DHT抓取程序开源地址:https://github.com/h31h31/H31DHTDEMO
数据处理程序开源地址:https://github.com/h31h31/H31DHTMgr
1.当服务器查询本地一个文件是否存在都需要200MS的时候的时候你怎么办?(文件夹有4096个一级文件夹,每个文件夹有1000个文件,总大小在150G) 2.当服务器查询一条记录是否存在的时候需要500MS的时候你怎么办?(数据库有350万的数据纪录) 3.当服务器网站搜索关键词的时候需要5S左右的时候需要怎么办?(目前搜索采用SQL语句的LIKE查询)
问题1:先看下服务器移动文件中的花费时间:
4096个文件夹需要移动刚开始估计34个小时,看来当初的设计很有问题,光移动就需要花费这么久,以后数据再大点,设计如果需要修改还需要更多时间

最开始设计的是使用2位数字做为文件夹名字,最后发现一个文件夹下文件太多了,设计移动为三位数字母为文件夹名字,就到了目前这个状态,发现查询文件是否存在,
调用File.Exists()就需要花费200MS左右,查询数据库也需要花费500MS左右,到了需要考虑修改设计的问题了.
考虑迅雷服务器上如果下载种子的路径,发现是取用HASH字符的前两个字母为一级文件夹,取HASH字符串的最后两个字母为二级文件夹,这样就有256*256个文件夹,
比目前16*16*16=4096个文件夹多了很多,但这不是最关键的,查询二级文件夹里面的文件可能比一级文件夹快很多,目前猜测是这样的,不然迅雷服务器也不会这样设计.
目前服务器上已经跑了36小时还没有移动完,真是慢啊.
private void MoveTorrentFileToSubDirThread() { string pathname = H31Data.m_saveTorrentPath; //先直接创建后256*256个文件夹 for (int i = 0; i < 256; i++) { string temp1 = string.Format("{0}\\{1:X2}",pathname,i); if (!Directory.Exists(temp1)) Directory.CreateDirectory(temp1); for (int j = 0; j < 256; j++) { string temp2 = string.Format("{0}\\{1:X2}", temp1, j); if (!Directory.Exists(temp2)) Directory.CreateDirectory(temp2); } } DirectoryInfo filedir = new DirectoryInfo(pathname); foreach (DirectoryInfo NextFolder in filedir.GetDirectories()) { if (NextFolder.Name.Length == 3) { Int32 ticktime1 = System.Environment.TickCount; int cnt = 0; foreach (FileInfo fileChild in NextFolder.GetFiles("*.torrent")) { cnt++; try { string fc = fileChild.ToString(); int finddot = fc.IndexOf('.'); string hashname = fc.Substring(0, finddot); string tempname1 = hashname.Substring(0, 2).ToUpper(); string tempname2 = hashname.Substring(hashname.Length - 2, 2).ToUpper(); string pathname1 = Path.Combine(pathname, tempname1); string pathname2 = Path.Combine(pathname1, tempname2); string filename2 = Path.Combine(pathname2, fc); File.Move(fileChild.FullName, filename2); } catch (Exception ex) { H31Debug.PrintLn(ex.Message); } } try { Directory.Delete(NextFolder.FullName); } catch (System.Exception ex) { H31Debug.PrintLn(ex.Message); } Application.DoEvents(); Int32 ticktime2 = System.Environment.TickCount; LogTheAction(10, 1, NextFolder.Name + "文件夹" + cnt.ToString() + "个" + (ticktime2 - ticktime1).ToString() + "ms"); H31Debug.PrintLn(NextFolder.Name+"文件夹"+cnt.ToString()+"个"+(ticktime2-ticktime1).ToString()+"ms"); } else if (NextFolder.Name.Length == 1) { try { Directory.Delete(NextFolder.FullName); } catch (System.Exception ex) { H31Debug.PrintLn(ex.Message); } } } }移动种子文件到子文件夹下
问题2:服务器上查询花费时间长的问题:
由于服务器上对40字节的HASH值为唯一主键,之前数据很少时,只需要30MS左右,现在网站一起运营的时候,查询起来越慢,俗话说没有不好的硬件,只有不好的软件设计流程.

