,在 RCFile 内部再使用 Gz 压缩,这样既可保持文件可切分的特性,同时又可获得 Gz 的高压缩比,而且因为 RCFile 是一种列存储的格式,所以对于不需要的字段就不用从I/O读入,从而提高了性能。图 4 显示了将 Nginx 数据分别用 Lzo、RCFile+Gz、RCFfile+Lzo 压缩,再不断增加 Select 的 Column 数,在 Hive 上消耗的 CPU 时间(越小越好)。
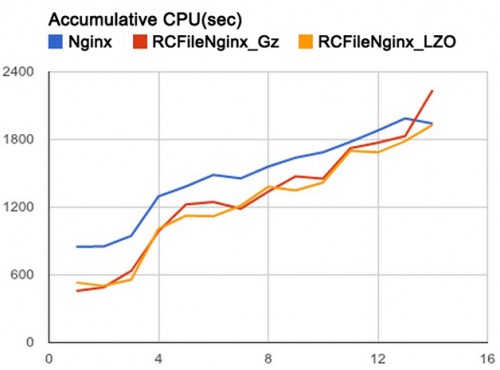
图 4 几种压缩方式在 Hive 上消耗的 CPU 时间
但 RCFile 的读写需要知道数据的 Schema,而且需要熟悉 Hive 的 Ser/De 接口。为了让 MapReduce Job 能方便地访问 RCFile,我们使用了 Apache Hcatalog。
社区又针对 Hive 0.11 开发了 ORCFile,我们正在对 ORCFile 进行测试。
随着 Facebook、淘宝等大公司成功地在生产环境应用 HBase,HBase 越来越受到大家的关注,我们也开始对 HBase 进行测试。通过测试我们发现 HBase 非常依赖参数的调整,在默认配置下,HBase 能获得很好的写性能,但读性能不是特别出色。通过调整 HBase 的参数,在 5 台机器的 HBase 集群上,对于 1KB 大小的数据,也能获得 5 万左右的 TPS。在 HBase 0.94 之后,HBase 已经优化了默认配置。
原来我们希望 HBase 集群与主 Hadoop 集群共享 HDFS,这样可以简化运维成本。但在测试中,发现即使主 Hadoop 集群上没有任何负载,HBase 的性能也很糟糕。我们认为,这是由于大量数据属于远程读写所引起的。所以我们现在的 HBase 集群都是单独部署的。并且通过封装 HBase Client 与 Master-Slave Replication,使用 2 套 HBase 集群实现了 HBase 的 HA,用来支撑线上业务。
2013 年持续演进
在建立了公司主要的大数据架构后,我们上线了 HBase 的应用,并引入 Spark/Shark 以提高 Ad Hoc Query 的执行时间,并调研分布式日志收集系统,来取代手工脚本做日志导入。
现在 HBase 上线的应用主要有 OpenAPI 和手机团购推荐。OpenAPI 类似于 HBase 的典型应用 Click Stream,将开放平台开发者的访问日志记录在 HBase 中,通过 Scan 操作,查询开发者在一段时间内的 Log,但这一功能目前还没有对外开放。手机团购推荐是一个典型的 KVDB 用法,将用户的历史访问行为记录在 HBase 中,当用户使用手机端访问时,从 HBase 获得用户的历史行为数据,做团购推荐。
当 Hive 大规模使用之后,特别是原来使用 OLAP 数据库的 BI 部门的同事转入后,一个越来越大的抱怨就是 Hive 的执行速度。对于离线的 ETL 任务,Hadoop/Hive 是一个良好的选择,但动辄分钟级的响应时间,使得 Ad Hoc Query 的用户难以忍受。为了提高 Ad Hoc Query 的响应时间,我们将目光转向了 Spark/Shark。
Spark 是美国加州大学伯克利分校 AMPLab 开发的分布式计算系统,基于 RDD(Resilient Distributed Dataset),主要使用内存而不是硬盘,可以很好地支持迭代计算。因为是一个基于 Memory 的系统,所以在数据量能够放进 Memory 的情况下,能够大幅缩短响应时间。Shark 类似于 Hive,将 SQL 解析为 Spark 任务,并且 Shark 复用了大量 Hive 的已有代码。
在 Shark 接入之后,大大降低了 Ad Hoc Query 的执行时间。比如 SQL 语句:
select host, count(1) from HIPPOLOG where dt = '2013-08-28' group by
host order by host desc;
在 Hive 执行的时间是 352 秒,而 Shark 只需要 60~70 秒。但对于 Memory 中放不下的大数据量,Shark 反而会变慢。
目前用户需要在 Hive Web 中选择使用 Hive 还是 Shark,未来我们会在 Hive 中添加 Semantic-AnalysisHook,通过解析用户提交的 Query,根据数据量的大小,自动选择 Hive 或者 Shark。另外,因为我们目前使用的是 Hadoop 1,不支持 YARN,所以我们单独部署了一个小集群用于 Shark 任务的执行。
Wormhole 解决了结构化数据的交换问题,但对于非结构化数据,例如各种日志,并不适合。我们一直采用脚本或用户程序直接写 HDFS 的方式将用户的 Log 导入 HDFS。缺点是,需要一定的开发和维护成本。我们希望使用 Apache Flume 解决这个问题,但在测试了 Flume 之后,发现了 Flume 存在一些问题:Flume 不能保证端到端的数据完整性,数据可能丢失,也可能重复。
例如,Flume 的 HDFSsink 在数据写入/读出 Channel 时,都有 Transcation 的保证。当 Transaction 失败时,会回滚,然后重试。但由于 HDFS 不可修改文件的内容,假设有 1 万行数据要写入 HDFS,而在写入 5000 行时,网络出现问题导致写入失败,Transaction 回滚,然后重写这 10000 条记录成功,就会导致第一次写入的 5000 行重复。我们试图修正 Flume 的这些问题,但由于这些问题是设计上的,并不能通过简单的 Bugfix 来解决,所以我们转而开发 Blackhole 系统将数据流导入 HDFS。目前 Blackhole 正在开发中。
总结
图 5 是各系统总体结构图,深蓝部分为自行开发的系统。

图 5 大众点评各系统总体结构图
在这 2 年多的 Hadoop 实践中,我们得到了一些宝贵经验。
作者房明,大众点评网平台架构组高级工程师,Apache Contributor。2011 年加入点评网,目前负责大数据处理的基础架构及所有 Hadoop 相关技术的研发。