==============================首先讲解DOM
解析============================
官方搞了个标准DOM,但是民间的人感觉这种方式比较占
内存,所以自己又整了一套SAX。也不是说民间搞的就比官方的好,这两种方式各有优势,用的都比较多。
他们对
XML的解析方式是完全不一样的。
DOM主要是基于一种树形的模型,
XML文档本身就是一棵树形,DOM也是按照这种树形结构来处理的,它和我们的XML文档是非常吻合的,完全一致的,DOM的解析方式是这样的:首先读取XML文档,然后在内存里面形成一棵树形的结构,这个结构就反映出了XML文档的结构,接下来就开始遍历内存里面的这棵树,从顶点开始向下找,一个个子节点遍历,提取元素内容以及属性等等。这种解析方式和XML的本意是非常吻合的。但是DOM的缺点在于:如果当前XML文档相当大的时候,比如有几千行几万行的时候,把它读到内存里面会消耗大量的内存(把它读到内存里构造出来就是一个对象了,会占用大量内存),这就是它最大的缺点,而SAX就没有这个缺陷。
根节点和根元素节点是两回事:根节点Document对象代表整个文档,根元素节点代表文档的根元素,仅仅代表这一个节点元素而已,而根节点代表整个文档,解析XML的时候都是首先要获得当前这个XML文档的根节点Document对象,它是入口。
下面是一些使用DOM解析XML的实例代码:
candidate.xml:
class="xml" name="code"><?xml version="1.0"?>
<PEOPLE>
<PERSON PERSONID="E01">
<NAME>Tony Blair</NAME>
<ADDRESS>10 Downing Street, London, UK</ADDRESS>
<TEL>(061) 98765</TEL>
<FAX>(061) 98765</FAX>
<EMAIL>blair@everywhere.com</EMAIL>
</PERSON>
<PERSON PERSONID="E02">
<NAME>Bill Clinton</NAME>
<ADDRESS>White House, USA</ADDRESS>
<TEL>(001) 6400 98765</TEL>
<FAX>(001) 6400 98765</FAX>
<EMAIL>bill@everywhere.com</EMAIL>
</PERSON>
<PERSON PERSONID="E03">
<NAME>Tom Cruise</NAME>
<ADDRESS>57 Jumbo Street, New York, USA</ADDRESS>
<TEL>(001) 4500 67859</TEL>
<FAX>(001) 4500 67859</FAX>
<EMAIL>cruise@everywhere.com</EMAIL>
</PERSON>
<PERSON PERSONID="E04">
<NAME>Linda Goodman</NAME>
<ADDRESS>78 Crax Lane, London, UK</ADDRESS>
<TEL>(061) 54 56789</TEL>
<FAX>(061) 54 56789</FAX>
<EMAIL>linda@everywhere.com</EMAIL>
</PERSON>
</PEOPLE>
DomTest1.java:
package com.shengsiyuan.xml.dom;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
/**
* 使用DOM解析candidate.xml文件(candidate.xml文件放在文件的根目录下即可)
* 这是第一个DOM解析XML文件示例(比较繁琐)
* 类: DomTest1 <br>
* 描述: TODO <br>
* 作者:
* 时间: Dec 5, 2013 3:54:13 PM
*/
public class DomTest1 {
public static void main(String[] args) throws Exception {
// step 1:获得dom解析器工厂(用它来帮助我们创建具体的解析器)
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// step 2:获得具体的dom解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// step 3:解析一个XML文档,获得Document对象(根节点)
Document document = db.parse(new File("candidate.xml"));
NodeList list = document.getElementsByTagName("PERSON");
for (int i = 0; i < list.getLength(); i++) {
// DOM解析里面获得的东西统一都是Node,需要自己根据实际情况向下类型转换,比如是一个元素就转换成Element,比如说是一个属性就转换成Attribute
Element element = (Element) list.item(i);
// 获得节点值(代码element.getElementsByTagName("NAME").item(0)是获得了NAME元素本身)
String content = element.getElementsByTagName("NAME").item(0)
.getFirstChild().getNodeValue();
System.out.println("name:" + content);
content = element.getElementsByTagName("ADDRESS").item(0)
.getFirstChild().getNodeValue();
System.out.println("address:" + content);
content = element.getElementsByTagName("TEL").item(0)
.getFirstChild().getNodeValue();
System.out.println("tel:" + content);
content = element.getElementsByTagName("FAX").item(0)
.getFirstChild().getNodeValue();
System.out.println("fax:" + content);
content = element.getElementsByTagName("EMAIL").item(0)
.getFirstChild().getNodeValue();
System.out.println("email:" + content);
System.out.println("=============================================");
}
}
}
1. DOM:Document Object Model (文档对象模型)。
2.
