AMD Radeon R9/R7 系列显卡已经陆续发布,不过真正属于新一代产品的还是顶级的 R9 290X/290,它们都会采用“夏威夷”核心。虽然已有不少资料泄漏,但重量级的来了:国外某网站发表的 R9 280X 评测里竟然包含了夏威夷架构的详细解读,而且都是官方资料!

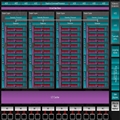
这就是夏威夷的架构图。44 个计算单元,比“塔希提”多了 12 组,每单元仍是 64 个流处理器,总计 2816 个,并分为四组“着色器引擎”(Shader Engine)。几何引擎、ROP 光栅单元也都划分到了这四组着色器引擎里,其中光栅单元每组 16 个,总计 64 个。
ACE 异步计算引擎达到了八个,是塔希提的四倍。显存控制器是六个 64-bit,总位宽达到了 512-bit。
右侧可以看到,以前的交火合成模块变成了新的交火 XDMA,而在它和 VCE 视频编码、UVD 视频解码引擎之间是新的TrueAudio DSP 音频模块。

顺便贴上塔希提的核心图,GCN 架构两代的区别就一目了然了。

R9 290X、HD 7970 GHz 规格提升对比:几何处理器能力增加 90%、浮点计算性能增加 30%、纹理填充率增加 30%、像素填充率增加 90%、显存带宽增加 20%。这一切的代价只是核心面积增加 24%,达到了 438 平方毫米。
不过单位面积浮点性能提升有限,仅仅5%。

作为基础模块的计算单元在架构上几乎原封不动,只做了一些细节上的改进。

可读写二级缓存容量从 768KB 增至 1MB,最多 16 个分区(之前 6 个),内部带宽也同样增加了三分之一。

显存位宽终于又出现了 512-bit,因此尽管 GDDR5 显存频率降低到了 5GHz,但总带宽增至 320GB/s,同时容量也有 4GB。最关键的是,高位宽带来的更大核心面积问题没有再出现,反而还小了大约 20%,这要归功于显存控制器重新设计等诸多因素。

八个 ACE 异步计算引擎,主要特性有:
- 独立调度、工作任务分派,多任务执行更高效
- 和图形指令处理器并行操作
- 每一个都可以管理最多 8 个请求
- 可访问二级缓存和全局数据共享
- 快速上下文切换
另外还有两个 DMA 引擎,均借助 PCI-E 3.0 x16 16GB 双向带宽与显存控制器沟通。

AMD R9、R7 系列主要阵容和性能等级。

R9 290X/290 是“发烧友的梦想”,不过价格仍然未定。R9 280X/270X 则是“游戏玩家的甜点”。

面向中低端的 R7 系列。