??????? 前阵子写了一个RPC服务,测试的过程中,同时在测试的过程中反应间歇性超时比较严重,我的第一反应就是gc有问题,于是就观察了一阵子GC情况,发现这个服务的YGC时间有点不太正常,快的时候也就几十ms,慢的时候几十秒,总体上说就是快慢波动比较明显。
?
??????? 先说说这个服务,这个服务里面有个后台线程,每10分钟会去读一个大文件,然后将文件的数据缓存到本地,这个文件大概有100M不到,也就是说每10分钟,即使没有对外服务的情况下,也会有一次内存的加载过程,会产生一个内存波动。
?
??????? 为了查这个超时的问题,也恶补了一些JVM的相关知识,首先我的疑问是,YGC时间长会影响到服务超时?我之前一直以为YGC是不会stop the world的,只是copy。我试着在程序YGC的过程中,去访问这个服务,发现确实在长时间YGC的过程中,超时情况很严重,待YGC停止后,再访问服务,就很快响应了,所以事实摆在眼前,发现YGC的过程确实是有暂停服务的嫌疑,通过查看JVM参数,发现服务使用的CMS的GC方式,查阅相关的资料,得知CMS的YGC和并行GC的方式一样,stop-the-world + copy。确实是YGC时间过长导致服务超时比较严重,这样算是把超时问题的原因给定位了。
?
?????? 那究竟是什么原因导致YGC时间会很长呢,通过用jstat观察我发现一个问题,就是每次Eden区满的时候,一执行ygc survivor区几乎就直接100%了。我当时的感觉就是survivor区太小,eden区大?于是我试着调整了一下-XX:SurvivorRatio参数,默认这个值是8,也就是S0 :S1 :Eden之间的比例是1:1:8,我把这个比例改成了1:1:3,改完之后,通过一个晚上的观察,发现情况有所好转,但是这个问题还是存在,前几次YGC几乎都是很短时间就完成了,但是随着时间的积累,YGC时间过长的问题还是会出现。
text 写道 S0 S1 E O P YGC YGCT FGC FGCT GCT???????
????????? 接着我继续观察,加上gc log观察gc时间情况,加上如下参数,先解释下,-XX:+PrintGCTimeStamps -XX:+PrintGCDetails 是打印出gc的发生时间和gc的详细日志,-XX:+PrintHeapAtGC 是打印gc前后的堆情况,-XX:+PrintGCApplicationStoppedTime 是打印每次gc的停顿时间。通过gc日志和jstat观察,发现只有survivor区中的一个快满的时候,假设现在快满的是S0,这时候发生YGC时,它是直接把GC的东西放入S1中,而S0里的内容并没有放入S1里,这样就出现了Jstat 状态里的S0,S1,和Eden区几乎都是100%的情况,当三者都满时,Eden里释放不了的东西就直接进Old区了,同时YGC也正常发生,这种情况下的GC停顿时间就特别长。这只是个现象,只能说在满足这个条件下时,YGC的时间就特别长。
?
??????? 通过查阅相关JVM的资料,发现正常情况下S0和S1只有一块空间是有内容的,但是我这里的情况看上去,S0和S1在GC的过程中都是满的,这是我的一个疑问?问题还是没有解决,但是冥冥之中有种暗示,就是再满足这个情况下的时候就会出现YGC时间过长的问题,真的是这样吗?我继续观察。
???????
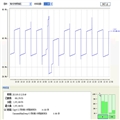
??????? 这次我想到了jconsole,曾经查一次gc的问题中,也用过它。其实用它只是为了更好的把gc的情况图形化,而且是实时的呈现。有时候数据往往看不出的端倪,放到图形里就能激发你的灵感,也许这就是为什么boss喜欢看报表吧。既然我找到了呈现问题的方式,那我就试着让JVM达到我想复现的YGC条件,我写了一个测试类,目的就是让它频繁调用这个服务,让其Eden区快速的涨起来,以触发YGC,在s0区域快满的时候,我开始执行我写的那个类,果然Eden区迅速的满了,但是情况并不是像我想象中的那样,YGC情况很快,YGC发生后,Eden区的内容往S1里转移,同时S0的内容也交换到了S1里,S0交换后也清0了,这个发现让我有了新的发现。我就想,难道是调用产生的新对象因为调用完毕,失去引用而直接回收了,进而虽然Eden区是满的,实际copy到survivor区的内存只有一部分?为了证实我的想法,我等待的下一次load数据,当load完数据后,我又调用我写的那个类方法,这次想象和我预期的一样,S1的数据交换到S0,Eden区也迅速释放出去了,YGC也进行的很快。看来问题已经有点眉目了。
???????
