排序是各门语言中的核心,也是计算机数据处理中的核心运算,是我们学过的“数据结构与算法”课程的重点。排序算法能够体现算法设计和算法分析的精神。有效的排序算法在一些算法(例如搜索算法与合并算法)中是重要的,如此这些算法才能得到正确解答。 这篇博文主要包含了8大内部排序的算法复杂度,稳定性以及c语言描述算法和可视化过程,花时间总结了很久,但是肯定仍有不足,希望各位大神能指点迷津。
小注:刚发现,可视化过程的图片是gif格式,但是传上去之后好像不动,不好意思。请在点连接:http://blog.jobbole.com/11745/视觉直观感受 7 种常用的排序算法(在最后的参考资料中也有)
a)输出结果为递增串行(递增是针对所需的排序顺序而言);
b)输出结果是原输入的一种排列、或是重组。
被排序的对象--文件由一组记录组成。记录则由若干个数据项(或域)组成。其中有一项可用来标识一个记录,称为关键字项。该数据项的值称为关键字(Key)。
关键字,可以是数字类型,也可以是字符类型。 关键字的选取应根据问题的要求而定。
(1) 内部排序:
待排序的记录全部存放在内存中进行排序的过程。
(2) 外部排序:
待排序的记录的数量很大,以至于内存不能容纳全部记录,在排序过程中需要对外存进行访问的排序过程。
(1) 插入排序:
直接插入排序,折半插入排序;
(2) 选择排序:
(3) 交换排序:
简单选择排序,堆排序;
(4) 归并排序:
归并排序;
(5) 分配排序:
基数排序;
(1)稳定排序:
直接插入排序,冒泡排序,归并排序,基数排序
(2)不稳定排序:
简单选择排序,希尔排序,快速排序,堆排序
大多数排序算法都有两个基本的操作:比较和移动;
(1) 比较两个关键字的大小;
(2) 改变指向记录的指针或移动记录本身。
操作的实现依赖于待排序记录的存储方式(①待排序的记录存放在连续的一组存储单元上,类似于线性表的顺序存储;②待排序的记录存放在静态链表中;③待排序的记录本身存储在一组地址连续的存储单元内,同时另设一个指示各个记录存储位置的地址向量,排序时不移动记录本身,而是移动地址向量中这些记录的地址)。
a)冒泡排序代码:
<span style=class="string">"font-size:14px">void bubbleSort(){
- for(i=0;i<n-1;i++){
- change=false;
- for(){
- if(a[j]>a[j+1]){
- a[j]←→a[j+1];
- change=true;
- }
- if(!change){
- break;
- }
- }
- }
- }</span>
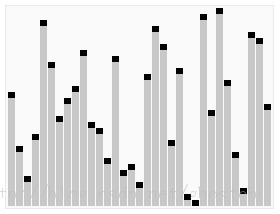
b)冒泡排序的可视化试图:
a)选择排序代码:
<span style="font-size:14px">void selectionSort(){
- for(i=0;i<n-1;i++){
- k=i;
- for(j=i+1;j<n;j++){
- if(a[j]<a[k]){
- k=j;
- }
- if(k!=i){
- a[i]←→a[k];
- }
- }
- }
- }</span>
b)选择排序的可视化试图:
a)插入排序代码:
<span style="font-size:14px">//直接插入排序
- void InsertSort(int array[], int size)
- {
- for(int i = 2; i < size; i++ )
- {
- if(array[i] < array[i-1])
- {
- array[0] = array[i];
- int j;
- for(j = i - 1; array[0] < array[j]; j--)
- {
- array[j+1] =array[j];
- }
- array[j+1] = array[0];
- }
- }
- for(int i = 1; i < size; i++)
- {
- cout << array[i] << endl;
- }
- }
- </span>
a)快速排序代码:
<span style="font-size:14px">void QiuckSort(){
- If(low<high){
- Pivot=a[low];
- i=low;
- <span style="white-space:pre"> </span>j=high;
- <span style="white-space:pre"> </span>while(i<j){
- <span style="white-space:pre"> </span>while(i<j&&a[j]>=pivot){
- <span style="white-space:pre"> </span><span style="white-space:pre"> </span>j--;
- <span style="white-space:pre"> </span>a[i] ←→a[j];
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>while(i<j&&a[j]<=pivot){
- <span style="white-space:pre"> </span>i++;
- <span style="white-space:pre"> </span><span style="white-space:pre"> </span>a[i] ←→a[j];
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>a[i]=pivot;
- <span style="white-space:pre"> </span>QiuckSort(a,low,i-1);
