SQL Server 2012之后对窗口函数进行了极大的加强,但对于很多开发人员来说,对窗口函数却不甚了解,导致了这样强大的功能被浪费,因此本篇文章主要谈一谈SQL Server中窗口函数的概念。
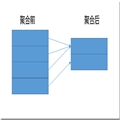
窗口函数,也可以被称为OLAP函数或分析函数。理解窗口函数可以从理解聚合函数开始,我们知道聚合函数的概念,就是将某列多行中的值按照聚合规则合并为一行,比如说Sum、AVG等等,简单的概念如图1所示。

图1.聚合函数
因此,通常来说,聚合后的行数都要小于聚合前的行数。而对于窗口函数来说,输入结果等于输出结果,举一个简单的例子,如果你计算产品类型A和产品类型B,A产品分5小类,B产品分2小类,应用了窗口函数的结果后可以还是7行,对窗口函数应用了Count后,附加在每一行上,比如说“A产品,A小类1,5“,而B小类则变为”B产品,B小类1,2”最后一列就是应用了窗口函数的结果。
现在我们对窗口函数有了初步的概览,文章后我会提供一些具体的例子来让对窗口函数的概念更加深刻,窗口函数除了上面提到的输入行等于输出行之外,还有如下特性和好处:
窗口函数是整个SQL语句最后被执行的部分,这意味着窗口函数是在SQL查询的结果集上进行的,因此不会受到Group By, Having,Where子句的影响。
窗口函数的典型范例是我们在SQL Server 2005之后用到的排序函数,比如代码清单1所示。
monospace; border-bottom-style: none; color: black; padding-bottom: 0px; direction: ltr; text-align: left; padding-top: 0px; border-right-style: none; padding-left: 0px; margin: 0em; line-height: 12pt; padding-right: 0px; width: 100%; background-color: white">Row_Number() OVER (partition by xx ORDER BY xxx desc) RowNumber
代码清单1.可用于分页的排序函数
因此,我们可以把窗口函数的语法抽象出来,如代码清单2所示。
函数() Over (PARTITION By 列1,列2,Order By 列3,窗口子句) AS 列别名代码清单2.窗口函数的语法
下面我们来看一个简单的例子,假如说我们希望将AdventureWorks示例数据库中的Employee表按照性别进行聚合,比如说我希望得到的结果是:“登录名,性别,该性别所有员工的总数”,如果我们使用传统的写法,那一定会涉及到子查询,如代码清单3所示。
SELECT [LoginID],gender,
(SELECT COUNT(*) FROM [AdventureWorks2012].[HumanResources].[Employee] a WHERE a.Gender=b.Gender) AS GenderTotal
FROM [AdventureWorks2012].[HumanResources].[Employee] b
代码清单3.传统的写法
如果我们使用了窗口函数,代码瞬间就变得简洁,不再需要子查询或Join,如图2所示。

图2.使用窗口函数
除此之外,窗口函数相比传统写法而言,还会有更好的性能,我们可以通过比较执行计划得出如图3所示。

图3.通过比较执行计划,看出窗口函数拥有更好的性能
假如我们考虑更复杂的例子,在Over子句加上了Order By,来完成一个平均数累加,如果不使用窗口函数,那一定是游标,循环等麻烦的方式,如果使用了窗口函数,则一切就变得非常轻松,如图4所示。

图4.窗口函数
代码清单2展示了窗口函数的语法,其中Over子句之后第一个提到的就是Partition By。Partition By子句也可以称为查询分区子句,非常类似于Group By,都是将数据按照边界值分组,而Over之前的函数在每一个分组之内进行,如果超出了分组,则函数会重新计算,比如图2中的例子,我们将数据分为男性和女性两部分,前面的Count()函数针对这两组分别计算值(男性206,女性84)。
针对Partition By可以应用的函数不仅仅是我们所熟知的聚合函数,以及一些其他的函数,比如说Row_Number()。
Order By子句是另一类子句,会让输入的数据强制排序(文章前面提到过,窗口函数是SQL语句最后执行的函数,因此可以把SQL结果集想象成输入数据)。Order By子句对于诸如Row_Number(),Lead(),LAG()等函数是必须的,因为如果数据无序,这些函数的结果就没有任何意义。因此如果有了Order By子句,则Count(),Min()等计算出来的结果就没有任何意义。
下面我们看一个很有代表性的ROW_NUMBER()函数,该函数通常被用于分页,该函数从1开始不断递增,可以和Partition By一起使用,当穿越分区边界时,Row_Number重置为1,一个简单的例子如图5所示,我们根据请假小时数对员工进行排序。

图5.Row_Number函数示例
另一个比较有趣的分析函数是LEAD()和LAG(),这两个分析函数经过Order By子句排序后,可以在当前行访问上N行(LAG)或下N行(LEAD)的数据,下面是一个例子,如图6所示。

图6.访问上一行的LAG函数
另一个分析函数是RANK函数,与Row_Number不同的是,Rank函数中如果出现了相同的值,不会像Row_Number那样叠加计数,而是同样的值计数一样,比如说 1 1 3 4 5 5 7,而不是Row_Number的1 2 3 4 5 6 7。这里就不细说了。另外如果希望并列排名的不影响下一个排名,则考虑使用Dense_Rank函数。有关其他的诸如First_value和Last_Value之类的函数可以参看:http://technet.microsoft.com/zh-cn/library/hh213234.aspx。
前面窗口的函数的作用范围是整个表,或是整个Partition by后面的分区。但是使用了窗口子句我们可以控制输入到窗口函数的数据集(前面说过,窗口函数是整个语句中最后执行的)的范围。下面我们从一个例子开始看,假如我希望找出公司每一个层级休病假最长的人,我们可以执行图7中的语句。

图7.找出每个层级休假最多的人
但是如果我们希望把输入数据集的粒度由Partition变为更细的话,我们可以使用窗口子句,让窗口函数仅仅根据当前行的前N行和后N行计算结果,那我们可以使用窗口子句,如图8所示,图8中,我们排序后,仅仅根据当前行的前一行和后一行以及当前行来计算这3个人当中请病假最长时间的人。

图8.在三行之内找到休假时间最长的人
我们也可以使用Range来指定Partition内的范围,比如说我们希望从当前行和之前行中找到第一行,则使用如图9所示的用法。

图9.
本文从窗口函数组成的三部分简单介绍了窗口函数的概念,并给出了一些例子。更多可以在窗口上使用的函数,可以参照MSDN(http://technet.microsoft.com/zh-cn/library/ms189461.aspx)。在使用这些函数的时候,还要注意版本要求,很多函数是只有在SQL Server 2012中才被支持的。