??????? 接下来我试着jmap -histo {pid},看看堆中到底是些什么对象一直没回收,我发现每次YGC一直在增长的对象就是load文件里的小对象,我猜想这些对象因为是常驻内存的,所以回收起来肯定没有方法调用中产生的临时对象回收的快,所以我猜想每次在S0和S1中交换的对象大部分都是load文件后常驻内存的小对象。这时候又一个疑问产生了,为什么每次YGC这些对象都不被回收,不会有溢出吧,于是我试着用jconsole执行一次full gc,再jmap观察,发现小对象也回收了,S0和S1也被清除的干干净净,我的疑问这才算解决了,原来这种常驻内存的对象是不会轻易的被YGC给回收掉,不过我也没多想,因为full gc是可以回收掉它的,也就是说没有OOM的问题。
???????
??????? 通过上面的发现,既然交换区的内存基本上都是本地缓存里的东西,那是不是只要保证交换区的空间一定可以装下Eden区里YGC回收不了的内存就可以保证YGC快速的完成?为了测试它的极限,我决定再调一次JVM的参数,我这时候把SurvivorRatio的比例放到了1,也就是说即使Eden区里的东西完全不被YGC回收,也可以保证Eden区迅速的被交换到survivor区。通过一个晚上的观察,发现这个结论和我预想的一样,YGC整体平稳,时间也比较理想,S0和S1始终有一块区域是空的。另外一个惊喜的发现是,一个晚上没有fullGC,我想这个原因应该是内存在交换空间里多次交换后,慢慢又被YGC给回收了的原因,导致每次YGC几乎就没有新的对象进入Old区,只要Old区不往上增长,那full gc自然就不怎么发生了。
?
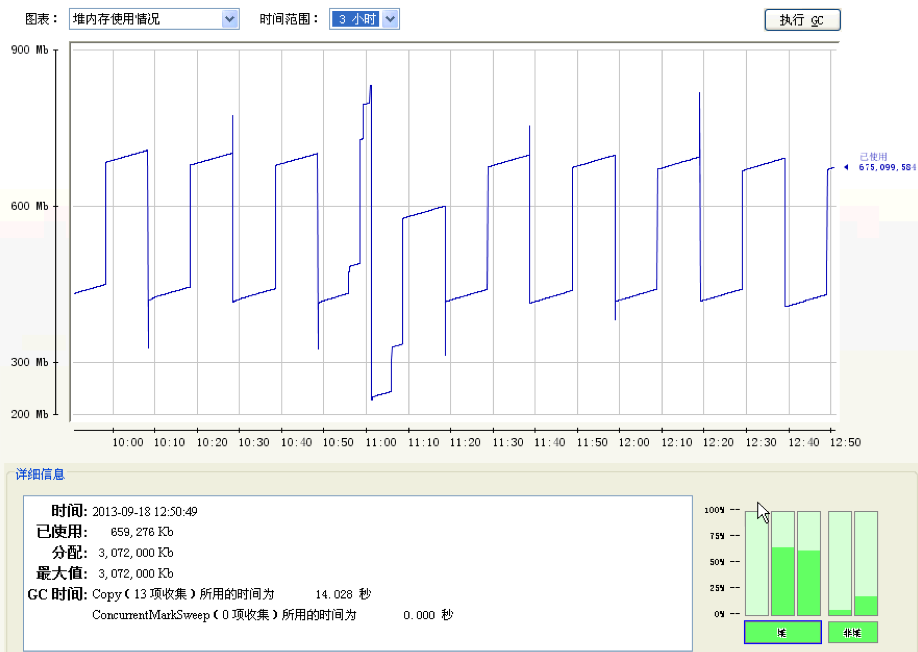
???????? 这个问题到这里应该已经彻底解决了。最后附上一张jconsole的堆内存监控截图来结束这篇JVM调优日志。
?
?
?
?
????
class="quote_title">?