摘要:
用数据说话,这是当前很流行的话题,本文将数据管理过程划分成4个层次,并阐述企业如何达到这四个层次。
1.初级量化管理:以数据“感知”项目的状况(相当于CMMI2级)
2.中级量化管理:通过经验值来管理项目(相当于CMMI3级)
3.高级量化管理:用PCB进行项目管理(相当于CMMI4级)
4.超级量化管理:持续优化的量化管理(相当于CMMI5级)
1. 前言
量化方面相关资料、理论非常多,如:六西格玛、统计过程控制(SPC)、过程能力基线(PCB)、软件度量、功能点法、软件估算等等。关于量化方面文章,大家可能难以把各文章的内容在脑袋中组织成一面知识网,主要因为各文章按照各自的角度阐述问题。我们需要一个统一的角度来描述这些事情,这里我们就以CMMI的为参考标准,对所有的量化理论进行“格式化”。
为了阐述方便,这里我们把与量化有关的内容,全部统称为“量化管理”,量化管理大致可以分为以下四个级别:
1) 初级量化管理-感知级,相当于CMMI2级。
2) 中级量化管理-经验级,相当于CMMI3级。
3) 高级量化管理-可预测级,相当于CMMI4级。
4) 超级量化管理-持续优化级,相当于CMMI5级。
高级别的量化管理,必满足所有低级别量化管理特点,例如高级量化管理,它具备初级量化管理、中级量化管理的特点,又具备本身的特点。
2. 量化管理的第一基本法则
我们为什么要用“功能点法”来估计项目的规模?
我们为什么要度量项目的工时、费用?
我们为什么要做量化管理?
如果我们不用量化管理的方式,也能达到量化管理的效果,而且成本更低,那还要不要进行量化管理?
当我们面对铺天盖地的量化理论的时候,当我们要考虑要做量化管理的时候,首先要问自己的问题就是:为什么要做量化管理?
我们回答一下这个问题:为什么要用“功能点法”来估计项目的规模?
如果老板想这样做,估计他感觉到项目的估算不是很准,他希望通过一些量化的办法,让项目的估算做得更准。所以,他的要进行量化管理的目的是:提高估算的准确率。
这就是老板的完整目标吗?如果员工们不计成本地把功能点法做好了,估算偏差提高到不超过5%,但估算工作需要的时间由原来的5天增加到50天,这样老板会接受吗?其实老板还有隐含的约束条件,就是不能太花成本。
如果把老板的目标再完整表达一下,应该是:在一定的时间成本要求内,提高估算的准确率。
无论我们做什么量化的工作,都必须先明确:
量化管理第一基本法则:明确量化管理的目的及约束条件。
“功能点”法是比较复杂而且难掌握的软件规模度量办法,有可能在研究使用的过程中,才发现不值得用“功能点”法,大家再反过来看看目标:在一定的时间成本要求内,提供估算的准确率,而不是:在一定的时间成本要求内,用功能点法提高估算的准确率。这时,大家可以选用别的办法,或者对“功能点”法进行改造。在制定目标的时候,不要把具体的方法写进去,目标是很高层次的,把办法写进去,也就是相当于限制了思路。
有人可能会说,“在一定的时间成本要求内,提高估算的准确率”,这个目标太虚了吧,写了等于没写。其实正是因为没有明确这个“虚”的目标,很多量化管理的工作变成就是为了量化管理而量化管理。其实六西格玛、统计过程控制(SPC)、过程能力基线(PCB)等量化管理办法,都要有很明确的目的。
如果企业对量化管理的目标都不明确的话,那就非常不好意思了,连初级水平都不是,是属于“无级别”的水平。
3. 初级量化管理-感知级
有很多软件企业,在项目过程中,须提交一些进度报告、总结报告,报告中可能会有进度情况、成本情况的一些数据。收集这些数据的目标也十分明确,就是想了解项目的进度、成本情况,并与计划的情况进行比较,采取必要的措施。
例:进度报告(节选)

在软件测试中,会记录各类缺陷的情况,并且在测试报告中报告缺陷的一些数据。项目组会根据缺陷方面的数据,分析软件的质量,并考虑后续的改进措施。
例:测试报告(节选):
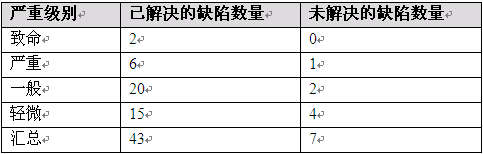
总缺陷数量:50
建议:需要在后续版本中修复没有解决的缺陷。
“感知级”的企业,有这样的一些特点:
1) 有明确的度量目的。
2) 有度量值的比较基准,如例子中的计划完成时间与实际完成时间的对比。
3) 被度量对象的属性定义得比较清楚,如上例中缺陷的属性。
4) 对度量的结果进行分析,并且要考虑改进措施。
“感知级”的企业,应该满足CMMI2级中MA(度量)这个PA的要求的(请参考CMMI相关标准)。
但下面这种情况,算不算“感知级”呢?
