1. Java�������
��������
��Java���������������ij���������ԣ� ����һЩ������(primitive)�ı������⣬һ�ж��Ƕ��� �����Ƕ������ϣ� ÿ���������Լ��Ŀռ䣬 ����ÿ��������һ�����ͣ� ͬһ�����ж����ܽ�����ͬ����Ϣ�� ����ֻ��Java�ж���Ľṹ����˵����
? �ࣨ
class��: class�Ƕ������
�ؼ����� ���а���������� ������ �ڲ��࣬ �ڲ�
�ӿ��ȡ���class�����������ʵ���� ��һ�������� ���һ����ij�Ա�������static�ģ��������Ա��ר�����κζ��� ������������࣬ ���еĶ����������Ա��
? ������(abstract class): �������ֱ������һ��ʵ���� �������б����з�����abstract�ģ����������˼������ʵ����һ���ֵķ����� ������Ϊabstract�ķ�������Ҫ������������ȥʵ�֡�
? �ӿ�(interface): �ӿڿ���
����Ϊ��������࣬ ����ÿ����������δʵ�ֵģ� �������г�Ա������ ��������static�ġ� һ�������������ӿڼ̳У�implements����������ʵ������ӿڵ����з�����
�̳����ùؼ��֣�extends���̳нӿ��ùؼ��֣�implements�� һ����ֻ�ܴ�һ����̳������� �����ԴӶ���ӿڼ̳У�������C++�Ķ��ؼ̳У��� ������Ը��Ǹ���ķ���(method)�� �����ܸ��Ǹ���ij�Ա����(field)�� �������ķ���Ϊfinal��static�����ܱ����ǡ����
��ʼ��˳���ǣ� ����и��࣬ ���ȳ�ʼ�������field��Ȼ��ִ�и����
���캯���� �������û����ʽ��ȥ������Ĺ��캯����ȱʡ�Ļ�ȥ��������������캯���� Ȼ���������field�빹�캯���ij�ʼ����
public interface SuperInterface {
public staitc String SOME_FLAG = ��1��;
public void someMethod();
}
public Class SuperClass {
{ System.out.println(��init SuperClass field��);}
public SuperClass() {System.out.println(��init SuperClass Constructor��); }
public void runMethod() { System.out.println(��run SuperClass runMethod()��); }
}
public Class SubClass extends SuperClass implements SuperInterface {
{ System.out.println(��init SubClass field��); }
public SubClass() {System.out.println(��init SubClass Constructor��); }
public void someMethod() {System.out.println(��run SubClass someMethod()��); }
public void runMethod() {System.out.println(��run SubClass runMethod()��); }
}
������test���룺
public class Test {
public void main(String[] args) {
SubClass sub = new SubClass();
sub. runMethod();
}
}
��������
init SuperClass field
init SuperClass Constructor
init SubClass field
init SubClass Constructor
run SubClass runMethod()
�����½����������ij��õ�Java API����һЩJava�Դ���һЩClass��Interface���÷���
2��System
System��λ��package java.lang���棬 ���Ǵ�package����������ǿ���ֱ������������import������ ��Ϊ
JVMȱʡ��load�������������class��
System������һЩ���dz��õķ������Ա������ System���ܱ�ʵ������ ���еķ���������ֱ�����á� ��Ҫ���ô����У�
? �����������
(PrintStream) System.out �����ն����������
(PrintStream) System.err����
�������������
(InputStream) System.in��������������
���ǻ������ض�����Щ���� ���罫���е�System.out�����ȫ���ض�����һ�ļ���ȥ��
System.setOut(PrintStream) ������ض���
System.setErr(PrintStream) ����������ض���
System.setIn(InputStream) �������ض���
? ȡ��ǰʱ�䣺
