前几天看了这篇文章:谈sqlserver对like '%关键词%' 处理时的索引利用问题
看完了之后,我很想知道这篇文章是不是临时工写的?还是网站的主人写的,网站的主人的微博我都有关注(在微博里私信过)
是某个公司的DBA,这里先不管他是不是临时工写的,今天我也研究一下这个问题o(∩_∩)o
说明:我们说的走索引指的是:聚集索引查找、非聚集索引查找
而全表扫描、聚集索引扫描、非聚集索引扫描都不是走索引
而这里说的走索引跟全文搜索/全文索引没有关系 SQLSERVER全文搜索
全文搜索/全文索引已经是另外一种技术了
聚集索引表
SQL脚本如下:
1 --聚集索引表 2 USE [pratice] 3 GO 4 CREATE TABLE Department( 5 DepartmentID int IDENTITY(1,1) NOT NULL , 6 GroupName NVARCHAR(20) NOT NULL, 7 Company NVARCHAR(20), 8 ) 9 10 CREATE CLUSTERED INDEX CL_GroupName ON [dbo].[Department](GroupName ASC) 11 12 DECLARE @i INT 13 SET @i=1 14 WHILE @i < 100000 15 BEGIN 16 INSERT INTO Department ( [Company], groupname ) 17 VALUES ( '中国你好有限公司XX分公司'+CAST(@i AS VARCHAR(20)), '销售组'+CAST(@i AS VARCHAR(20)) ) 18 SET @i = @i + 1 19 END 20 21 22 SELECT * FROM DepartmentView Code
表数据
聚集索引创建在GROUPNAME这个字段上,我们就查找GROUPNAME这个字段
如果看过我以前写的文章的人肯定知道:查找只会出现在建立索引的时候的第一个字段(这里我就不再详细叙述了)
1 --聚集索引查找 2 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000' 3 --聚集索引扫描 4 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000%' 5 --聚集索引扫描 6 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000' 7 --聚集索引查找 8 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000%'


--------------------------------------------------------------------------
IO和时间统计

1 SET STATISTICS IO ON 2 SET STATISTICS TIME ON 3 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000' 4 SET STATISTICS IO OFF 5 SET STATISTICS TIME OFF 6 7 SET STATISTICS IO ON 8 SET STATISTICS TIME ON 9 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000%' 10 SET STATISTICS IO OFF 11 SET STATISTICS TIME OFF 12 13 SET STATISTICS IO ON 14 SET STATISTICS TIME ON 15 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000' 16 SET STATISTICS IO OFF 17 SET STATISTICS TIME OFF 18 19 SET STATISTICS IO ON 20 SET STATISTICS TIME ON 21 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000%' 22 SET STATISTICS IO OFF 23 SET STATISTICS TIME OFFView Code
1 (1 行受影响)LIKE '销售组1000' 2 表 'Department'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 3 4 SQL Server 执行时间: 5 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 6 7 SQL Server 执行时间: 8 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 9 10 (11 行受影响)LIKE '%销售组1000%' 11 表 'Department'。扫描计数 1,逻辑读取 448 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 12 13 SQL Server 执行时间: 14 CPU 时间 = 47 毫秒,占用时间 = 47 毫秒。 15 16 SQL Server 执行时间: 17 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 18 19 (1 行受影响)LIKE '%销售组1000' 20 表 'Department'。扫描计数 1,逻辑读取 448 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 21 22 SQL Server 执行时间: 23 CPU 时间 = 47 毫秒,占用时间 = 40 毫秒。 24 25 SQL Server 执行时间: 26 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 27 28 (11 行受影响)LIKE '销售组1000%' 29 表 'Department'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 30 31 SQL Server 执行时间: 32 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 33 34 SQL Server 执行时间: 35 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
只有LIKE '销售组1000'和LIKE '销售组1000%'用到了查找
为什麽?我会在文中最后说明
非聚集索引表
SQL脚本如下:
我们drop掉刚才的department表
1 DROP TABLE [dbo].[Department]
重新建立department表
1 --非聚集索引表 2 USE [pratice] 3 GO 4 CREATE TABLE Department( 5 DepartmentID int IDENTITY(1,1) NOT NULL , 6 GroupName NVARCHAR(20) NOT NULL, 7 Company NVARCHAR(20), 8 ) 9 10 CREATE INDEX CL_GroupName ON [dbo].[Department](GroupName ASC) 11 12 DECLARE @i INT 13 SET @i=1 14 WHILE @i < 100000 15 BEGIN 16 INSERT INTO Department ( [Company], groupname ) 17 VALUES ( '中国你好有限公司XX分公司'+CAST(@i AS VARCHAR(20)), '销售组'+CAST(@i AS VARCHAR(20)) ) 18 SET @i = @i + 1 19 END 20 21 22 SELECT * FROM DepartmentView Code
非聚集索引依然建立在GROUPNAME这个字段上
表数据

同样,我们使用上面讲解聚集索引表时候的查询语句
1 --非聚集索引查找 RID查找 2 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000' 3 --非聚集索引扫描 RID查找 4 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000%' 5 --非聚集索引扫描 RID查找 6 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000' 7 --非聚集索引查找 RID查找 8 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000%'