在项目总结报告中,统计项目进度、成本等情况,分析与计划比较的差异,提出对以后有用的改进意见。
如果只在项目总结报告的时候,才进行度量的话,是不能算“感知级”的,度量的结果要能用于项目管理,而不是项目结束后了统计出到一些数字,尽管这些数字可以用来改善以后的工作,但对该项目本身工作的改善已经没有任何作用了。
达到初级量化管理的企业,能明确量化管理的目标,通过合适的度量办法,“感知”项目的各类参数,并根据各度量指标的实际数值,采取改善项目行为的措施。
4. 中级量化管理-经验级
进行量化管理过程中,我们能得到各类参数值,但该参数值应该怎样才算合理呢?例如进度偏差多少才算合理?遗留缺陷数量多少个才算合理?
前面提到用“功能点”法来估算项目的规模,然后我们可以由规模导出工作量,但规模与工作量是怎样的一个关系呢?怎样根据规模导出工作量呢?相同规模的软件,不同的软件企业来做,导出的工作量是不一样的。
进行初级量化管理的时候,企业通过实际的参数值,来“感觉”项目的状况,当积累足够多数据的时候,管理者可能会找出项目间的一些共同的数据特点,如可以统计出“平均值”、“最大值”、“最小值”,这些数据,可以描述组织整体的性能。
当数据积累比较多的时候,组织级的经验数据,可以用来管理以后的项目,例如可以用组织的平均值做为量化管理的要求。这个时候,就达到了中级量化管理水平了。
中级量化管理有以下特点:
1) 对历史数据进行一定的分析,得出一些数值,从这些数据能大概掌握企业的能力状况。
2) 根据大概的企业能力状况,定出项目量化的管理目标,并用于管理项目。
3) 利用历史的经验数据,由项目规模导出工作量。
例:项目规模与工作量的关系

根据历史的经验数据,可以绘出规模与工作量的关系,由这个关系可用来估计新项目的工作量。如果没有大量的经验数据,这是不能做到的。
CMMI3级中,并没有专门的PA是与度量直接对应的,为什么说中级量化管理与CMMI3级的要求是对应的呢?CMMI3级的重要特点之一就是,有组织级的度量库,并且项目依据组织级度量库的数据,定义和管理项目的过程。中级量化管理与初级量化管理的最大区别就是,度量数据已经上升到组织级别,每个项目都可以利用组织的“经验”(即历史数据)来管理项目。
5. 高级量化管理-可预测级
麦当劳的薯条不少人都吃过,味道很好,而且每家麦当劳的薯条味道很一致。麦当劳是如何做到的呢?我们分析一下生产过程,我们发现薯条从原材料开始,到后续加工,油炸的时间,薯条炸出来后多少分钟没有售出,就销毁,整个过程都有严格的控制,而且很多地方是量化控制,时间甚至精确到秒。严格的过程控制,保证了薯条能高质量地稳定地产出。全球的麦当劳,都用同一的严格过程来管理,所以保证了全球的麦当劳的食品都是高质量的而且是高度一致的。从另外一个角度说,只要麦当劳按照既定的过程来生产食物,就可以“预测”出最终食物的情况,麦当劳将对最终产品的质量非常有信心。
那么我们软件开发,是不是也希望能达到这样的效果呢?大家可以回答一下这个问题:如果项目的规模、采用的技术、人员的水平等因素都确定了,那么您是否可以很有信心去预测这个项目的最终结果呢?
