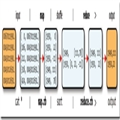
����������Ҫ����һ���й����������ݣ����ʽ���£�
0067011990999991950051507+0000+
0043011990999991950051512+0022+
0043011990999991950051518-0011+
0043012650999991949032412+0111+
0043012650999991949032418+0078+
0067011990999991937051507+0001+
0043011990999991937051512-0002+
0043011990999991945051518+0001+
0043012650999991945032412+0002+
0043012650999991945032418+0078+
������Ҫͳ�Ƴ�ÿ�������¶ȡ�
Map-Reduce��Ҫ�����������裺Map��Reduce
ÿһ������key-value����Ϊ����������
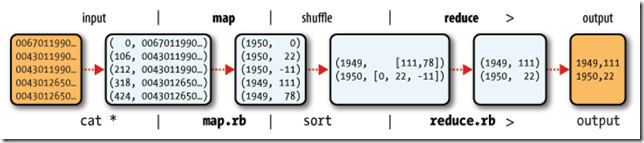
�����������������map���̣������key-value�����£�
(0, 0067011990999991950051507+0000+)
(33, 0043011990999991950051512+0022+)
(66, 0043011990999991950051518-0011+)
(99, 0043012650999991949032412+0111+)
(132, 0043012650999991949032418+0078+)
(165, 0067011990999991937051507+0001+)
(198, 0043011990999991937051512-0002+)
(231, 0043011990999991945051518+0001+)
(264, 0043012650999991945032412+0002+)
(297, 0043012650999991945032418+0078+)
��map�����У�ͨ����ÿһ���ַ������������õ���-�¶ȵ�key-value����Ϊ�����
(1950, 0)
(1950, 22)
(1950, -11)
(1949, 111)
(1949, 78)
(1937, 1)
(1937, -2)
(1945, 1)
(1945, 2)
(1945, 78)
��reduce���̣���map�����е������������ͬ��key��value�ŵ�ͬһ���б�����Ϊreduce������
(1950, [0, 22, �C11])
(1949, [111, 78])
(1937, [1, -2])
(1945, [1, 2, 78])
��reduce�����У����б���ѡ��������¶ȣ�����-����¶ȵ�key-value��Ϊ�����
(1950, 22)
(1949, 111)
(1937, 1)
(1945, 78)
�������̿�������ͼ��ʾ��
?
?
��дMap-Reduce����һ����Ҫʵ������������mapper�е�map������reducer�е�reduce������
һ����ѭ���¸�ʽ��
public interface Mapper<K1, V1, K2, V2> extends JobConfigurable, Closeable {
? void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter)
? throws IOException;
}
public interface Reducer<K2, V2, K3, V3> extends JobConfigurable, Closeable {
? void reduce(K2 key, Iterator<V2> values,
????????????? OutputCollector<K3, V3> output, Reporter reporter)
??? throws IOException;
}
?
������������ӣ���ʵ�ֵ�mapper���£�
?
public class MaxTemperatureMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
??? @Override
??? public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
??????? String line = value.toString();
??????? String year = line.substring(15, 19);
??????? int airTemperature;
??????? if (line.charAt(25) == '+') {
??????????? airTemperature = Integer.parseInt(line.substring(26, 30));
??????? } else {
??????????? airTemperature = Integer.parseInt(line.substring(25, 30));
??????? }
??????? output.collect(new Text(year), new IntWritable(airTemperature));
??? }
}
ʵ�ֵ�reducer���£�
public class MaxTemperatureReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
??? public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
??????? int maxValue = Integer.MIN_VALUE;
??????? while (values.hasNext()) {
??????????? maxValue = Math.max(maxValue, values.next().get());
??????? }
??????? output.collect(key, new IntWritable(maxValue));
??? }
}
?
