class="topic_img" alt=""/>
class="topic_img" alt=""/>
�����ÿ�ѧʵ����������Щ������ζ����ά����
����ǰ�������̵����ǣ���Ϊ������Ա����������Ҫ��ְ����Dz�Ҫд�ô��롣�������ǵ�����ս����ֻ��д���кܿ�ͻ����õ� Perl �ű����ѣ���������Ҫ��һ�㣬������д�Ĵ�����������Ķ�����������������Ʒ���������������У���ά���Ĵ���ͨ�������������ͬ���Ǵ����ڵ���ǰʹ������ĺܶ�ʱ�䡣
����Ȼ�������´���ɶ��Բ��ԭ��ȴ��������ô�����������Ϊʲô������д��������ģʽ�������������֮��Ķ������ڵ�ԭ��֮һ��һ��������֪������ Martin Fowler��1��д�ġ��ع����Ȿ�飬����������һϵ�еĴ�����ζ�Լ�ȥ����Щ��ζ���ع����ԡ�����ӵ������ɹ��۵���Դ��������Ȼ������ս——����Ҫѧϰ�ܶ��ع����ԣ�����Ҫ������Щ�����ȼ��Ƚϸߡ���Ȼ�����Dz�����ͬ����Ҫ��������ε�֪�������Ĵ����ع��������г�������Ч���أ�
������������ Martin Fowler ���ع���û���ἰ��Щ������ζ�ǹؼ��ģ���Щ���ǡ�Fowler ���Լ�Ҳ�ᵽ��û���ĸ�����ָ���ܹ��ȵ����˵�ֱ����������Ϊ������Ա��˵ֻ������ֱ���;���ȥ�����Ƿ���Ҫ�ع����������һ��ج�Ρ����һ������ǧ��������ζ��ϵͳ����Ҫ�Ӻδ����֣�����֮�⣬�κζԴ���ĸĶ������ܴ��������ĸ����á������и��������Զ����������Ĵ��볣���̺��߷��ն��Ҵ��۰������֪����Щ������ζ������ƻ��ԣ��Ȱ����Ǵ������ͺ��ˡ����⣬����ϣ���������չʾ�����Dz������˷�ʱ����Ϊ��дƯ�������дƯ�������ϣ��������ǵ�ǰ��Ŭ���ܹ���δ��Ϊ��Ŀ��������Ч�档
���������䡿�������������������е��κο��ܵ������������֢״�����Խ���������ζ��
����ͨ�����ڶԴ�������̵ķ�������ʱ��������ζ�ᱩ¶��һЩ���ε����⣬����ķ�����������ָ��һ��С��Χ�ġ��ɿصķ�ʽ�ع����롣������Щ��¶�����⣬���ǻ��һ���ļ����ƺʹ������Ƿ��ڱ��������ζ��Ȼ��������һ�����ع����Ӹ����ع��Ŀ����ߵĽǶ�������������ζ����������ʱ�ع�������ع�����ˣ�����˵������ζ�ƶ����ع��Ľ��С���ժ��ά���ٿƣ�
����2009 �꣬Ų�� Simula �о�����Ҫ��һ���ڲ�ϵͳ�����һ���µ����ݹ���ϵͳ�������Ŀ������� 6 �� Java ������Ա�������Ŀ����Ϊ�������о�������ζ�Կ�ά�������Ӱ��Ļ��ᡣ
�����������Ŀ�������������У�����ʹ����һЩ����������������ζ��ÿ�����Щ������Ա��̸������ÿ��������Ա�� Eclipse IDE �϶���װ��һ����־��¼���ߡ������־��¼���߲�����¼��ÿ���ļ����˶ʱ�䣬���Ҽ�¼�˻�������������Լ����Ĵ��������ѵ�ʱ�䡣 �������Ŀ�����У�����ʹ��һ�������ٹ��ߵǼ�����Щ������Ա�����ٵ����⣬Ȼ�����ٵ���Щ���������Դ�����ļ�������֮�⣬���еĿ�����Ա��Ҫ������̸������������ռ���������ԶԶ���ڳ���Ľ�����������ֿ�ķ��������������õ��Ĺ۲�����
�����۲���1����������ʵ����⣡
������Դ��https://simula.no/publications/Simula.simula.1460
����“������֪��”�������Dz��õģ����ǵ��ײ��õ�ʲô�̶ȣ�����ͼ��ʾ��
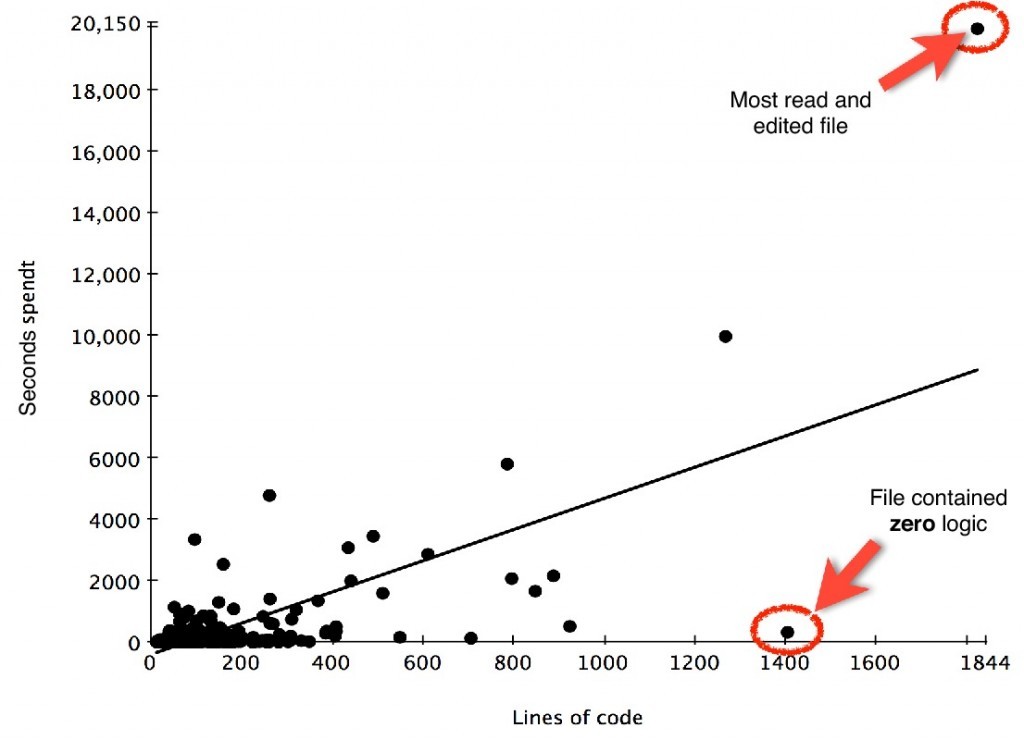
����Y ���������Ŀά���ڼ仨�����Ķ���һ���ļ��ϵ�ʱ�䣻X������ļ��Ĵ�С��
������ע�⣬�Ķ����������ļ���1844 �д��룩Ҫ����ʱ���Ǵ��ļ������� 600 �д��룩�� 10 �����ϡ�����ļ�����һ�������ࡣ������ע�⣬20000 ������ 5 ��Сʱ�Ĺ���������һ���ļ���˵̫���ˣ��������ǻ����Կ����༭��һ�����ļ�����Լ 1400 �д��룩û�л����ܶ�ʱ�䡣������ļ������˺ܶ�ķ�������������û�а����κ����������ȫ���ࣩ���������Ϊʲô������Աû�������滨̫��ʱ�䡣�����������Ĵ��ļ�����ȫ���ࣩ������Ӱ���ά���ԡ�
�������飺��Ӧ�ðѰ����������Ĵ��ļ��ָ��С�ļ���һ���Ƽ�����ֵ�ǽ��ļ���С������ 1000 �д����ڡ�
�����۲���2�� �����ſ�û���������ô���……
������Դ��https://simula.no/publications/Simula.simula.1456
����“�����ſ飨Data Clump��”��ָһЩ������û������Եķ����ͱ������ϡ�һ������£����������ſ���ļ������˲�ͬ���͵ı������������һϵ�еķ����������������磬��ͼ�� Person ���������˲�ֱ�Ӹ�һ������ص���Ϣ����˿��Ա��ָ�������ࡣSimula ���о���Ա������һ��ͳ��ģ�������ʹ�����ζ�ij����Ƿ������˿�����Ա��ά����������������Ŀ����ԣ����ǻ��¼ά�����������ٵ����������Լ���Щ����������ļ�����������������ʵ����Щ���������ſ���ļ�����ά������Ŀ����Ը��ͣ�
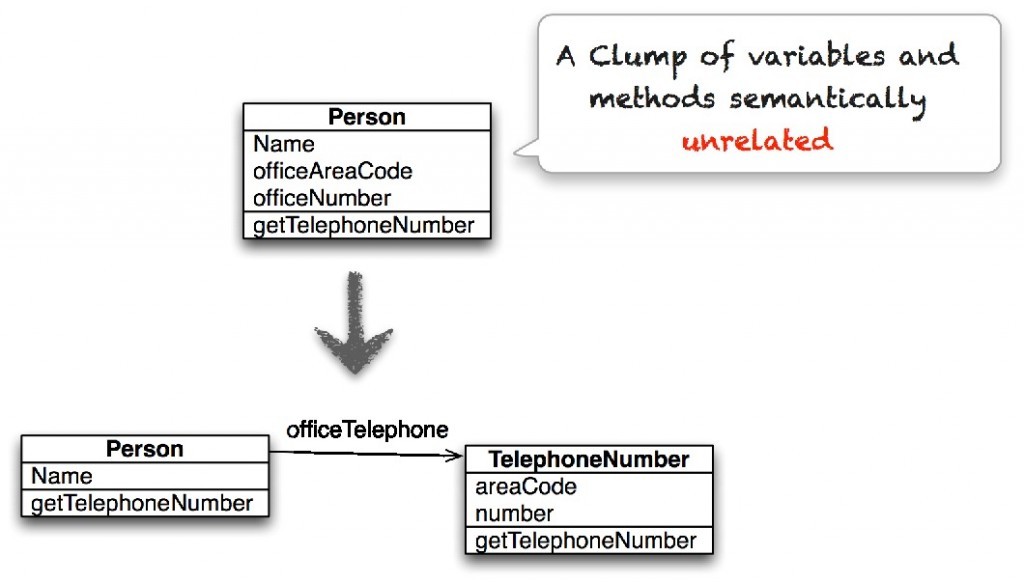
�������飺��Ҫȥ����Щ�����ſ飬�������ǰ���������������ζ��
�����۲���3�� ����ӿ�����ԭ��
����Robert C. Martin��Bob ���壩�����˽ӿڷ���ԭ��ISP����Ϊ SOLID ԭ��2����һ���֡�
�����ӿڷ���ԭ��ָ�����κ�������ĵ����߶���Ӧ�ñ�ǿ����������û�е��õķ������ӿڷ���ԭ��ѷdz��Ӵ�Ľӿڷָ�ɸ�С������ȷ�Ľӿڣ��Ӷ�ʹ�õ�����ֻ��Ҫ֪�����������ĵķ�����
�����������̵��о����ǡ�3����������ʹ�ô���������ȥ����һЩ������ζ����Щ��ҵ����ʵ������Щ��������������Ҳ��������Լ���̽����Բ����ڹ�����ʵ�����ǣ����� Java �е� SonarQube ���� .Net �е� NDepend����ͼչʾ�� Simula ʹ�õ�̽����ԣ���������ǻ����о�Ա Radu Marinescu��4���Ĺ�������ġ�
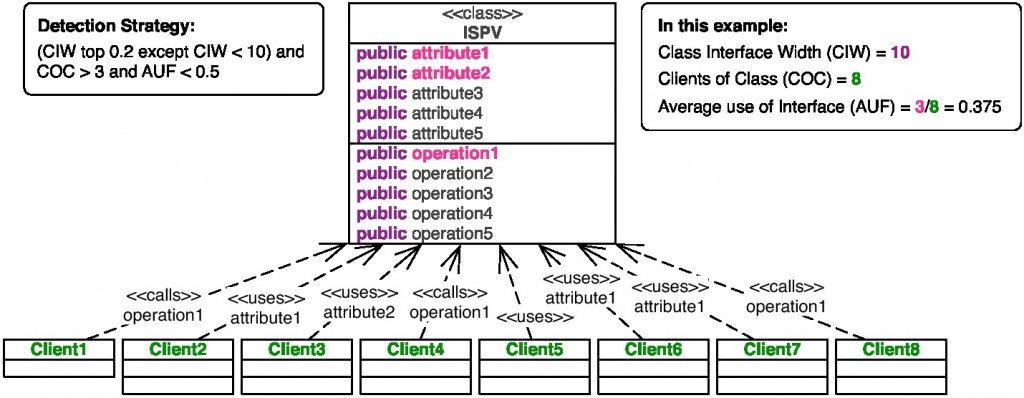
������������“�ӿڿ���”���������ķ��������Ը�����Ϊ 10�����“������”��ĿΪ8��“ƽ���ӿ��ö�”������������ʹ�õķ��������Ը������Ե�������Ŀ��Ϊ 0.375���������̽����ԣ���������Υ���˽ӿڷ���ԭ��.