如果按照中级量化管理的办法,还是比较难达到这个效果的,“可预测级”的量化管理应该是怎样的呢?
在回答这个问题之前,我们需要先搞清楚什么是“稳定”的过程,什么是“不稳定”的过程。我们以“煮饭”为例,说明什么是稳定的过程什么是不稳定的过程。
大家小的时候可能都野炊过,野炊煮出来的饭可能普遍都是不太好吃的,不是太硬就是太软。为什么煮出来的效果会差异这么大呢?仔细分析一下,我们发现很多因素会影响煮饭的最终质量,如:饭锅、火候、煮的时间、水量等。当我们用野炊的方式煮饭时,这些因素都不太好控制,所以出来饭的质量变化就会比较大了。
我们换一种方式来煮饭,用电饭煲煮饭,失手的几率是不是极大地降低了?为什么会这样呢?当我们用电饭煲的时候,饭锅、火候、时间等因素都被“固定”在理想范围了,所以最终出来的结果是比较稳定而且质量比较好。
再看看我们的软件开发过程,1级的企业做出来的软件,结果是很不稳定的,而4级的企业,能稳定地输出比较好的结果。4级的软件企业,只需要确定了项目的规模、性质、技术、人员技能等因素后,只要按照既定的过程来生产软件,那么就可以很有信心地“预测”这个项目的最终结果,这个“预测”是有很高的可信度的。而CMMI2、3级的企业,虽然也能预测项目的最终结果,但只能“大概”预测,4级企业的预测能准确估计出最终结果的范围,而且这个范围是量化的。
CMMI2、3级的企业,过程还不能说是稳定的,而4级的企业,过程一定是稳定的。同样,初级、中级量化管理,用数据管理的过程,也不能说是稳定的,而高级量化管理,用数据管理的过程,一定是稳定的。
用数据管理过程,要进入“高级”阶段,就必须了解统计过程控制(SPC)的学问,要了解什么是基线(Baseline),所谓的六西格玛管理,其实就是统计过程控制。
例:某公司每周对项目的CPI(成本指数,这是项目挣值管理中的一个重要概念,请参考相关资料)进行度量,分析项目的实际性能。
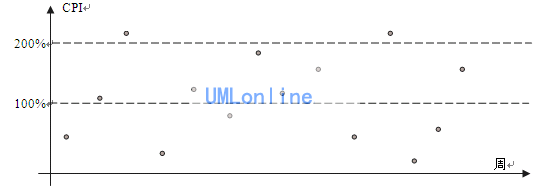
通过分析,发现CPI波动范围比较宽,从最低的10%到最高的210%,这样意味着最终项目的成本很可能会与预算相差1倍以上。作为管理者来说,这是不可以接受的,管理者希望最终的成本与预算相差在比较小的范围内。
为什么CPI会波动这么大呢?影响CPI波动的因素非常多,有估算、计划、过程、人的能力等等,如果要收窄波动,就需要在这些影响因素上下功夫,想办法减少这些影响因素的影响。经过改进后,项目的CPI情况如下:
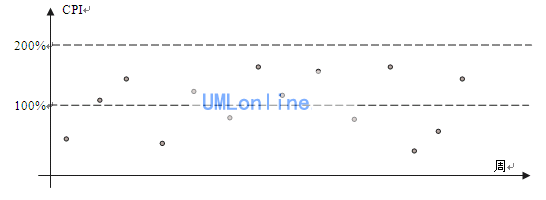
以上的做法是不是已经达到统计过程控制的层次呢?还不是,我们看看下图。
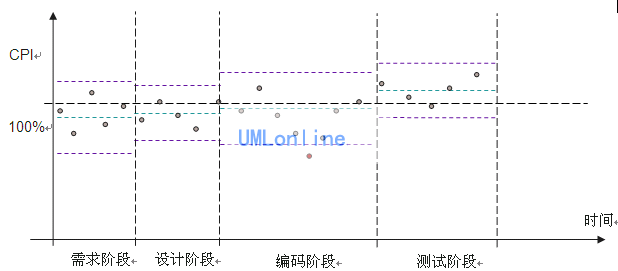
这个控制图,把整个项目过程分为四个阶段:需求阶段、设计阶段、编码阶段、测试阶段。每个阶段执行的过程不一样,工作的性质不一样,故绘制控制图的时候需要予以区分。对不同阶段的CPI数据点绘制XmR图,得出不同阶段的中值与上下限。用不同阶段的CPI的中值及上下限来监控项目的行为,项目管理的重点就是监控各数据点有没有超出上下限,对超出上下限的数据点,分析其原因并采取措施,使之回归到范围内。
所谓的统计过程控制是这样的一个过程:
1) 进行统计过程控制的过程是稳定的,影响该过程的各类因素,都被很好地控制在一定的范围内,故最终的结果也是在可控的范围内的并且是可预测的。