System.currentTimeMillis() ��ȡ����ʱ���Ǵ�1970/01/01����1/1000������long��ֵ�����ֵ����ת����Date��Timestampֵ�� ��һ�㻹���������������ִ�е�ʱ�䡣����
long beginTime = System. currentTimeMillis();
��
��
System.out.println(��run time = �� + (System. currentTimeMillis() �C beginTime));
? ���鿽����
System.arraycopy(Object src, int src_position, Object dst, int dst_position, int length)
src�� Դ���顣
src_position�� Դ���鿽������ʼλ�á�
dst�� Ŀ������
dst_position�� ������Ŀ���������ʼλ��
length�� ����Ԫ�صij���
����System.arraycopy��������Ŀ���Ч������ߵģ� һ������������Լ�����ֱ���õ��������������
���������ڲ��ж�����ʹ�������������
����
int[] array1 = {1, 2, 3, 4, 5};
int[] array2 = {4, 5, 6, 7, 8};
int array3 = new int[8];
System.arraycopy(array1, 0, array3, 0, 5);
System.arraycopy(array2, 2, array3, 5, 3);
��ʱarray3 = {1, 2, 3, 4, 5, 6, 7, 8}
�����for
ѭ�������и�ֵЧ��Ҫ�ߡ�
? ��ȡϵͳ��Properties��
System.getProperties()��ȡ�õ�ǰ���е�Properties�� Properties���ں���ļ���һ�ڽ�����ϸ��������
System.setProperties(Properties props)������ϵͳ��Properties��
System.getProperty(String key)�� ����һ����ֵ��ȡ��һ��Property��
System.setProperty(String key, String value)�� ����ϵͳ��һ��Property��
JVM��ʱ����һЩȱʡ��Propertiesֵ�� ���磺
java.version Java�����
�汾
java.home Java��Ŀ¼ installation directory
java.class.path Java ��class path
java.ext.dirs Java����չĿ¼·��
file.separator �ļ��ָ���("/" on UNIX)
path.separator ·���ָ���(":" on UNIX)
line.separator �зָ��� ("\n" on UNIX)
user.name �û���
user.home �û���Ŀ¼
user.dir �û���ǰ����Ŀ¼
����ϸ����Ϣ�����Java API�� ��������һ��java�����ʱ�����ͨ��-D������ϵͳ��Property�� ���� java �CDejb.file=ejb_Test PrintTest ��PrintTest����Ϳ���ͨ��System.getProperty(��ejb.file��)��ȡ��ֵejb_Test��
? ����
System. loadLibrary(String libname)�� ����native�Ķ�̬�⡣ ������CдJNI�Ŀ⣬ Ȼ����java��ͨ��native���������á�
System.setSecurityManager(SecurityManager s)
System.getSecurityManager()�� ������ȡ��ϵͳ��security class��
3��String, StringBuffer
3.1 �����÷�
String����˵��������õ�һ���࣬ ������������һЩ�����÷��Ǻ����õġ�
String����һ���ַ���ɵ��ַ����� �±���0��ʼ�� һ���б�Ҫ�ı�ԭ�������ݣ� ÿ��String�������з�����һ���µ�String����
? char charAt(int index) ����ָ��λ�õ��ַ���
? int compareTo(Object o)
int compareTo(String anotherString)
������һ��������бȽϡ�
? int compareToIgnoreCase(String str) ����һ��String���бȽϣ� �����ִ�Сд
? String concat(String str) �������ַ����� ����ֱ����+�� ��ΪJava��String������+
? static String copyValueOf(char[] data)
static String copyValueOf(char[] data, int offset, int count)
��data����ת����String
? boolean endsWith(String suffix) ���Դ�String�Ƿ���suffix��β��
boolean startsWith(String prefix) ���Դ�String�Ƿ���prefix��ͷ��
? boolean equals(Object anObject)
boolean equalsIgnoreCase(String anotherString)