对于XML应用开发来说,DOM就是一个对象化的XML数据接口,一个与语言无关、与平台无关的标准接口规范【接口都是一样的,但是不同语言(比如java、.net等)实现的方式是不一样的,不同的实现方式完成的功能是一样的。不同语言都有自己的一套实现方式,来处理XML文档。】
3. 要严格区分XML 文档树中的根结点与根元素结点:
根节点(Document)代表的是XML文档本身,是我们解析XML文档的入口,而根元素结点则表示XML文档的根元素,它对应于XML文档的Root。
4. JAXP(Java API for XML Parsing):用于
XML解析的Java API。
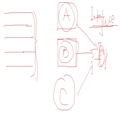
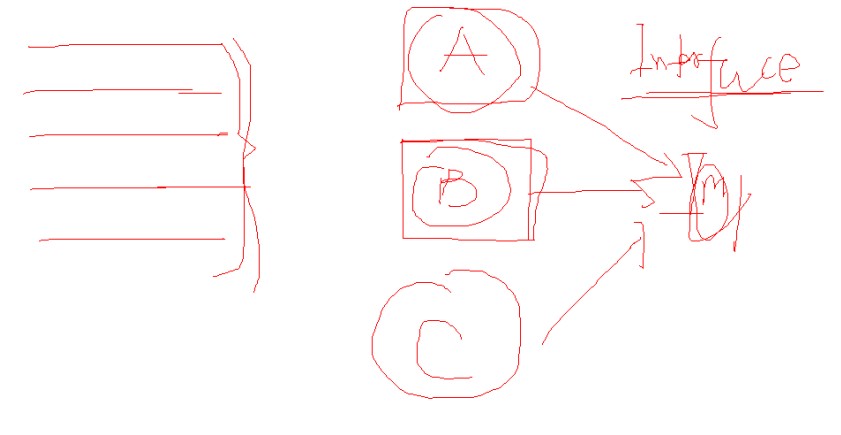
5. DocumentBuilderFactory与DocumentBuilder之间的关系【左边代表需要解析的XML代码,中间的A、B、C表示不同厂商(不同的语言都是不同的厂商提供的,他们提供的XML解析器也不同,例如java、.net等)提供的不同解析器,但是他们都会服从于Node定义的一些接口,服从W#C统一的接口的规定,每种解析器对这些接口的实现方式也不同。比如我的代码写完之后假如我原来用A解析器处理,现在想要切换到B解析器进行处理,代码一行都不用改,因为它们都服从于同一套同样的接口,只要修改一下相应的环境变量即可。同样的,你在代码里面生成的解析器DocumentBuilder类型是
什么样的完全是由相应的环境变量来决定的。】:
6. SAX(Simple APIs for XML),面向XML的简单APIs。
7. 使用DOM解析XML时,首先将XML文档加载到内存当中,然后可以通过随机的方式访问内存中的DOM树;SAX是基于事件而且是顺序执行的,一旦经过了某个元素,我们就没有办法再去访问它了,SAX不必事先将整个XML文档加载到内存当中,因此它占据内存要比DOM小,对于大型的XML文档来说,通常会使用SAX而不是DOM进行解析。
8. SAX也是使用的
观察者模式(类似于GUI中的事件)。
DOM的四个基本接口(用的
最多):Document、Node、NodeList、NamedNodeMap。
下面是DOM解析的一些示例:
student.xml:
<?xml version="1.0" encoding="UTF-8"?>
<学生名册>
<学生 学号="1">
<姓名>张三</姓名>
<性别>男</性别>
<年龄>20</年龄>
</学生>
<学生 学号="2">
<姓名>李四</姓名>
<性别>女</性别>
<年龄>19</年龄>
</学生>
<学生 学号="3">
<姓名>王五</姓名>
<性别>男</性别>
<年龄>21</年龄>
</学生>
</学生名册>
DomTest2.java:
package com.shengsiyuan.xml.dom;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomTest2 {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(new File("student.xml"));
// System.out.println(doc.getXmlEncoding());
// System.out.println(doc.getXmlVersion());
// System.out.println(doc.getXmlStandalone());
// 获得文档根元素节点
Element root = doc.getDocumentElement();
System.out.println(root.getTagName());
// 获得根元素下面的孩子列表(对于XML来说,注意:空格也是作为孩子的,元素前后的空格都算作孩子,根据下面孩子列表的个数就能看出来,是7个)
NodeList list = root.getChildNodes();
System.out.println(list.getLength());
for (int i = 0; i < list.getLength(); i++) {
// 打印出节点名称
// 一旦循环到文本,list.item(i)一定是#Text的一个具体对象。自己去重点查看Node类的API文档里面有一个表格,详细介绍了根据节点类型的不同nodeName、nodeValue
// 和 attributes 的取值。
System.out.println(list.item(i).getNodeName());
}
System.out.println("------------------------------------------------");
for (int i = 0; i < list.getLength(); i++) {
// 获得特定的一个节点
Node n = list.item(i);
// 打印节点类型和节点值。节点类型是一个常量数值(通过API文档详细查看),值有比如ELEMENT_NODE、TEXT_NODE等。
