背景:最近在做一台线上服务器IO负载情况的时候发现了以下现象:
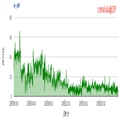
24小时的IO_UTIL 的曲线看似风平浪静,毛刺较少
但当图片放大到半小时级别的时候发现IO_UTIL即磁盘使用率出现了规律性的波动,见下图:
本文就将从这个现象触发,探究出现这样规律性波动的原因。
Step1: 服务器上进行实时IO负载查看
通过iostat -x 1 每隔一秒对IO使用情况进行一次负载查看。可以看到UTIL有规律性的波动(10秒1次)。
且负载的主要来源在于写请求(负载高时,wsec/s 也同步升高)
又由于服务器是MySQL独占,所以比较容易的就可以将原因归结为是MySQL的数据刷写导致(log/data)。
看到这里大神们应该已经不难猜到是MySQL内部 src_master_thread 中10_seconds 循环捣的鬼了。
为了保证诊断思路的连贯性,接下来还是把当时的操作复述一遍。
root@db-mysql-tg03b.nh:/root>iostat -x 1 vgca0 |grep vgca0
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util vgca0 0.00 0.00 12.96 371.75 1562.56 24314.49 67.26 0.37 0.28 0.28 10.62 vgca0 0.00 0.00 2.00 2.00 40.00 138.00 44.50 0.00 1.00 1.00 0.40 vgca0 0.00 0.00 1.00 2.00 32.00 170.00 67.33 0.00 1.00 1.00 0.30 vgca0 0.00 0.00 3.00 2.00 96.00 130.00 45.20 0.00 0.80 0.80 0.40 vgca0 0.00 0.00 4.00 2.00 128.00 178.00 51.00 0.00 0.67 0.67 0.40 vgca0 0.00 0.00 1.00 5.00 32.00 170.00 33.67 0.00 0.83 0.83 0.50 vgca0 0.00 0.00 0.00 1868.00 0.00 101510.00 54.34 1.28 0.16 0.16 30.20 vgca0 0.00 0.00 7.00 2.00 200.00 130.00 36.67 0.10 12.78 12.78 11.50 vgca0 0.00 0.00 1.98 1.98 39.60 160.40 50.50 0.00 1.00 1.00 0.40 vgca0 0.00 0.00 6.00 2.00 168.00 170.00 42.25 0.00 0.88 0.88 0.70 vgca0 0.00 0.00 4.00 26.00 104.00 5026.00 171.00 0.02 0.73 0.73 2.20 vgca0 0.00 0.00 10.00 2.00 296.00 164.00 38.33 0.04 3.92 3.92 4.70 vgca0 0.00 0.00 1.00 2.00 8.00 138.00 48.67 0.00 1.00 1.00 0.30 vgca0 0.00 0.00 2.00 2.00 40.00 162.00 50.50 0.00 1.00 1.00 0.40 vgca0 0.00 0.00 3.00 2.00 72.00 170.00 48.40 0.00 0.80 0.80 0.40 vgca0 0.00 0.00 2.00 6.00 40.00 172.00 26.50 0.00 0.50 0.50 0.40 vgca0 0.00 0.00 2.00 601.00 40.00 32942.00 54.70 0.39 0.17 0.17 10.40 vgca0 0.00 0.00 2.00 1179.00 16.00 63932.00 54.15 0.82 0.17 0.17 19.90 vgca0 0.00 0.00 3.96 1.98 126.73 144.55 45.67 0.00 1.50 1.50 0.89 vgca0 0.00 0.00 3.00 2.00 96.00 170.00 53.20 0.00 1.00 1.00 0.50 vgca0 0.00 0.00 4.00 3.00 104.00 162.00 38.00 0.00 0.86 0.86 0.60 vgca0 0.00 0.00 1.00 2.00 8.00 138.00 48.67 0.00 0.33 0.33 0.10 vgca0 0.00 0.00 6.00 2.00 168.00 178.00 43.25 0.00 1.12 1.12 0.90 vgca0 0.00 0.00 5.00 2.00 136.00 138.00 39.14 0.00 0.86 0.86 0.60 vgca0 0.00 0.00 4.00 2.00 104.00 170.00 45.67 0.00 0.83 0.83 0.50 vgca0 0.00 0.00 2.00 2.00 40.00 162.00 50.50 0.00 1.00 1.00 0.40 vgca0 0.00 0.00 1.00 5.00 8.00 187.00 32.50 0.00 0.50 0.50 0.30 vgca0 0.00 0.00 7.00 1815.00 104.00 98762.00 54.26 1.31 0.25 0.25 45.50 vgca0 0.00 0.00 5.00 2.00 136.00 178.00 44.86 0.00 0.86 0.86 0.60