�Ƚ����ַ�����ֵ�� �������false
? byte[] getBytes() ����ȱʡ���ַ�
������
Stringת�����ֽ����顣
byte[] getBytes(String enc) ����ָ���ı��뽫Stringת�����ֽ����顣
? void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) �����ַ���һ������
? int indexOf(int ch) ���ִ�����ʼλ�ò����ַ�ch��һ�γ��ֵ�λ��
int indexOf(int ch, int fromIndex) ��ָ����fromIndexλ�������ҵ�һ�γ���ch��λ�ã�
int indexOf(String str)
int indexOf(String str, int fromIndex)
���������ch��str������-1
? int lastIndexOf(int ch) ���ִ�������λ����ǰ���ҵ�һ�γ���ch��λ��
int lastIndexOf(int ch, int fromIndex) ��ָ����λ����ǰ���ҵ�һ�γ���ch��λ�ã�
int lastIndexOf(String str)
int lastIndexOf(String str, int fromIndex)
�����������-1
? int length() ���ַ������ַ����ȣ�һ��ȫ�ǵĺ��ֳ���Ϊ1��
? String replace(char oldChar, char newChar) ���ַ�oldCharȫ���滻ΪnewChar�� ����һ���µ��ַ�����
? String substring(int beginIndex) ���ش�beginIndex��ʼ���ַ����Ӽ�
String substring(int beginIndex, int endIndex) ���ش�beginIndex��endIndex�������ַ������Ӽ��� ����endIndex �C beginIndex�����Ӽ����ַ�������
? char[] toCharArray() ���ظ��ַ������ڲ��ַ�����
? String toLowerCase() ת����Сд��ĸ���ַ���
String toLowerCase(Locale locale)
String toUpperCase() ת������д��ĸ���ַ���
String toUpperCase(Locale locale)
? String toString() ������Object��toString������ ���ر�����
? String trim() ���ַ������ߵİ�ǿհ��ַ�ȥ���� �����Ҫȥ��ȫ�ǵĿհ��ַ���Ҫ�Լ�д��
? static String valueOf(primitive p) �������ļ����͵�ֵת��Ϊһ��String
StingBuffer��һ���ɱ���ַ����������Ա����ġ�ͬʱStringBuffer��Thread safe�ģ� ����Է��ĵ�ʹ�ã� ���õķ������£�
? StringBuffer append(param) ��StringBuffer����֮����param(����Ϊ���еļ����ͺ�Object) �����Ӻ��StringBuffer�� ��ԭ���Ķ�����ͬһ�ݡ�
? char charAt(int index) ����ָ��λ��index���ַ���
? StringBuffer delete(int start, int end) ɾ��ָ������start~end���ַ���
? StringBuffer deleteCharAt(int index) ɾ��ָ��λ��index���ַ���
? void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) ͬString��getChars����
? StringBuffer insert(int offset, boolean b) ��ָ��λ��offset����param(Ϊ���еļ�������Object)
? int length() ͬString��length()
? StringBuffer replace(int start, int end, String str) ��ָ������start~end���ַ����滻Ϊstr
? StringBuffer reverse() ��ת�ַ���˳��
? void setCharAt(int index, char ch) �����ַ�ch��indexλ�á�
? String substring(int start)
? String substring(int start, int end) ͬString��subString
? String toString() ����һ��String
��ҿ����Ѿ�ע��ܶ����������һ��StringBuffer���� �����ص����������String�ķ������ص�String��һ���� ���ص�StringBuffer�����뱻������StringBuffer������ͬһ�ݣ� ��String�ķ������ص�String��϶����������ɵ�һ��String��
3.2���ܶԱ�
��ΪString����Ƴ�һ�ְ�ȫ���ַ����� ������C/C++�е�
������������ڲ�������ʱ���Ƶ���Ľ��ж���Ľ����� �������Ч�ʲ���StringBuffer�� �����ҪƵ���Ľ����ַ�������ɾ�����Ļ������StringBuffer�� ����ƴSQL�ģ� д������ ���� ��������String��+����������һ�����Ż���
x = "a" + 4 + "c"
�ᱻ�����
x = new StringBuffer().append("a").append(4).append("c").toString()
����
x = ��a��;
x = x + 4;
x = x + ��c��;
�ᱻ�Ż��� ���Կ��������һ��
����ʽ�������String�Ķ��+�����ᱻ�Ż��� ���������ʽ��+�������ᱻ�Ż���
3.3����
1. ��
Servlet2.3��
JSP1.1��ǰ����post����̨��������ͨ��ISO88591��ʽ���б���ģ� ������ȫ�������ֵ�ʱ��, �ں�̨request�õ������ݿ��ܾ�������, ���ʱ��͵��Լ����б���ת��, ͨ��String.getBytes(String enc)�����õ�һ���ֽ���, Ȼ��ͨ��String(byte[] bytes, String enc)������캯���õ�һ�����µı������ɵ��ַ���. ���罫ISO88591���ַ���ת����Shift_JIS���ַ���, ��������:
public static String convertString(String str) {
if (str == null) { return null; }
try {
byte[] buf = str.getBytes("ISO8859_1");
return new String(buf, "Shift_JIS");
} catch (Exception ex) {ex.printStackTrace();return null; }
}
���������µ�Servlet2.3��Jsp1.2�п���ͨ��request.setCharacterEncoding����������ȡֵ������, ����Ҫ�Լ�����ת����
2����ΪJava�ڼ���String�ij��������ַ�Ϊ��λ�ģ� ���һ��ȫ�����ǵ��ַ�������һ���ģ� ����DB�������Ǹ����ֽ������㳤�ȵģ� �����������Check��ʱ���Ҫ�ж�String���ֽڳ��� ���������µķ�����
public static String length(String str) {
if (str == null) { return 0; }
return str.getBytes().length;
}
4����ֵ���ַ�����������������͵IJ���
�Ķ��ձ����£�
Object Primitive ��Χ
Number Long long -9223372036854775808 to 9223372036854775807
Integer int -2147483648 to 2147483647
Short short -32768 to 32767
Byte byte -128 to 127
Double double
Float float
Character char '\u0000' to '\uffff'
Boolean boolean false and true
��C���������Բ�ͬ������ֵ�ķ�Χ����ƽ̨�ĸı���ı䣬 ��ͱ�֤��ƽ̨֮���ͳһ�ԣ�����˿���ֲ�ԡ�
Number: Number�����Ǹ������࣬ ����ֱ��ʹ�ã� ����ֱ�Ӵ�Number�̳���������������¼��ַ�����
? byte byteValue() �����ֽ�ֵ
? double doubleValue() ����doubleֵ
? float floatValue() ����floatֵ
? int intValue() ����floatֵ
? long longValue() ����longֵ
? short shortValue() ����shortֵ
����Ҫͨ��Object��ȡ�ü��������͵�ֵ��ʱ��͵��õ����ϵķ����� �����Ҳ��Ƽ���ͬ����֮���ȡֵ�� ����Long�͵�Object��Ҫֱ��ȥ����intValue()�����ȿ��ܻᶪʧ��
�����ͨ��String���õ�һ����
ֵ�����ļ�����ֵ�� һ����ÿ��Number�������涼��һ��parseXXX(String)��
��̬������ ���£�
? byte Byte.parseByte(String s)
? double Double.parseDouble(String s)
? float Float.parseFloat(String s)
? int Integer.parseInt(String s)
? long Long.parseLong(String s)
? short Short.parseShort(String s)
�����ֱ�Ӵ�String�õ�һ��Number�͵�Object����ÿ��Number�����涼��valueOf(String s) �����̬�������磺
? Byte Byte.valueOf(String s)
? Double Double.valueOf(String s)
? Float Float.valueOf(String s)
? Integer
Integer.valueOf(String s)
? Long Long.valueOf(String s)
? Short Short.valueOf(String s)
һ����ڹ���һ��Number��ʱ����ͨ��һ��String����ɣ� ���磺
