看到一篇讲堆和栈的文章,是我目前为止见到讲的最易懂,详细和深入的。我翻译成中文。以此总结。
原文=》C#Heap(ing) Vs Stack(ing) in .NET
在net framework框架下。即使我们并不需要关心内存管理和垃圾回收,但是为了提高我们的应用程序性能,我们仍然需要这么去做,仍然需要对gc和内存管理保持关注。所以,理解内存管理是如何工作的,可以帮助我们解释我们程序代码中变量的行为。在本文中,将讨论堆和栈,变量类型,和变量的工作行为。
当代码执行的时候,net framework在内存中有两个地方存储元素项。如果你从来没有关注过,那么,让我来介绍下堆和栈。当我们的代码运行的时候,堆和栈往往相伴左右。他们寄宿在机器的内存中。并且当我们需要运行程序获取某个结果的时候,他们能提供一个“现场”能提供产生这个结果所需要的所有信息。
堆和栈有何区别呢?
栈,他负责跟踪我们的代码的是如何执行(或者说是怎么样被一步步函数调用的),而堆,则负责跟踪我们所有的对象(我们的数据,基本上是大部分数据,后面再讲)
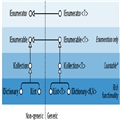
想 想一下,假想,栈就是一个个叠起来的盒子一样。每一次当我们进行一次函数调用的时候,就像在最顶端再叠放一个盒子,这样来跟踪我们的程序的走向。在栈上, 我们只能用最顶上的那个盒子,当我们用完最顶上的那个盒子以后,就像一个函数执行完毕。然后我们扔掉它。这个时候,我们就要使用前一个被扔掉的盒子下面的 那个盒子。而堆也是相似的,只不过他的目的仅仅是存放信息,而并没有跟踪这些信息执行,没有保持对信息状态的跟踪。在堆里面,什么东西可以访问,什么东西 不能访问,这是没有限制的。堆,就像我们洗干净扔床上的衣服一样。我们根本不需要及时的来花时间把他们收拾好。如果我们确实需要收拾,我们也可以迅速的来 吧他们收拾好。而栈呢,更像鞋柜里叠起来的一个个盒子。如果我们想要拿某个盒子,那么必须先拿掉它上面的那个,看下图,很好懂。
canyouwiki/uploads/20131104/13835770039513.png" alt="" border="0" />
上面这个图,很好的呈现了我们的内存中发生着什么,或者我们内存中数据呈现的一种状态,这可以更好的帮我们理解堆和栈(Stack and heap)
栈是自我管理的,什么意思呢,栈只需要关注自己的内存管理,当最顶上的盒子不用了,ok,扔掉它、而堆,另一方面,需要来关注垃圾回收(GC).说白了就是如何来保持堆的干净。没有人愿意东西乱扔,那是会让人恶心的。
堆和栈中有什么?
当我们的代码在执行的时候,我们有四种类型可以往堆和栈中放。值类型,引用类型,指针类型,代码指令
值类型
在C#语言中,所有以以下类型声明的东西均是值类型。因为他们继承自System.ValueType
bool
byte
char
decimal
double
enum
float
int
long
sbyte
short
struct
uint
ulong
ushort
引用类型
所有以以下类型声明的东西都是引用类型,因为他们继承自System.Object.(当然只针对于是System.Object类型的对象)
interface
delegate
object
string
指针类型
第三种纳入内存管理的类型是引用。通常情况下,一个引用被视为一个指针。我们并没有显示明确的去使用指针,指针是由CLR使用管理的。引用(指针)跟 引用类型是有区别的。通常情况下,我们说一个东西是引用类型,那么意味着什么,意味着我们可以通过指针去访问他。指针是什么呢?指针说白了,就是内存中的 一块区域,他指向内存中的另一块内存空间(这种指向存放的是地址)。指针,就像我们向堆和栈放的东西占要占据空间一样,通常里面存放的值是内存地址或者null