Step2: 确定MySQL write IO 来源
由于目前只知道是MySQL数据刷写导致,那么究竟是redo-log还是data page flush造成的现在还不知道。
innodb内部关于write的statistics还是比较有限的。因此比较粗暴的写了个类似于top的perl脚本 ,监控这些参数。
脚本如下,有兴趣的同学可以展开阅读
use strict; use warnings; use utf8; use DBI; my $CONFIG_SERVER_IP ='127.0.0.1'; my $CONFIG_SERVER_DB='test'; my $CONFIG_SERVER_PORT='3306'; my $CONFIG_SERVER_USER='user'; my $CONFIG_SERVER_PASS='password'; my $conf_dbh = DBI->connect("DBI:mysql:$CONFIG_SERVER_DB;host=$CONFIG_SERVER_IP;port=$CONFIG_SERVER_PORT", $CONFIG_SERVER_USER, $CONFIG_SERVER_PASS,{RaiseError => 1}) || die "Could not connect to database: $DBI::errstr"; my %last_value_hash; print "data_write\tdata_written\tdblwr_pages_written\tdblwr_writes\tlog_write_req\tos_log_fsync\tos_log_written\tpages_written\n"; while(1){ my $conf_sth = $conf_dbh->prepare("show global status like '%innodb%'") || die "Prepare error"; $conf_sth->execute(); while(my $row=$conf_sth->fetchrow_hashref){ my $name=$row->{Variable_name}; my $value=$row->{Value}; if( $name eq 'Innodb_data_writes' || $name eq 'Innodb_data_written' || $name eq 'Innodb_dblwr_pages_written' || $name eq 'Innodb_dblwr_writes' || $name eq 'Innodb_log_write_requests' || $name eq 'Innodb_os_log_fsyncs' || $name eq 'Innodb_os_log_written' || $name eq 'Innodb_pages_written'){ $last_value_hash{$name}=0 if( !defined($last_value_hash{$name}) ); my $value_step=$value-$last_value_hash{$name}; $last_value_hash{$name}=$value; print "$value_step\t"; } } print "\n"; sleep 1; }innodb write monitor
最后得到参数的波动情况如下:
可以看到 innodb_data_writes / innodb_data_written / innodb_dblwr_pages_written / innodb_pages_written 都有和IO_UTIL一样有10秒一次的波动。
再结合上iostat中 wsec/s 较大的数值,基本可以确定IO高负载的元凶是data page的flush,而不是redo log的flush
data_write data_written dblwr_pages_written dblwr_writes log_write_req os_log_fsync os_log_written pages_written 1 79360 0 0 169 1 79360 0 1 72192 0 0 127 1 72192 0 1 67072 0 0 139 1 67072 0 1 69120 0 0 149 1 69120 0 1 74752 0 0 128 1 74752 0 1 61952 0 0 134 1 61952 0 1 71168 0 0 131 1 71168 0 1 62976 0 0 126 1 62976 0 1 71168 0 0 109 1 71168 0 1388 44870144 1367 14 125 6 75776 1367 1 66048 0 0 158 1 66048 0 1 73728 0 0 144 1 73728 0 1 69632 0 0 126 1 69632 0 1 75776 0 0 172 1 75776 0 1 88576 0 0 151 1 88576 0 1 67584 0 0 134 1 67584 0 1 80384 0 0 155 1 80384 0 1 86528 0 0 191 1 86528 0 1 72704 0 0 135 1 72704 0 1525 49385984 1504 13 154 5 102400 1504 1 74752 0 0 158 1 74752 0