�������������ſ�ķ���ͬ��������Υ���ӿڷ���ԭ����ļ���������ֵ�һ���ļ�Υ���˽ӿڷ���ԭ��ʱ������������ĸ��ʵĸ��ʻ����ӡ�
��������ͼ��ʾ��Υ���ӿڷ���ԭ����ļ���û��Υ����ԭ����ļ�������ĸ���Ҫ�ߣ���Լ 30%������Ҳӡ֤�������۵㡣
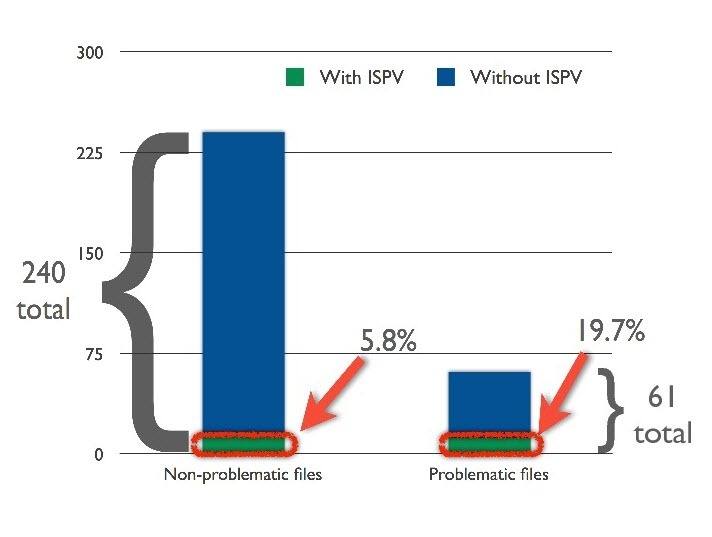
�������飺�ָ���Щ���ڿ�������;����Ľӿڿ��Լ���ά��ʱ��������ķ��ա�
�����۲���4��������ζ������Ⱥ��ӳ���
������Դ��https://simula.no/publications/Simula.simula.1508
������ͬһ��ʵ���У�ijЩ������ζ���ֳ���ͬһ���ļ���һ����ֵ����ơ�����ͼ��ʾ��ʶ������Ĵ�����ζ����������ͬһ���ļ��“��ζ�ڻ���”�����Ͼ�����Щ��Ҫ�ڻ�����ϵͳ���ܵ��ļ���“��������”����Щ���ļ�����������Ĵ�����ζ���������飬“�����ӿ�”��“��������”�ĺ������Dz��������ġ�

�������飺�������һ���ļ��з�����ij�����͵Ĵ�����ζ��������Ҫ������Ƿ����������“��ζС���”��ͬ���ļ��еĴ�����ζ��ϻ����ӷ��գ����ٿ�ά���ԣ�
���������Զ�
�������� Fowler ��˵������Ҫ���Լ���ֱ����������ж���������Щ��Ҫ�ع����������и��ݿ�ѧ�о��ó���������������������ȼ���
�������ֵ��ع��ɣ�
������1�����ع�:���Ƽ��д������ơ�
������2����������������(ԭ��ģʽ��ʵ��) ��
������3��http://sewiki.iai.uni-bonn.de/research/cultivate/tutorial_exploring_smells_and_metrics
������4��http://loose.upt.ro./download/thesis/thesis.zip
�������䣺�����Ĵ�����ζ