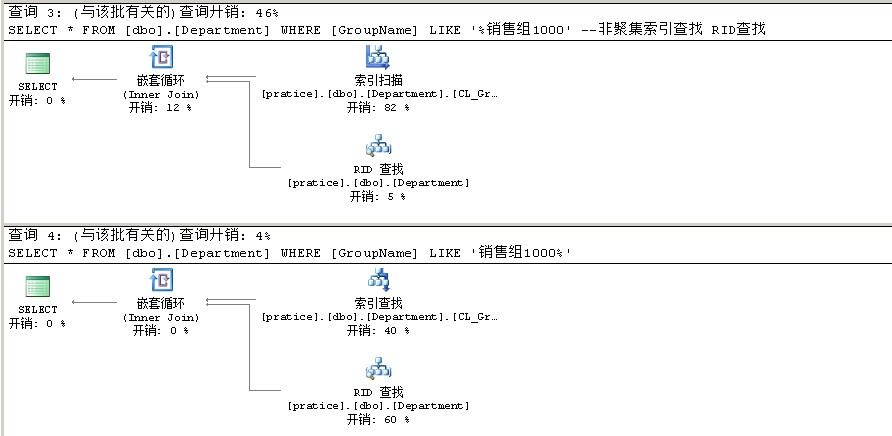
因为是select * 所以SQLSERVER需要到数据页面去找其他的字段数据,使用到RID查找
这里的结果跟聚集索引是一样的
-------------------------------------------------------------------------------------------
IO和时间统计
1 SET STATISTICS IO ON 2 SET STATISTICS TIME ON 3 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000' 4 SET STATISTICS IO OFF 5 SET STATISTICS TIME OFF 6 7 SET STATISTICS IO ON 8 SET STATISTICS TIME ON 9 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000%' 10 SET STATISTICS IO OFF 11 SET STATISTICS TIME OFF 12 13 SET STATISTICS IO ON 14 SET STATISTICS TIME ON 15 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000' 16 SET STATISTICS IO OFF 17 SET STATISTICS TIME OFF 18 19 SET STATISTICS IO ON 20 SET STATISTICS TIME ON 21 SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000%' 22 SET STATISTICS IO OFF 23 SET STATISTICS TIME OFFView Code
1 (1 行受影响) LIKE '销售组1000' 2 表 'Department'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 3 4 SQL Server 执行时间: 5 CPU 时间 = 0 毫秒,占用时间 = 62 毫秒。 6 7 SQL Server 执行时间: 8 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 9 10 (11 行受影响)LIKE '%销售组1000%' 11 表 'Department'。扫描计数 1,逻辑读取 92 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 12 13 SQL Server 执行时间: 14 CPU 时间 = 16 毫秒,占用时间 = 17 毫秒。 15 16 SQL Server 执行时间: 17 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 18 19 (1 行受影响)LIKE '%销售组1000' 20 表 'Department'。扫描计数 1,逻辑读取 82 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 21 22 SQL Server 执行时间: 23 CPU 时间 = 15 毫秒,占用时间 = 17 毫秒。 24 25 SQL Server 执行时间: 26 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 27 28 (11 行受影响)LIKE '销售组1000%' 29 表 'Department'。扫描计数 1,逻辑读取 13 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 30 31 SQL Server 执行时间: 32 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 33 34 SQL Server 执行时间: 35 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
为什麽只有LIKE '销售组1000'和LIKE '销售组1000%'用到了查找???
如果阁下曾经有看过我写的
SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(下)
您就会知道在聚集索引页面和非聚集索引页面里都有一个KeyHashValue的字段
聚集索引页面

非聚集索引页面

当使用 '%销售组1000%'和'%销售组1000'的时候,因为是模糊匹配(百分号前置)
SQLSERVER不会去匹配hash值(KeyHashValue),直接扫描(SCAN)算了
但是使用'销售组1000'和'销售组1000%'的时候
'销售组1000' :SQLSERVER能够准确匹配到唯一的一个hash值
'销售组1000%':SQLSERVER会匹配与销售组1000相同的hash值
与销售组1000%匹配的记录会有多个,所以逻辑读取次数也会有多次

所以,'销售组1000'和'销售组1000%'能够使用查找(SEEK)
总结
只有了解了SQLSERVER的内部原理,才能够明白更多
注意:我这里并没有将非聚集索引扫描纳入到“走索引”这个分类,如果将非聚集索引扫描纳入到“走索引”这个分类里
那么我的朋友的文章就是对的,随便加个非聚集索引,让表扫描/聚集索引扫描变成非聚集索引扫描,就认为是走索引
(虽然非聚集索引扫描比聚集索引扫描/表扫描快,IO少)
那么下面四个语句都是属于走索引,没有什么好讨论的,我们讨论的前提是在基础表上不加任何东西,如果在做实验的过程中
随便加个非聚集索引,然后走非聚集索引扫描就说走索引,那么这篇文章就没有意义了,经过再三斟酌,
我决定将“非聚集索引扫描”移出“走索引”这个分类,毕竟查找(SEEK)比扫描(SCAN)快
SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000'
SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000%'
SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '%销售组1000'
SELECT * FROM [dbo].[Department] WHERE [GroupName] LIKE '销售组1000%'
最最后,补充说一下
我们判断一个执行计划的性能的好坏的标准是什么??
就是哪个执行计划的逻辑读次数最少
Logical reads:包含该语句从内存数据缓冲区中访问的页数和从物理磁盘读取的页数。
如果全表扫描所使用的逻辑读比索引查找使用的逻辑读要少,那么SQLSERVER选择全表扫描这个执行计划就是好的
有些人为了让SQLSERVER使用索引,不惜代价使用查询提示,让SQLSRVER去走索引,这样是得不偿失的
我们的最终目的是:减少逻辑读次数,不要为了索引而索引!!
当然,我这里的实验环境跟各位的真实环境会有差别,不过“逻辑读次数”这个标准无论是哪个环境都是一样的!!
我说完了,谢谢大家o(∩_∩)o
physical reads:表示那些没有驻留在内存缓冲区中需要从磁盘读取的数据页。
Read-ahead reads是SQL Server为了提高性能而产生的预读。
如有不对的地方,欢迎大家拍砖o(∩_∩)o