Step3 : Innodb 什么时候做dirty data page的flush
由于之前对于innodb的数据刷写也只是略知一二,网上对于刷写策略也是众说纷纭,诊断到了这里貌似就无法深入了。
其实真相就静静的躺在那里:源代码阅读。
Innodb写磁盘的代码路径非常清晰,比较容易阅读。主要代码在 storage/innodb_plugin/Buf/Buf0flu.c 中
代码比较冗长这里就不贴了,主要叙述下大致的调用关系。
buf_flush_batch 调用 buf_flush_try_neighbors (尝试刷写neighbor page)
buf_flush_try_neighbots 调用 buf_flush_page (刷写单个page)
buf_flush_page调用buf_flush_write_block_low (实际刷写单个page)
buf_flush_write_block_low调用buf_flush_post_to_doublewrite_buf (将page放到double write buffer中,并准备刷写)
buf_flush_post_to_doublewrite_buf 调用 fil_io ( 文件IO的封装)
fil_io 调用 os_aio (aio相关操作)
os_aio 调用 os_file_write (实际写文件操作)
其中buf_flush_batch 只有两种刷写方式: BUF_FLUSH_LIST 和 BUF_FLUSH_LRU 两种方式的方式和触发时机简介如下:
BUF_FLUSH_LIST: innodb master线程中 1_second / 10 second 循环中都会调用。触发条件较多(下文会分析)
BUF_FLUSH_LRU: 当Buffer Pool无空闲page且old list中没有足够的clean page时,调用。刷写脏页后可以空出一定的free page,供BP使用。
从触发频率可以看到 10 second 循环中对于 buf_flush_batch( BUF_FLUSH_LIST ) 的调用是10秒一次IO高负载的元凶所在。
我们再来看10秒循环中flush的逻辑:
通过参数判断过去一个循环的IO是否空闲,如果空闲则buf_flush_batch( BUF_FLUSH_LIST,PCT_IO(100) );
如果脏页比例超过70,则 buf_flush_batch( BUF_FLUSH_LIST,PCT_IO(100) );
否则 buf_flush_batch( BUF_FLUSH_LIST,PCT_IO(10) );
可以看到由于SSD对于随机写的请求响应速度非常快,导致IO几乎没有堆积。也就让innodb误认为IO空闲,并决定全力刷写。
其中PCT_IO(N) = innodb_io_capacity *N% ,单位是页。因此也就意味着每10秒,innodb都至少刷10000个page或者刷完当前所有脏页。
Step4: 进一步分析找到解决方案
在多次调整 innodb_adaptive_flushing 和 innodb_adaptive_flushing_method 后发现现象没有任何变化。
这一点也比较容易解释:因为大批量刷写的原因是在于10秒循环中,innodb认为IO比较空闲,所以根据innodb_io_capacity 全力刷写;而adaptive只发生在1秒循环中。
所以,调整adaptive相关参数实际上不解决问题。
从Step3中的分析可以得出一个比较明显的结论,减小innodb_io_capacity 后就能很大程度上解决问题。
当我们把innodb_io_capacity从10000调整到200后,并且添加以下配置后:
innodb_adaptive_flush=OFF;
innodb_adaptive_checkpoint=keep_average
可以看到mysql的data written写入量大量减少,且保持稳定(见下图,7:31后是参数调整后的结果)
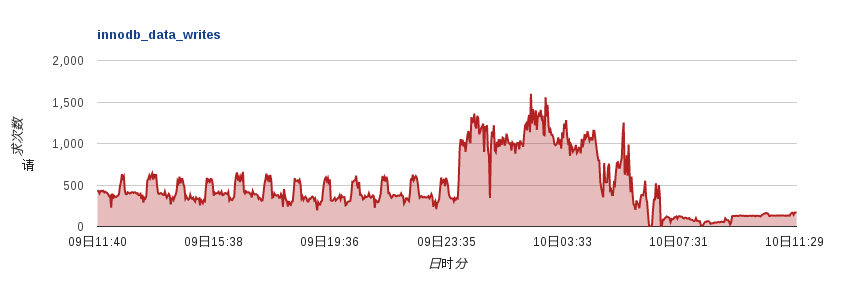
同时从flashcard的硬件写入量来看,也大量的减少(见下图)
参考资料:
http://www.mysqlperformanceblog.com/2011/03/31/innodb-flushing-a-lot-of-memory-and-slow-disk/
https://www.google.com/reader/view/#stream/feed%2Fhttp%3A%2F%2Fwww.xaprb.com%2Fblog%2Ffeed%2F
http://www.mysqlperformanceblog.com/2012/09/10/adaptive-flushing-in-mysql-5-6-cont/
http://dimitrik.free.fr/blog/archives/04-01-2012_04-30-2012.html#143
https://www.google.com/reader/view/#stream/feed%2Fhttp%3A%2F%2Fplanet.mysql.com%2Frss20.xml