System.out.println(n.getNodeType() + " : " + n.getNodeValue());
}
System.out
.println("---------------------------------------------------");
for (int i = 0; i < list.getLength(); i++) {
Node n = list.item(i);
// 获得节点文本的内容,这个属性应用于不同的节点类型返回的值也是不同的(查看API文档)。如果是一个元素就将元素的文本内容打印出来。
System.out.println(n.getTextContent());
}
System.out.println("-----------------------------------------");
NodeList nodeList = doc.getElementsByTagName("学生");
System.out.println(nodeList.getLength());
for (int i = 0; i < nodeList.getLength(); i++) {
// 获得属性的Map对象
NamedNodeMap nnm = nodeList.item(i).getAttributes();
// nnm.item(0)是获得属性下面的第一个节点,之后调用getNodeName()方法获得属性名字。
String attrName = nnm.item(0).getNodeName();
System.out.print(attrName);
System.out.print("=");
// 获得属性值
String attrValue = nnm.item(0).getNodeValue();
System.out.println(attrValue);
}
}
}
student.xml、DomTest3.java代码(DomTest3.java是一个通用的代码):
<?xml version="1.0" encoding="UTF-8"?>
<学生名册>
<学生 学号="1">
<姓名>张三</姓名>
<性别>男</性别>
<年龄>20</年龄>
</学生>
<学生 学号="2">
<姓名>李四</姓名>
<性别>女</性别>
<年龄>19</年龄>
</学生>
<学生 学号="3">
<姓名>王五</姓名>
<性别>男</性别>
<年龄>21</年龄>
</学生>
</学生名册>
package com.shengsiyuan.xml.dom;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Attr;
import org.w3c.dom.Comment;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 比较综合的一个例子,解析student.xml,并且在命令行里面重新的将此文件的内容打印出来
* 前提是我不知道嵌套多少层,比如学生名册里面我不知道有多少个学生,一个学生下面我不知道有多少个节点,并且比如姓名节点下面可能还有其他节点,只要有的都需要打印出来。
* 就像是之前讲到的遍历一个文件夹里面你不知道有多少个子文件夹以及文件并且你也不知道每一个子文件夹里面还有多少层。只能用递归实现。
* 用递归解析给定的任意一个XML文档并且将其内容输出到命令行上
* 类: DomTest3 <br>
* 描述: TODO <br>
* 作者:
* 时间: Dec 6, 2013 11:11:32 AM
*/
public class DomTest3 {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory ddf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = ddf.newDocumentBuilder();
Document doc = db.parse(new File("student.xml"));
// 获得根元素
Element root = doc.getDocumentElement();
parseElement(root);
}
/**
* 自定义方法,用来解析XML
* 方法: parseElement <br>
* 描述: TODO <br>
* 作者:
* 时间: Dec 9, 2013 6:33:41 PM
* @param element
*/
private static void parseElement(Element element) {
// 获得元素名字
String tagName = element.getNodeName();
// 获得当前元素下面所有孩子元素构成的列表(孩子们)
NodeList children = element.getChildNodes();
System.out.print("<" + tagName);
// 获得当前元素的所有属性Map对象。element元素的所有属性所构成的NamedNodeMap对象,需要对其进行判断。
