记得在刚找工作时,隔壁的一位同学在面试时豪言壮语曾实现过网络爬虫,当时的景仰之情犹如滔滔江水连绵不绝。后来,在做图片搜索时,需要大量的测试图片,因此萌生了从Amazon中爬取图书封面图片的想法,从网上也吸取了一些前人的经验,实现了一个简单但足够用的爬虫系统。
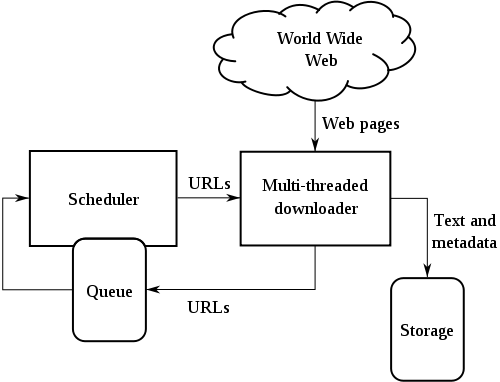
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成,其基本架构如下图所示:
?
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。对于垂直搜索来说,聚焦爬虫,即有针对性地爬取特定主题网页的爬虫,更为适合。
本文爬虫程序的核心代码如下:
Java代码
?
?
class="dp-j">
- public?void?crawl()?throws?Throwable?{??? ?
-
????while?(continueCrawling())?{??? ?
-
????????CrawlerUrl?url?=?getNextUrl();??
-
????????if?(url?!=?null)?{??? ?
- ????????????printCrawlInfo();???? ?
-
????????????String?content?=?getContent(url);??
- ??????????????? ?
-
?????????????
-
????????????if?(isContentRelevant(content,?this.regexpSearchPattern))?{??? ?
-
????????????????saveContent(url,?content);??
- ?? ?
-
?????????????????
- ????????????????Collection?urlStrings?=?extractUrls(content,?url);??? ?
- ????????????????addUrlsToUrlQueue(url,?urlStrings);??? ?
-
????????????}?else?{??? ?
-
????????????????System.out.println(url?+?"?is?not?relevant?ignoring?...");??? ?
- ????????????}??? ?
- ?? ?
-
?????????????
-
????????????Thread.sleep(this.delayBetweenUrls);??? ?
- ????????}??? ?
- ????}??? ?
- ????closeOutputStream();??? ?
- }?? ?
?
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
?

files/uploadimg/20110309/1015301.gif">
?
?
- private?CrawlerUrl?getNextUrl()?throws?Throwable?{??? ?
-
????CrawlerUrl?nextUrl?=?null;??? ?
-
????while?((nextUrl?==?null)?&&?(!urlQueue.isEmpty()))?{??? ?
-
????????CrawlerUrl?crawlerUrl?=?this.urlQueue.remove();??? ?
- ?????????????????? ?
-
?????????
-
?????????
-
?????????
-
????????if?(doWeHavePermissionToVisit(crawlerUrl)??? ?
- ????????????&&?(!isUrlAlreadyVisited(crawlerUrl))???? ?
- ????????????&&?isDepthAcceptable(crawlerUrl))?{??? ?
- ????????????nextUrl?=?crawlerUrl;??? ?
-
?????????????
- ????????}??? ?
- ????}??? ?
-
????return?nextUrl;??? ?
- }???
?
更多的关于robot.txt的具体写法,可参考以下这篇文章:
http://www.bloghuman.com/post/67/
getContent内部使用apache的httpclient 4.1获取网页内容,具体代码如下:
Java代码
?
?
- private?String?getContent(CrawlerUrl?url)?throws?Throwable?{??? ?
-
?????
-
????HttpClient?client?=?new?DefaultHttpClient();??? ?
-
????HttpGet?httpGet?=?new?HttpGet(url.getUrlString());??? ?
-
????StringBuffer?strBuf?=?new?StringBuffer();??? ?
- ????HttpResponse?response?=?client.execute(httpGet);??? ?
-
????if?(HttpStatus.SC_OK?==?response.getStatusLine().getStatusCode())?{??? ?
- ????????HttpEntity?entity?=?response.getEntity();??? ?
-
????????if?(entity?!=?null)?{??? ?
-
????????????BufferedReader?reader?=?new?BufferedReader(??? ?
-
????????????????new?InputStreamReader(entity.getContent(),?"UTF-8"));??? ?
-
????????????String?line?=?null;??? ?
-
????????????if?(entity.getContentLength()?>?0)?{??? ?
-
????????????????strBuf?=?new?StringBuffer((int)?entity.getContentLength());??? ?
-
????????????????while?((line?=?reader.readLine())?!=?null)?{??? ?
- ????????????????????strBuf.append(line);??? ?
- ????????????????}??? ?
- ????????????}??? ?
- ????????}??? ?
-
????????if?(entity?!=?null)?{??? ?
- ????????????entity.consumeContent();??? ?