����������ʵ�ֵ�Mapper��Reduce������Ҫ����һ��Map-Reduce������(Job)��������������������֣�
������JobConf����Ҫ�����˽�Hadoop����job�Ļ���ԭ����
public interface Partitioner<K2, V2> extends JobConfigurable {
? int getPartition(K2 key, V2 value, int numPartitions);
}
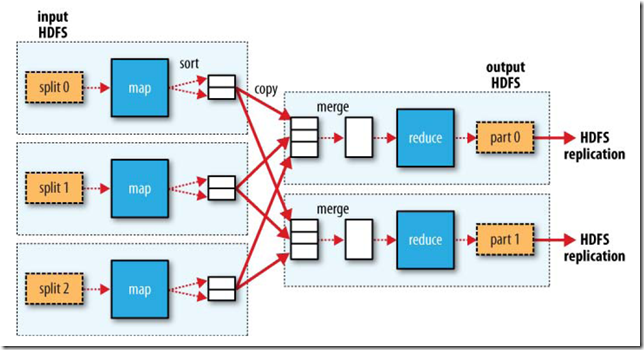
��ͼ���������Map-Reduce��Job���еĻ���ԭ����
?
?
?
������������JobConf�����кܶ������Խ������ã�
��Ȼ�������еĶ����ã�����������ӣ����Ա�дMap-Reduce�������£�
public class MaxTemperature {
??? public static void main(String[] args) throws IOException {
??????? if (args.length != 2) {
??????????? System.err.println("Usage: MaxTemperature <input path> <output path>");
??????????? System.exit(-1);
??????? }
??????? JobConf conf = new JobConf(MaxTemperature.class);
??????? conf.setJobName("Max temperature");
??????? FileInputFormat.addInputPath(conf, new Path(args[0]));
??????? FileOutputFormat.setOutputPath(conf, new Path(args[1]));
??????? conf.setMapperClass(MaxTemperatureMapper.class);
??????? conf.setReducerClass(MaxTemperatureReducer.class);
??????? conf.setOutputKeyClass(Text.class);
??????? conf.setOutputValueClass(IntWritable.class);
??????? JobClient.runJob(conf);
??? }
}
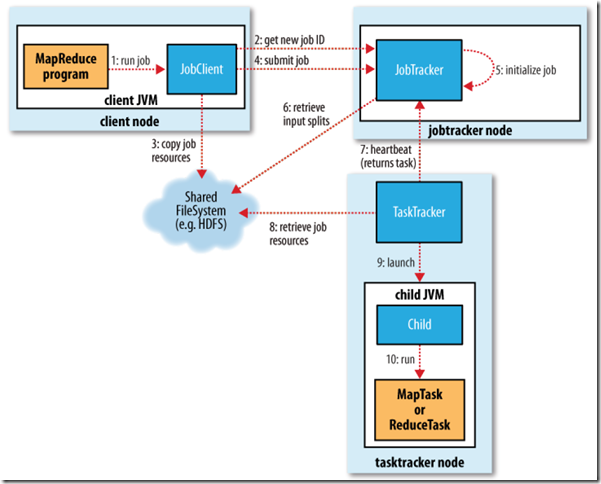
Map-Reduce�Ĵ���������Ҫ�漰�����ĸ����֣�
?
JobClient.runJob()����һ���µ�JobClientʵ����������submitJob()������
�ύ�����runJobÿ��һ������ѯһ��job�Ľ��ȣ������ȷ��ص������У�ֱ������������ϡ�
?
?
��JobTracker�յ�submitJob���õ�ʱ��������ŵ�һ�������У�job���������Ӷ����л�ȡ����ʼ������
��ʼ�����ȴ���һ����������װjob���е�tasks, status�Լ�progress��
�ڴ���task֮ǰ��job���������ȴӹ����ļ�ϵͳ�л��JobClient�������input splits��
��Ϊÿ��input split����һ��map task��
ÿ��task������һ��ID��
?
?