NamedNodeMap map = element.getAttributes();
if (null != map) {
for (int i = 0; i < map.getLength(); i++) {
// 获得该元素的每一个属性
Attr attr = (Attr) map.item(i);
String attrName = attr.getName();
String attrValue = attr.getValue();
System.out.print(" " + attrName + "=\"" + attrValue + "\"");
}
}
System.out.print(">");
for (int i = 0; i < children.getLength(); i++) {
// 这个node的类型不确定,需要一一进行判断(有可能是元素、文本、注释等等情况)
Node node = children.item(i);
// 获得节点的类型
short nodeType = node.getNodeType();
// 如果是元素的话就应该重复当前元素的处理过程(处理过程相同)
if (nodeType == Node.ELEMENT_NODE) {// 元素,节点
parseElement((Element) node);
} else if (nodeType == Node.TEXT_NODE) {// 文本
// 递归出口,是文本的话直接打印出来
System.out.print(node.getNodeValue());
} else if (nodeType == Node.COMMENT_NODE) {// 注释
System.out.print("<!--");
Comment comment = (Comment) node;
// 注释内容
String data = comment.getData();
System.out.print(data);
System.out.println("-->");
}
}
// 下面打印节点(元素)关闭字符串
System.out.println("</" + tagName + ">");
}
}
有关DOM解析的详细笔记查看网盘里面的xml_4.pdf,这个是上课时的课件,笔记比较详细。下载地址:http://pan.baidu.com/s/13oLSK
上面学习的都是使用DOM解析一个XML,其实使用DOM还可以创建XML
======================上面是DOM的相关讲解============================
======================下面是SAX的相关讲解============================
SAX解析和DOM解析是千差万别的。SAX解析是基于事件的,当它从上到下开始解析的时候,遇到什么了,比如遇到元素了,就触发元素相关的事件开始解析,遇到注释了就触发注释相关的事件开始解析。而DOM的特点是,当我把整个XML文件加载到内存里面的时候,这个东西就在内存里面了,我随时都可以访问,我访问什么位置什么接节点都可以。而SAX是按照顺序解析的,比如到了一个元素时我没有解析,那么过去之后我就没有机会再返回去解析了,过去了之后就没法再解析了,SAX最大的优点是占用内存小。
SAX用的也是观察者模式【重点】
自己查看API文档大概了解下SAXParser里面的一些方法以及用法。
SAX完全是基于事件来处理的,不同的事件触发不同的方法,不同的事件产生的时候,不同的方法就会得到调用。分析过的东西就不能回过头来重新分析,不能掉头,在分析的时候,遇到不同的内容就会触发不同的事件,不同的事件有不同的事件
处理器,不同
事件处理器就会得到调用,调用的时候就能获得相应的内容。
下面是SAX解析的一些实例:
SaxTest1.java:
package com.shengsiyuan.xml.sax;
import java.io.File;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/**
* SAX解析基本实例
* 类: SaxTest1 <br>
* 描述: TODO <br>
* 作者: fangguanhong fangguanhong@163.com <br>
* 时间: Dec 9, 2013 12:02:06 PM
*/
public class SaxTest1 {
public static void main(String[] args) throws Exception {
// step1:获得SAX解析器工厂实例
SAXParserFactory factory = SAXParserFactory.newInstance();
// step2:获得解析器实例
SAXParser parser = factory.newSAXParser();
// step3:开始进行解析
parser.parse(new File("student.xml"), new MyHandler());
}
}
/**
* 编写DefaultHandler的子类,重写相应的方法。
* 在开始解析xml的时候,相应事件一旦被触发调用这个类对象里面的相应方法。