l 什么叫稳定?简单地说,就是在给定的条件下,产出的结果是在一定可接受的范围内的。如:只要项目性质和以前的项目差不多,项目的人员水平和以前的大体一致,执行的过程也和以前一致,那么该项目的结果应该是在可预测的可接受的范围内的。如果从统计学的角度,可以对数据点进行稳定性测试,判断其是否稳定(详细信息请参考SPC方面的书籍)。
2) 要对过程进行足够地细分,才能清晰地区分出各影响因素,使度量出来的数据点很容易识别是信号还是噪音。在进行数据分组的时候,保证数据之间的可比性是非常重要的,苹果只能跟苹果比,不能苹果跟香蕉比。很多做CMMI4级的企业,很容易犯这样的错误,没有很好地进行数据分组,进行数据分组的时候,要充分考虑项目的性质、人员的水平、所执行的过程等因素。数据分组是否合理的重要标准就是,是否能清晰区分出信号还是噪音。
l 什么是信号?信号可以说是“过程之音”,就是过程本身内在的特点所引起的正常波动,如项目的性质、技术、执行的过程、人员的水平等。信号反映了过程的正常的能力。
l 什么是噪音?噪音表明实际工作中出现了一些过程之外的特殊情况,如由没有具备项目管理技能的人来担当项目经理工作,而当前过程要求的是需要具备项目管理能力的人来负责的,这样过程执行效果肯定会与预计的效果发生比较大的偏差,从而超出上下限范围。信号体现了过程正在被正常执行,而噪音则反映出过程正在被偏离执行。
3) 数据点的偏差,是由公共原因(Common Cause)和可归属原因(Special Cause)共同作用下导致的。在控制限内的数据点的偏差,主要是由公共原因导致的,而超出上下限的偏差,则是由公共原因和可归属原因共同引起的。
l 什么是公共原因?公共原因是指过程本身特有的引起偏差的因素,如果人员的水平波动、项目性质的差异、执行过程的力度差异等,这些引起偏差的因素在本过程内已经被削弱,但不可能完全被消除,这些因素共同作用下,会引起数据点的正常波动。信号是由公共原因引起的。
l 什么是可归属原因?可归属原因是指出现了过程没有考虑或者违背了过程的情况,引入了新的引起波动的因素,如:没有安排好相应培训、没有按过程执行等。出现了可归属原因,将会加大数据点的波动,从而超出上下限范围。噪音是由公共原因和可归属原因共同作用引起的。
4) 通过统计学的办法计算出性能基线,如用XR图、XmR图。
5) 用性能基线进行项目管理,项目管理的重点是监控超出范围内的数据点,分析其原因,想办法排除可归属原因。消除可归属原因后,就可以消除由于可归属原因引起的波动,这样数据点就会重新回到上下限范围内。组织级应该有详细的进行可归属原因分析及问题解决的指导,项目经理根据该指导来排除可归属原因。
SPC的原理比较深奥,要深刻理解是不容易的。SPC在制造业等其它行业已经被广泛应用,其基本原理就是通过改造生产流水线,消除或者限制影响产品规格的因素,使产出的产品规格在一定的范围内并符合要求。
这个原理要用到软件生产,就没有那么简单了,影响软件质量的因素非常多,需要“功力深厚”的人分析各影响因素,并通过改造过程来消除或者削弱这些因素的影响。在这个层面上,用数据管理过程的“档次”已经提高了一大截,这时候数据管理的过程是稳定的过程,该过程的中值和上下限反映出该过程的能力。
这里我们引出一个新的问题,什么是有能力的过程?什么是没有能力的过程?什么是能力高的过程?什么是能力低的过程?