如何让程序少用数据库,从而让网站尽量使用数据库目前需要考虑的问题的.
由于以前的项目中使用过数据库批量插入文本数据的经验,目前考虑拿出来使用,减少数据库的压力.
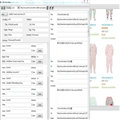
使用bulk insert批量插入数据,必须考虑每一个字段都必须对应上,

没有的可以空着,但必须有分隔符.比如下图的第一例就没有数据,因为对应表字段是自增的字段,没有办法填写,空着就行.
下面看下如何将文本数据插入数据库中,FIELDTERMINATOR是分隔符,ROWTERMINATOR是换行符,其它参数自己搜索下会更详细.
/// <summary>
/// 批量插入
/// </summary>
public static int BulkInsertFile(string tablename,string filepath)
{
try
{
string strSql = string.Format("BULK INSERT {0} FROM '{1}' WITH ( FIELDTERMINATOR='|',ROWTERMINATOR=';\\n',BATCHSIZE = 5000)", tablename, filepath);
return dbsql.ExecuteNonQuery(CommandType.Text, strSql.ToString(), null);
}
catch (System.Exception ex)
{
H31Debug.PrintLn("AddNewHashLOGFile" + filepath + ex.StackTrace);
}
return -1;
}
需要注意的问题有如何保证中文进数据库不是乱码的问题.
保存的时候使用ANSI编码.不用UTF8就行了.
StreamWriter writer = new StreamWriter(filename, true,System.Text.Encoding.Default); writer.WriteLine(content); writer.Close();
使用BULKINSERT批量插入就需要将HASH表里面的ID字段取消自增的属性,在本地操作基本上没有什么问题,因为本地数据量小,但一到服务器上就不行了,
12个表有一个表数据量大,修改不了,其它表修改成功,吓得直接冒汗了,
如果修改不了,批量插入的设计就是白白设计的,因为HASH表的ID字段被关联到其它表了,所以本地生成文件的时候这个ID必须有.
数据库去掉ID自增属性提示错误:
Microsoft SQL Server Management Studio
---------------------------
Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding.
网上找了一堆的方法,说是修改工具栏里面的选项,如下图所示:

发现修改后还是没有用,数据库重启也没有用.
急得不行的情况下,挂停网站,将数据库分离收缩附加回来再修改,还是执行超时.
在没有人请教的情况下,只能慢慢的GOOGLE搜索英文的文章了,终于发现一个修改注册表的方法了.
This timeout setting value is configurable through the DWORD value SQLQueryTimeout at HKEY_CURRENT_USER\Software\Microsoft \Microsoft SQL Server\90\Tools\Shell\DataProject. modifying SQLQueryTimeout to 300, but it still times out in 30 seconds.
刚开始修改为300秒也不行,直接修改为1800秒,也基本上无效,只能重启数据库,多点几次保存修改,后来有一次成功了.看来工具也需要有会配置的时候..
软件流程重新设计:
由于之前让数据库自动生成自增ID,目前看来是个错误的设计,现在只能在错一半基本上改了,因为重新跑一次所有数据,估计最少需要15天的时间.
现在尽量不与数据库实时打交道,程序启动时,遍历表的最大ID号,然后本地用来生成自增ID号直接存储数据到本地文件文件中,
就需要保证ID号自增的唯一性了,哪就需要考虑:
1.软件唯一运行的问题;
2.软件开始运行后保证以前生成的SQL批量文本文件全部插入到数据库中,然后才能去取最大ID号的问题;
3.生成的SQL批量文本文件需要考虑如果插入不成功就可能数据库已经存在的问题;
4.存在的情况下需要读取一条条插入的问题.
目前基本上软件的流程修改得差不多了,少用数据库,这就给网站查询速度更小的压力了.
问题3:网站查询速度很慢的问题
由于网站还是采用SQL的LIKE语句来搜索,所以时间大概在2-5S的时间,特别是搜索结果比较多的时候显示更慢.
经过大家的推荐使用hubble.net,Lucene.net目前分析的结果是采用Lucene.net.
由于服务器目前内存不够的情况下,只能让CPU用起来的问题了,Lucene采用文本来索引,占用内存少的情况下,目前只能这么架构测试了.
由于Lucene还在研究中,所以后期有什么不会的地方,请大家指点下.
总结:
1.目前还没有搞明白移动很多小文件需要这么长的时间.
2.批量插入会不会引起什么其它的问题还需要进一步观察.
希望有了解的朋友在此留言指教下.
大家看累了,就移步到娱乐区http://h31bt.com 去看看,休息下...
希望大家多多推荐哦...大家的推荐才是下一篇介绍的动力...
祝大家国庆节快乐.........
![[搜片神器]单服务器程序+数据库流程优化记录](/Upload/SmallIMG/2013100113/8E410204FB4FC319.jpg)