- <span style="white-space:pre"> </span>QiuckSort(a,i-1,high);
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>}
- }
- </span>
b)快速排序的可视化试图:
a)归并排序代码:
<span style="font-size:14px">//归并操作
- void Merge(int sourceArr[], int targetArr[], int startIndex, int midIndex, int endIndex)
- {
- int i, j, k;
- for(i = midIndex+1, j = startIndex; startIndex <= midIndex && i <= endIndex; j++)
- {
- if(sourceArr[startIndex] < sourceArr[i])
- {
- targetArr[j] = sourceArr[startIndex++];
- }
- else
- {
- targetArr[j] = sourceArr[i++];
- }
- }
- if(startIndex <= midIndex)
- {
- for(k = 0; k <= midIndex-startIndex; k++)
- {
- targetArr[j+k] = sourceArr[startIndex+k];
- }
- }
- if(i <= endIndex)
- {
- for(k = 0; k <= endIndex- i; k++)
- {
- targetArr[j+k] = sourceArr[i+k];
- }
- }
- }
- //内部使用递归,空间复杂度为n+logn
- void MergeSort(int sourceArr[], int targetArr[], int startIndex, int endIndex)
- {
- int midIndex;
- int tempArr[100]; //此处大小依需求更改
- if(startIndex == endIndex)
- {
- targetArr[startIndex] = sourceArr[startIndex];
- }
- else
- {
- midIndex = (startIndex + endIndex)/2;
- MergeSort(sourceArr, tempArr, startIndex, midIndex);
- MergeSort(sourceArr, tempArr, midIndex+1, endIndex);
- Merge(tempArr, targetArr,startIndex, midIndex, endIndex);
- }
- }
- //调用
- int _tmain(int argc, _TCHAR* argv[])
- {
- int a[8]={50,10,20,30,70,40,80,60};
- int b[8];
- MergeSort(a, b, 0, 7);
- for(int i = 0; i < sizeof(a) / sizeof(*a); i++)
- cout << b[i] << ' ';
- cout << endl;
- system("pause");
- return 0;
- }</span>
b)归并排序的可视化试图:
a)基数排序的代码:
<span style="font-size:14px">#include <stdlib.h>
- #include <math.h>
- testBS()
- {
- int a[] = {2,343,342,1,123,43,4343,433,687,654,3};
- intint *a_p = a;
- //计算数组长度
- int size = sizeof(a)/sizeof(int);
- //基数排序
- bucketSort3( a_p , size );
- //打印排序后结果
- int i ;
- for(i = 0 ; i < size ; i++ ) {
- printf("%d\n ",a[i]);
- }
- int t;
- scanf("%d",t);
- }
- //基数排序
- void bucketSort3(intint *p , int n)
- {
- //获取数组中的最大数
- int maxNum = findMaxNum( p , n );
- //获取最大数的位数,次数也是再分配的次数。
- int loopTimes = getLoopTimes(maxNum);
- int i ;
- //对每一位进行桶分配
- for( i = 1 ; i <= loopTimes ; i++) {
- sort2(p , n , i );
- }
- }
- //获取数字的位数
- int getLoopTimes(int num)
- {
- int count = 1 ;
- int temp = num/10;
- while( temp != 0 ) {
- count++;
- temp = temp / 10;
- }
- return count;
- }
- //查询数组中的最大数
- int findMaxNum( intint *p , int n)
- {
- int i ;
- int max = 0;
- for( i = 0 ; i < n ; i++) {
- if(*(p+i) > max) {
- max = *(p+i);
- }
- }