不稳定的过程,谈不上能力之说,稳定的过程才能谈能力。稳定的过程,可以通过不断地提高性能来提高能力,如收窄性能基线的上下限范围,使中值更接近理想的目标值等,这些都体现了能力的提高。
6. 超级量化管理-持续优化级
高级量化管理主要讲述的是如何把不稳定的过程变成稳定的过程,而超级量化管理主要讲述的是把有能力的过程变成更加有能力的过程。
前面提到的CPI中值和上下限,有可能不满足商业目标的需要,如CPI平均值达不是所期望的值,上下限的范围太宽,这样就有必要想办法做一些改进,提高能力,并且能力提高后的过程同样也是稳定的过程。
那么有什么办法可以提高能力呢?
1) 改进过程。过程的性能基线的中值及上下限,是由公共原因所引至的,要提高其性能,必须从这些公共原因入手,对信号进行分析,想办法进一步削弱公共原因引起的偏差,想办法改造过程,使中值符合要求。
2) 采用新技术。考虑引入新的技术,并调整相应的过程,来提高过程的性能。
3) 对噪音进行原因分析。噪音是由公共原因和可归属原因共同作用引起的,对每个噪音的可归属原因进行详细的分析,将很可能找到改进的机会。
分析过程的可改进地方是比较复杂的,有可能需要对过程进行更深一步的细分,可能会发现原来的数据分组达不到要求,需要增强粒度,以便区分出更多的公共原因,找出可改进点。另外,原来不需要进行基线级别管理的过程,可能也会因为商业目标的需要,需要建立基线并进行基线级别的管理。
在这个级别上用数据管理过程意义在于,通过数据来监控过程的改进效果,比较能力的变化,为决策提供依据。当形成新的更有能力的能力基线时,企业将用新的能力基线来管理项目。
SPC的建立及优化过程的成本是很高的,但进行SPC管理的过程的成功概率是非常高的,企业根据自己的商业目标需要,选择需要进行SPC管理的过程,并不断优化,使企业具备越来越强的竞争力,而这种竞争力是别的企业难以模仿并难以超越的。
7. 总结
由“感知级”到“经验级”,再到“可预测级”、“持续优化级”这个过程是不可跨越的,不同级别的“用数据管理过程”,都是由商业目标驱动的,只是不同级别所达到的量化管理程度不一样。
“感知级”通过软件度量,大概了解项目的状况,并作为工作调整的依据。
“经验级”通过软件度量,对比项目的历史经验数据,把握项目的状况,并进行相应的工作调整。同时,项目的历史经验数据,可供估算等工作进行参考。
“可预测级”,把“经验级”推向一个更高的高度,对影响问题的因素进行详细的分析,排除和削弱影响项目性能的各种因素,对历史经验数据进行合理分组,统计出性能基线,并用于项目管理。用基线来管理的过程都是稳定的过程,这些过程从统计角度来说都可以准确地预测出将来的结果。
“持续优化级”是“数据管理过程”的最高级别,达到这个级别意味着企业能根据商业目标持续的优化SPC管理,使企业形成别的企业难以模仿并难以超越的核心竞争力。
那是不是越高级越好呢?企业是不是都应该追求更高级的量化管理呢?
答案是否定的。
要实施“可预测级”的量化管理,是有条件限制的,就是过程要稳定,稳定就意味着项目间要有可比性,采用的技术、过程要大体一致。如果一个企业是创新型的企业,经常用新技术做新项目,这样项目的可比性就比较弱,就很难具备稳定的基础条件,很难形成基线。
所以,不能说CMMI级别越高的企业,就一定比级别低的企业管理要更好一点,有时候企业的特点就决定了企业不可能做到4、5级。各企业的最高领导,关键是清楚理解自己的商业目标,理解高级别的量化管理能带来什么帮助。
那为什么要“用数据管理过程”呢?
如果有一个非量化管理的办法,成本更低,并且能更有效地达到目的,那我们当然就采用那个办法,而不会片面地追求“用数据管理过程”了。所有想“用数据管理过程”的人士,都应该认真思考这个问题,并考虑哪种层次的量化管理级别适合您的商业目标。
作者:张传波
创新工场创业课堂讲师
软件研发管理资深顾问
《火球——UML大战需求分析》作者
www.umlonline.org 创始人