- ????????}??? ?
- ????}??? ?
-
?????
- ????markUrlAsVisited(url);??? ?
-
????return?strBuf.toString();??? ?
- }?? ?
?
对于垂直型应用来说,数据的准确性往往更为重要。聚焦型爬虫的主要特点是,只收集和主题相关的数据,这就是isContentRelevant方法的作用。这里或许要使用分类预测技术,为简单起见,采用正则匹配来代替。其主要代码如下:
Java代码
?
?
- public?static?boolean?isContentRelevant(String?content,??? ?
- Pattern?regexpPattern)?{??? ?
-
????boolean?retValue?=?false;??? ?
-
????if?(content?!=?null)?{??? ?
-
?????????
- ????????Matcher?m?=?regexpPattern.matcher(content.toLowerCase());??? ?
- ????????retValue?=?m.find();??? ?
- ????}??? ?
-
????return?retValue;??? ?
- }?? ?
?
extractUrls的主要作用,是从网页中获取更多的URL,包括内部链接和外部链接,代码如下:
Java代码
?
?
- public?List?extractUrls(String?text,?CrawlerUrl?crawlerUrl)?{??? ?
-
????Map<string,?string>?urlMap?=?new?HashMap<string,?string>();??? ?
- ????extractHttpUrls(urlMap,?text);??? ?
- ????extractRelativeUrls(urlMap,?text,?crawlerUrl);??? ?
-
????return?new?ArrayList(urlMap.keySet());??? ?
- }??? ?
- ?? ?
-
?
-
private?void?extractHttpUrls(Map<string,?string>?urlMap,?String?text)?{??? ?
- ????Matcher?m?=?httpRegexp.matcher(text);??? ?
-
????while?(m.find())?{??? ?
- ????????String?url?=?m.group();??? ?
-
????????String[]?terms?=?url.split("a?href=\"");??? ?
-
????????for?(String?term?:?terms)?{??? ?
-
?????????????
-
????????????if?(term.startsWith("http"))?{??? ?
-
????????????????int?index?=?term.indexOf("\"");??? ?
-
????????????????if?(index?>?0)?{??? ?
-
????????????????????term?=?term.substring(0,?index);??? ?
- ????????????????}??? ?
- ????????????????urlMap.put(term,?term);??? ?
-
????????????????System.out.println("Hyperlink:?"?+?term);??? ?
- ????????????}??? ?
- ????????}??? ?
- ????}??? ?
- }??? ?
- ?? ?
-
?
-
private?void?extractRelativeUrls(Map<string,?string>?urlMap,?String?text,??? ?
- ????????CrawlerUrl?crawlerUrl)?{??? ?
- ????Matcher?m?=?relativeRegexp.matcher(text);??? ?
- ????URL?textURL?=?crawlerUrl.getURL();??? ?
- ????String?host?=?textURL.getHost();??? ?
-
????while?(m.find())?{??? ?
- ????????String?url?=?m.group();??? ?
-
????????String[]?terms?=?url.split("a?href=\"");??? ?
-
????????for?(String?term?:?terms)?{??? ?
-
????????????if?(term.startsWith("/"))?{??? ?
-
????????????????int?index?=?term.indexOf("\"");??? ?
-
????????????????if?(index?>?0)?{??? ?
-
????????????????????term?=?term.substring(0,?index);??? ?
- ????????????????}??? ?
-
????????????????String?s?=?"http://"?+?host?+?term;??? ?
- ????????????????urlMap.put(s,?s);??? ?
-
????????????????System.out.println("Relative?url:?"?+?s);??? ?
- ????????????}??? ?
- ????????}??? ?
- ????}??? ?
- ?? ?
- }?? ?
?
如此,便构建了一个简单的网络爬虫程序,可以使用以下程序来测试它:
Java代码
?
?
- public?static?void?main(String[]?args)?{??? ?
-
????try?{??? ?
-
????????String?url?=?"http://www.amazon.com";??? ?
-
????????Queue?urlQueue?=?new?LinkedList();??? ?
-
????????String?regexp?=?"java";??? ?
-
????????urlQueue.add(new?CrawlerUrl(url,?0));??? ?
-
????????NaiveCrawler?crawler?=?new?NaiveCrawler(urlQueue,?100,?5,?1000L,??? ?
- ????????????????regexp);??? ?
-
?????????
-
?????????
-
?????????
- ????????crawler.crawl();??? ?
-
????}?catch?(Throwable?t)?{??? ?
- ????????System.out.println(t.toString());??? ?
- ????????t.printStackTrace();??? ?
- ????}??? ?
- }?? ?
?
当然,你可以为它赋予更为高级的功能,比如多线程、更智能的聚焦、结合Lucene建立索引等等。更为复杂的情况,可以考虑使用一些开源的蜘蛛程序,比如Nutch或是Heritrix等等,就不在本文的讨论范围了。

- 大小: 14.5 KB