指令
后文再做介绍。
如何决定分配那种内存?
两条黄金法则
引用类型始终分配在堆上。
值类型和指针类型始终跟踪声明他们的类型,这有点难以理解。需要对栈的工作原理有一些深入的理解
栈,正如之前提到的一样,负责跟踪每个线程的代码执行走向(函数的调用)。你可以想象成一个线程状态。每个线程都是都一个线程栈的。当我们的代码发生了一次方法调用。那么线程将开始执行JIT编译的代码。并且该方法会在方法表上登记,方法参数也会被压入线程栈。然后当我们进入方法,初始化变量后,他们已经被放置在栈顶了。下面这个例子可能更好理解。
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
下面描述下栈顶发生了什么。
记好,我们要寻找的东西,永远始终是在栈顶。(即使栈里有其他东西,我们需要的东西应该始终在栈顶。)
当我们开始执行方法的时候。方法的参数会被放入堆栈。后期会来介绍参数传递。
注意,方法是不会存活在堆栈上的。恩,如图说明

接下来。控制(线程执行)会转移到方法表中登记的AddFive()方法上,如果方法是第一次调用。即时编译器会被调用,执行IL代码的编译工作

当方法执行的时候,我们需要一些内存空间来存放方法执行的结果。存放结果的内存空间是会分配在栈上。

当方法执行完毕,我们的结果返回

当指针从新指向addFile的调用处时候(地址必须可访问)。这个时候,所有在栈上分配的内存空间都会被回收,我们将回到栈中的前一个方法。方法调用返回。

在这个例子中,我们的结果变量是分配在栈中的。而实际上,在方法体内声明的所有值类型,他们的内存空间分配均是分配在栈上。
现在,值类型有时候也是可以分配在堆中的,记住,值类型的具体分配,总是取决于声明它的类型。
如果一个值类型,他在方法体外声明,但是在一个引用类型内部声明。它会跟随声明它的引用类型一样,分配在堆上,跟寄生一样。
看另外一个例子
有一个引用类型
public class MyInt
{
public int MyValue;
}
执行以下方法
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}
跟之前说的一样。线程开始执行方法,参数都会分配在线程栈上。

现在问题是,方法执行过程中,什么时候需要特别注意??
因为MyInt是一个引用类型。他会被分配在堆上。并且会被栈上的一个指针引用(栈上的指针指向堆中的这个对象)

AddFive()方法结束以后,我们要开始进行垃圾回收了。

这个时候MyInt对象在堆会成为一个孤儿对象。什么意思。栈中没有任何指针指向MyInt对象。无任何引用、

接下来,GC(垃圾回收器)要开始派上用场了
是这样的。一旦内存达到一个极限,这个时候我们需要更多的堆空间。那么GC就启动了。GC会强制停掉所有正在运行的线程。从堆中找出所有不再被程序访问对象。然后,删除他们。这个时候,GC会识别堆中所有对象。并且调整栈和堆中指向他们的指针。跟你想象的一样。这种工作是非常消耗性能的。所以当我们尝试写一些高性能的代码的时候,我们迫切的需要知道堆和栈中有那些东西。
好了,非常好,但是它对我有何影响呢?
好问题
当我们使用引用类型的时候,我们实际上是在使用指针处理该类型。处理的不是类型本身。而是指针所指的(对象)。这很好理解
也用一个例子来说明
我们执行以下代码
public int ReturnValue()
{
int x = new int();
x = 3;
int y = new int();
y = x;
y = 4;
return x;
}
我们得到的结果是3,是不是很简单。
如果我们用我们之前定义的MyInt
public class MyInt
{
public int MyValue;
}
执行以下方法
public int ReturnValue2()
{
MyInt x = new MyInt();
x.MyValue = 3;
MyInt y = new MyInt();
y =x;
y.MyValue =4;
returnx.MyValue;
}
得到的结果是4
为毛? x.MyValue 为什么会是4... 来看下我们坐了什么,看是否讲得通。
在第一个例子中,代码如预期般的执行
public int ReturnValue()
{
int x = 3;
int y = x;
y = 4;
return x;
}

在下一个例子中我们得到的结果是4,因为变量x和y都指向相同的对象。
public int ReturnValue2()
{
MyInt x;
x.MyValue = 3;
MyInt y;
y = x;
y.MyValue = 4;
return x.MyValue;
}

希望这能让你更好的理解C#中的值类型和引用类型。并且对指针和什么时候用指针有一个基本的了解。
在下一节我将更加深入的讲解内存管理,并且将会着重讲解方法参数传递、