- return max;
- }
- //将数字分配到各自的桶中,然后按照桶的顺序输出排序结果
- void sort2(intint *p , int n , int loop)
- {
- //建立一组桶 此处的20是预设的 根据实际数情况修改
- int buckets[10][20] = {} ;
- //求桶的index的除数
- //如798 个位桶index = ( 798 / 1 ) % 10 = 8
- // 十位桶index = ( 798 / 10 ) % 10 = 9
- // 百位桶index = ( 798 / 100 ) % 10 = 7
- // tempNum 为上式中的1、10、100
- int tempNum = (int) pow(10 , loop-1);
- int i , j ;
- for( i = 0 ; i < n ; i++ ) {
- int row_index = (*(p+i) / tempNum) % 10;
- for(j = 0 ; j < 20 ; j++) {
- if(buckets[row_index][j] ==NULL) {
- buckets[row_index ][j] = *(p+i) ;
- break;
- }
- }
- }
- //将桶中的数,倒回到原有数组中
- int k = 0 ;
- for(i = 0 ; i < 10 ; i++) {
- for(j = 0 ; j < 20 ; j++) {
- if(buckets[i][j] != NULL) {
- *(p + k ) = buckets[i][j] ;
- buckets[i][j]=NULL;
- k++;
- }
- }
- }
- }</span>
a)希尔排序代码:
<span style="font-size:14px">void ShallSort(T a[] ,int n){
- d=n/2;
- while(d=){//一趟希尔排序,对d个序列分别进行插入排序
- for(i=d;i<n;i++){
- x=a[i];
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>for(j=i-d;j>=0&&x<a[j];j-=d){
- a[j+d]=a[j];
- a[j+d]=x;
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>d=d/2;
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>}
- </span>
b)希尔排序的可视化试图:
a)堆排序的可视化试图:
<span style="font-size:14px">// array是待调整的堆数组,i是待调整的数组元素的位置,nlength是数组的长度
- //本函数功能是:根据数组array构建大根堆
- void HeapAdjust(int array[], int i, int nLength)
- {
- int nChild;
- int nTemp;
- for (nTemp = array[i]; 22 * i + 1 < nLength; i = nChild)
- {
- // 子结点的位置=2*(父结点位置)+ 1
- nChild = 22 * i + 1;
- // 得到子结点中较大的结点
- if ( nChild < nLength-1 && array[nChild + 1] > array[nChild])
- ++nChild;
- // 如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点
- if (nTemp < array[nChild])
- {
- array[i] = array[nChild];
- array[nChild]= nTemp;
- }
- else
- // 否则退出循环
- break;
- }
- }
- // 堆排序算法
- void HeapSort(int array[],int length)
- {
- int tmp;
- // 调整序列的前半部分元素,调整完之后第一个元素是序列的最大的元素
- //length/2-1是第一个非叶节点,此处"/"为整除
- for (int i = length / 2 - 1; i >= 0; --i)
- HeapAdjust(array, i, length);
- // 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
- for (int i = length - 1; i > 0; --i)
- {
- // 把第一个元素和当前的最后一个元素交换,
- // 保证当前的最后一个位置的元素都是在现在的这个序列之中最大的
- /// Swap(&array[0], &array[i]);
- tmp = array[i];
- array[i] = array[0];
- array[0] = tmp;
- // 不断缩小调整heap的范围,每一次调整完毕保证第一个元素是当前序列的最大值
- HeapAdjust(array, 0, i);
- }
- }</span>
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)空间复杂度:
一个程序的空间复杂度是指运行完一个程序所需内存的大小。利用程序的空间复杂度,可以对程序的运行所需要的内存多少有个预先估计。一个程序执行时除了需要存储空间和存储本身所使用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为现实计算所需信息的辅助空间。

