曾经见过一句话,不记得具体了,但是大意就是:一个好的数据结构和一个差的程序代码远远比一个好的程序代码和一个差的数据结构要好。
慢慢的开始同意说这句话的人了。
数组和链表是数据结构中最基础的两个结构,其他几乎许多结构如
队列、树、表都可以利用其实现。以前曾经实现过用数组和链表实现的队列,两者的差别很明显:
1.数组由于要先开辟
内存空间,所以所需要的空间比较大,并且一般都会有浪费;队列采用离散存储方式,需要的空间比较小;
2.数组存在唯一序列号,查询、修改数据比较方便;队列在以上方面浪费时间比较多,但是添加数据不限空间,删除数据也不会有闲置空间;
总值,两者的取舍就得看实际情况中对时间和空间的要求了。
但是,想想:如果把两者
结合一起又会如何呢?能实现两者的均衡利用吗?
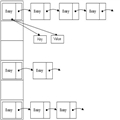
于是又一种新的数据结构得到了使用,哈希表便是把这两者结合的一种运用方式:定义一个固定长度的数组,数组中存放链表实现数据的存储。
基础步骤是:
1.设定数组长度;
2.对所要存储的对象以一个特定int值对长度取余;
3.将余数相同的对象以链表方式存入同一个数组元素中。
所需要考虑的问题最基本的有:
1.数组长度是否
合理;
2.链表长度是否合理。
代码的基本思路是:
1.创建一个节点类。
属性:节点数据(E data)、节点指向的下一个节点(HashLinkNode next)、用来确定余数的特殊值(int value);
方法:构造方法,获得特殊值的方法;
2.创建哈希表类
属性:表长(int length)、表数组(Mylink con[])、表冲突数(int strif)、表中数据总量(int count);
方法:构造方法,获得表数据总量的方法,向表中添加数据的方法,获得所有数据的方法,显示哈希表结构的方法,(根据指定长度)重新构造哈希表的方法。
3.学生类和测试类。
遇到的问题:
1.向哈希表数组元素,即链表中用add()添加数据时,如果该链表本来为空,出现空指针。
这是自己创建链表时一直没有解决的问题,今天想到可以用链表的构造方法先创建节链表,然后将该临时链表赋给数组元素。
if(con[i]==null){
MyLink<E> tempLink=new MyLink<E>(e);
con[i]=tempLink;
}
2.写获取所有哈希表数据时,返回数据类型的确定。
首先想到的是创建
泛型的数组:E es=new E[count];但是,java本身好像还没有办法实现这样数组的创建;
然后,想到的是返回E[]类型的数据,创建数组时先用Object os=new Object[count];然后返回时再转型,但是,始终出现
错误。泛型使用时要注意的东西很多,一次性避免对于现在的我来说还是比较困难的,只能一次一次的猜测和尝试,不怕麻烦大概就是
程序员必备的素质。不怕。
当然,后来想着别返回泛型数组了,可以用Queue啊。但是,Queue太容易出现空指针了,用add()时要注意,当然还是没有找到好的
解决方法。
所以最后还是找到LinkedList,试了一下add(),很好。
3.打印哈希表结构时,总是重复显示多次内容。
for
循环是问题所在,当然也是通过多次测试性的System.out.print()找到问题并解决的额。
4.re
hash时也出现了很纠结但是又很低级的问题,具体就不说了
结论就是,在避免麻烦复制粘贴已有代码时,也要再回过头来看一下每行代码的必要性,
他们不仅仅可能是多余的,更有可能会成为错误所在。而这时发生错误时要发掘是很困难的,因为错误并不是在这一行,所以先检查一遍,磨刀不误砍柴工。
经历过才懂得就是这个道理吧。自己写过和看过是完全不同的感受。就算没有时间把要写的和想写的写完,但是写好自己喜欢的。
还需要想的问题:
1.这种结合数组和链表的方式是不是已经是最好了,还有其他解决方式吗?
2.有可能把数组和树结合起来吗?
3.rehash的
算法是否能更简单,能不用把所有数据取出来再添加吗?或许能够利用他们在hash表中的结构再简单重新排序一下就行了,比如length再加长1个单位时,所有链表的root节点是不用变的,以后的再看各自原排在链表的第几位再按规律添加至下几个数组元素中。
4.hash表的length合适与否,究竟怎样安排,靠冲突指数?那冲突指数的设定呢?还是怎样都是“视情况而定”?
。。。。。。
多提问题,哪怕很简单很白痴,也似乎没有
意义。

![[转]Socket实现C++与Flex通信](/Upload/SmallIMG/2013110121/246EEB7215F4E827.gif)