* 类: MyHandler <br>
* 描述: TODO <br>
* 作者:
* 时间: Dec 9, 2013 11:52:04 AM
*/
class MyHandler extends DefaultHandler {
// 文档开始
@Override
public void startDocument() throws SAXException {
System.out.println("parse begin");
}
// 文档结束
@Override
public void endDocument() throws SAXException {
System.out.println("parse finished");
}
// 元素开始
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
System.out.println("start element");
}
// 元素结束
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
System.out.println("finish element");
}
}
SaxTest2.java:
package com.shengsiyuan.xml.sax;
import java.io.File;
import java.util.Stack;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/**
* SAX解析xml基本实例
* 仔细揣摩这个例子
* 类: SaxTest2 <br>
* 描述: TODO <br>
* 作者:
* 时间: Dec 9, 2013 12:03:10 PM
*/
public class SaxTest2 {
public static void main(String[] args) throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
parser.parse(new File("student.xml"), new MyHandler2());
}
}
class MyHandler2 extends DefaultHandler {
// 定义栈,用来存放从XML里面解析出来的字符串(后进先出)
private Stack<String> stack = new Stack<String>();
private String qname;// 姓名
private String gender;// 性别
private String age;// 年龄
// 元素开始事件触发方法
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
// 压栈
stack.push(name);
for (int i = 0; i < attributes.getLength(); i++) {
// 获得第i个属性的名称
String attrName = attributes.getQName(i);
// 获得第i个属性的值
String attrValue = attributes.getValue(i);
System.out.println(attrName + "=" + attrValue);
}
}
// 接收元素中字符数据的通知,遇到元素中字符数据事件触发方法(元素中间的空格字符串也算作是元素中的字符数据,也会触发这个方法)
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
String tag = stack.peek();// 查看栈中的元素
if ("姓名".equals(tag)) {
qname = new String(ch, start, length);
} else if ("性别".equals(tag)) {
gender = new String(ch, start, length);
} else if ("年龄".equals(tag)) {
age = new String(ch, start, length);
}
}
// 元素结束事件触发方法
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
stack.pop();// 表示该元素已经解析完毕,需要从栈中弹出
if ("学生".equals(name)) {
System.out.println("姓名:" + qname);
System.out.println("性别:" + gender);
System.out.println("年龄:" + age);
System.out.println();
}
}
}
注意:DefaultHandler类中的characters方法会将空格空白部分也作为元素内容处理,具体自己通过测试查看。
有关SAX的详细笔记查看网盘里面的xml_5.pdf,这个是上课时的课件,笔记内容和详细。下载地址:http://pan.baidu.com/s/1EejmZ

- 大小: 37.4 KB