假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的。
(1)冒泡排序
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。我们知道,冒泡排序的交换条件是:a[j]>a[j+1]或者a[j]<a[j+1]很明显不包括相等的情况,所以如果两个元素相等,他们不会交换;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序不会改变,所以冒泡排序是一种稳定排序算法。
(2)选择排序
选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n-1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。那么,在一趟选择,如果当前元素比一个元素小,而该小的元素又出现在一个和当前元素相等的元素后面,那么交换后稳定性就被破坏了。比较拗口,举个例子,序列5 8 5 2 9, 我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
(3)插入排序
插入排序是在一个已经有序的小序列的基础上,一次插入一个元素。当然,刚开始这个有序的小序列只有1个元素,就是第一个元素。比较是从有序序列的末尾开始,也就是想要插入的元素和已经有序的最大者开始比起,如果比它大则直接插入在其后面,否则一直往前找直到找到它该插入的位置。如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面。即和冒泡排序一样:a[j]>a[j+1]或者a[j]<a[j+1]很明显不包括相等的情况,所以如果两个元素相等,他们不会交换;所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以插入排序是稳定的。
(4)快速排序
快速排序有两个方向,左边的i下标一直往右走,当a[i] <= [center_index](center_index中枢元素的数组下标),一般取为数组第0个元素。而右边的j下标一直往左走,当a[j] > a[center_index]。如果i和j都走不动了,i <= j, 交换a[i]和a[j],重复上面的过程,直到i>j。 交换a[j]和a[center_index],完成一趟快速排序。在中枢元素和a[j]交换的时候,很有可能把前面的元素的稳定性打乱,比如序列为 5,3,3,4,3,8,9,10,11, 现在中枢元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱,所以快速排序是一个不稳定的排序算法,不稳定发生在中枢元素和a[j]交换的时刻。
快速排序是高效排序算法了。实践证明,快速排序是所有排序算法中最高效的一种。它采用了分治的思想:先保证列表的前半部分都小于后半部分,然后分别对前半部分和后半部分排序,这样整个列表就有序了。这是一种先进的思想,也是它高效的原因。因为在排序算法中,算法的高效与否与列表中数字间的比较次数有直接的关系,而"保证列表的前半部分都小于后半部分"就使得前半部分的任何一个数从此以后都不再跟后半部分的数进行比较了,大大减少了数字间不必要的比较。但查找数据得另当别论了。
(5)归并排序
所谓“归并”,试讲两个或两个以上的有序文件合并成一个新的有序文件。归并排序是把一个有n个记录的无序文件看成是由n个长度为1的有序子文件组成的文件,然后进行两两归并,得到[n/2]个长度为2或1的有序文件,再两两归并,如此重复,直至最后形成包含n个记录的有序文件为止。所以,归并排序也是稳定的排序算法。
(6)基数排序
基数排序的思想是按组成关键字的各个数位的值进行排序,他是分配排序的一种。基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序,最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。为了减少记录的移动次数,队列可以采用链式存储分配,称为链队列。基数排序基于分别排序,分别收集,所以其是稳定的排序算法。
(7)希尔排序(shell)
希尔排序又称为“缩小增量排序”是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小,插入排序对于有序的序列效率很高。关键步骤是取增量d,那全体记录分成d组,进行直接插入排序,直到d=1.所以,希尔排序的时间复杂度会比o(n^2)好一些。由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
(8)堆排序
我们知道堆的结构是节点i的孩子为2*i和2*i+1节点,大顶堆要求父节点大于等于其2个子节点,小顶堆要求父节点小于等于其2个子节点。在一个长为n的序列,堆排序的过程是从第n/2开始和其子节点共3个值选择最大(大顶堆)或者最小(小顶堆),这3个元素之间的选择当然不会破坏稳定性。但当为n /2-1, n/2-2, ...1这些个父节点选择元素时,就会破坏稳定性。有可能第n/2个父节点交换把后面一个元素交换过去了,而第n/2-1个父节点把后面一个相同的元素没有交换,那么这2个相同的元素之间的稳定性就被破坏了。所以,堆排序不是稳定的排序算法。
1.http://v.youku.com/v_show/id_XNjIwNTEzMTA0.html15种排序算法可视化展示(神作!)
2.http://blog.jobbole.com/11745/视觉直观感受 7种常用的排序算法
3.数据结构(C语言版) 清华大学出版社 严蔚敏
4.软件设计师教程 清华大学出版社 胡圣明