TaskTracker�����Ե���JobTracker����heartbeat��
��heartbeat�У�TaskTracker��֪JobTracker���Ѿ�������һ���µ�task��JobTracker���������һ��task��
��JobTrackerΪTaskTrackerѡ��һ��task֮ǰ��JobTracker�������Ȱ������ȼ�ѡ��һ��Job����������ȼ���Job��ѡ��һ��task��
TaskTracker�й̶�������λ��������map task����reduce task��
Ĭ�ϵĵ������Դ�map task������reduce task
��ѡ��reduce task��ʱ��JobTracker�����ڶ��task֮�����ѡ����ֱ��ȡ��һ������Ϊreduce taskû�����ݱ��ػ��ĸ��
?
?
TaskTracker��������һ��task�������Ҫ���д�task��
���ȣ�TaskTracker����job��jar�ӹ����ļ�ϵͳ�п�����TaskTracker���ļ�ϵͳ�С�
TaskTracker��distributed cache�н�job��������Ҫ���ļ����������ش��̡�
��Σ���Ϊÿ��task����һ�����صĹ���Ŀ¼����jar��ѹ�����ļ�Ŀ¼�С�
�������䴴��һ��TaskRunner������task��
TaskRunner����һ���µ�JVM������task��
��������child JVM��TaskTrackerͨ�����������н��ȡ�
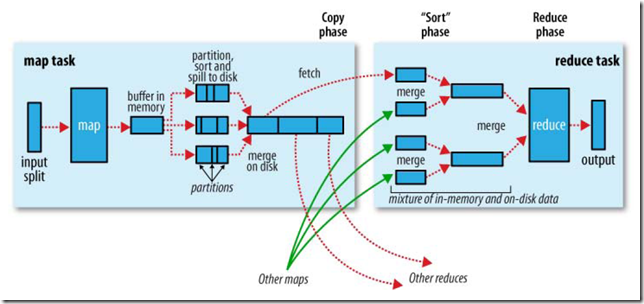
MapRunnable��input split�ж�ȡһ������record��Ȼ�����ε���Mapper��map����������������
map�����������ֱ��д��Ӳ�������ǽ���д������memory buffer��
��buffer�����ݵĵ���һ���Ĵ�С��һ�������߳������ݿ�ʼд��Ӳ�̡�
��д��Ӳ��֮ǰ���ڴ��е�����ͨ��partitioner�ֳɶ��partition��
��ͬһ��partition�У������̻߳Ὣ���ݰ���key���ڴ�������
ÿ�δ��ڴ���Ӳ��flush���ݣ�������һ���µ�spill�ļ���
����task����֮ǰ�����е�spill�ļ����ϲ�Ϊһ�����ı�partition�Ķ����ź�����ļ���
reducer����ͨ��httpЭ������map������ļ���tracker.http.threads��������http�����߳�����
��map task��������֪ͨTaskTracker��TaskTracker֪ͨJobTracker��
����һ��job��JobTracker֪��TaskTracer��map����Ķ�Ӧ��ϵ��
reducer��һ���߳������Ե���JobTracker����map�����λ�ã�ֱ����ȡ�������е�map�����
reduce task��Ҫ���Ӧ��partition�����е�map�����
reduce task�е�copy���̼���ÿ��map task������ʱ��Ϳ�ʼ�����������Ϊ��ͬ��map task���ʱ�䲻ͬ��
reduce task���ж��copy�̣߳����Բ��п���map�����
���ܶ�map���������reduce task��һ�������߳̽���ϲ�Ϊһ������ź�����ļ���
�����е�map�����������reduce task����sort���̣������е�map����ϲ�Ϊ����ź�����ļ���
������reduce���̣�����reducer��reduce�����������ź���������ÿ��key�����Ľ��д��HDFS��
?
?
?
��JobTracker������һ��task�����гɹ��ı����job��״̬��Ϊ�ɹ���
��JobClient��JobTracker��ѯ��ʱ��������job�Ѿ��ɹ������������û���ӡ��Ϣ����runJob�����з��ء