Long longObject = new Long(��1234567890��);
�ȼ���
Long longObject = Long.valueOf(��1234567890��);
��Ϊÿ��Number�����ʵ����Object��toString()������ ���ԣ� �����õ�һ��String�͵���ֵ�� ֱ�ӵ���XXX.toString()�Ϳ����ˡ� �����õ�һ�������͵�String�� �����ܶ��ܽ����£�
? �������ɶ�Ӧ��Number Object���ͣ� Ȼ�����toString()
? ����Number���� .toString(type t) ����t���Ǽ����͵����ݡ�
? ����String.valueOf(type t) ���Ƽ�ʹ�����ַ�����
��ҿ��Կ����� ����һ�ֽ�������ö��ַ���ʵ�֣� �ܵ�ԭ���������������ȡ�������һ��String�õ�һ�������͵�ֵ�������������ַ�����
Integer.parseInt(��12345��);
��
(new Integer(s)).intValue(��12345��);
��ȻӦ��ʹ�õ�һ�ַ�����
Character: Character��Ӧ��char���ͣ� Character�������кܶྲ̬�ķ�������char�����жϲ����� ��ϸ�IJ��������JDK API�� Java���ַ����жϲ�������������Unicode���еģ� ����Character.isDigit(char ch)��������� �����ǵ�0-9����Ҫ�� ȫ�ǵ�����0-9Ҳ�Ƿ���Ҫ��ġ�
Boolean: Boolean��Ӧ��boolean���ͣ� booleanֻ��true��false����ֵ�� ������������ֵ���ͻ����� ����ͨ���ַ�����true���Լ���false�����õ�Object��Boolean�� Ҳ����ͨ�������͵�boolean�õ�Boolean�� ���÷������£�
? Boolean(boolean value) ͨ�������͵�boolean����Boolean
? Boolean(String s) ͨ��String(��true��, ��false��)����Boolean
? boolean booleanValue() ��Object��Boolean�õ������͵�booleanֵ
? boolean equals(Object obj) ������Object��.equals������ Objectֵ�Ƚ�
? static Boolean valueOf(String s) �����빹�캯��Boolean(String s)һ��
5��Class, ClassLoader
Java��һ�ֽ��ڽ��������֮������ԣ� Java�������ȱ�����ֽ��룬 �����е�ʱ���ٷ���ɻ����롣 ���������е�ʱ�����ǾͿ���ͨ��Java�ṩ�ķ��䷽��(reflect)���õ�һ��Object��Class�Ķ�����Ϣ�� ����Ժܴ��Լܶ������
Class: �κ�һ��Object����ͨ��getClass()��������õ����������ڼ��Class�� �õ����Class֮�����������Ͷ��ˣ� ���綯̬�õ����Ĺ��캯���� ��Ա������ �����ȵȡ� ������������һ���µ�ʵ���� ����ֻ�����������dz��õķ����� ����ϸ���÷�����Java API
? Class Class.forName(String className) throws ClassNotFoundException�� ���Ǹ���̬������ ͨ��һ��Class��ȫ�����õ����Class��
? String getName() ȡ�����Class��ȫ�ƣ� ����package����
? Object newInstance() �õ�һ��ʵ���� ����ȱʡ�Ĺ��캯����
����������һ���ࣺ com.some.util.MyClass ����õ�����һ��ʵ���أ� �������������ַ�����
MyClass myClass = new MyClass()�� ֱ��ͨ��
caozuofu.html" target="_blank">������new���ɣ�
���ߣ�
MyClass myClass = (MyClass) Class.forName(��com.some.util.MyClass��).newInstance();
Ҳ�����˾ͻỳ�ɵڶ��ַ���ʵ��
������ �ܹ�ֱ��new�����������䡣 ��ʵ���������ô�ȴ�ܴ� �ٸ�
������ �ù�
struts���˶�֪���� ��action-config.xml���ж�����һϵ�е�formBean��actionBean�� ��Ȼÿ��form��action������ͬ���ͣ� ������һ��request������ʱ���ҿ��Զ�̬������һ��form��action��ʵ�����о���IJ����� ���ڱ����ʱ���Ҳ���֪�������Ǻ��ֵ�form��action�� ��ֻ�������Ǹ���ķ����� �����Ҫ�õ�һ�ַ����Ļ��� ����ڱ����ʱ��ͨ��һ����־���ж�ÿһ��request��Ҫ�������ɵ�form��action�� ���������Դ�͡� �ܵ���˵������ӿڵı�̵��о���ʹ�����ַ����� ���粻ͬ���ݿ⳧�ҵ�JDBC Driver���Ǵӱ���JDBC�ӿڼ̳���ȥ�ģ� ������д�����ʱ���ò��Ź������Ǻ��ֵ�Driver�� ֻ�������е�ʱ��ȷ���� ����
XML��ParserҲ�ǣ� ����ʹ�õ�ֻ�DZ��Ľӿڣ� �����˭��ʵ�����ģ� �����ò���ȥ�ܡ�
ClassLoader: ClassLoader��һ�������࣬һ���ϵͳ��һ��ȱʡ��ClassLoader����װ��Class�� ��ClassLoader.getSystemClassLoader()���Եõ���������ʱ��Ϊ�˰�ȫ����������������Ҫ���ǿ���
�Զ����Լ���ClassLoader������loaderһЩ������Ҫ��Class�� �����еIJ�Ʒ�������Լ���ClassLoader����ָ��Classֻ����ָ�����ض���JAR�ļ�������loader���������ͨ������ClassPath�����������������Class���в�ͨ�ġ� ����Ȥ�Ŀ��Բ���Java API �ĸ���ϸ���÷�˵
6. Java IOϵͳ
JDK1.0������
InputStream
ByteArrayInputStream
FileInputStream
FilterInputStream
ObjectInputStream
PipedInputStream
SequenceInputStream
BufferedInputStream
DataInputStream
PushbackInputStream
LineNumberInputStream
JDK1.1������
Reader
BufferedReader
FilterReader
PipedReader
StringReader
InputStreamReader
CharArrayReader
FileReader
PushbackReader
LineNumberReader
JDK1.0�����
OutputStream
BufferedOutputStream
DataOutputStream
PrintStream
ByteArrayOutputStream
FileOutputStream
FilterOutputStream
ObjectOutputStream
PipedOutputStream
JDK1.1�����
Writer
BufferedWriter
FilterWriter
PipedWriter
StringWriter
FileWriter
PrintWriter
OutputStreamWriter
CharArrayWriter
�����ոսӴ�Java��IO���֣� ����ܻ�о������֣� ȷʵJava�ṩ�˹�����࣬�������˸е����ҡ�
�ɽ�Java���IO���Ϊ����������������֣� ��1.0�汾���ṩ������������࣬ ������������InputStream�̳У� ������������OutputStream�̳У� 1.1�ṩ�������µĻ��࣬ ���������Reader�������Writer�� �����Dz����������滻ԭ���ϵ�InputStream��OutputStream�� ������Ҫ����Java�ܸ��õ�֧�ֹ��ʻ������� ԭ���ϵ�IO����ֻ֧��8λ�ֽ����� ���ܺܺõؿ���16λUnicode�ַ��� Java�ں���char��16λ��Unicode�� ����������Reader��Writer������ṩ������IO�����е�Unicode��֧�֡� ����֮���¿�Ҳ���ٶȽ������Ż��� �ɱȾɿ��������С�
InputStream�����ͣ�
1�� �ֽ�����
2�� String����
3�� �ļ�
4�� �ܵ��� ���Դ�����һ��������õ�һ��������
5�� һϵ�е��������� ���Խ���Щ��ͳһ�ռ���������һ�����ڡ�
6�� ������Դ����
socket���ȣ�
����һ����File�࣬ Java��һ��Ŀ¼Ҳ��һ���ļ���������file.isFile()��file.isDirectory()�������ж����ļ�����Ŀ¼�� File ���������Ϊ����ת��Ϊ�ļ������в����� �����������Java IO API��
���÷�����
/**
* ƴ
�ļ���, ��windows(\)��unix(/)�ϵ��ļ��ָ���Dz�һ����
* ����ͨ��File��ľ�̬��Ա����separatorȡ��
*/
public static String concatFileName(String dir, String fileName) {
String fullFileName = "";
if (dir.endsWith(File.separator)) {fullFileName = dir + fileName;
} else {fullFileName = dir + File.separator + fileName;}
return fullFileName; }
/**
* �ӿ���̨��ȡ���������, System.in (InputStream) ��ת����InputStreamReader����
* BufferedReader���ж�ȡ.
*
*/
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
String str = "";
while (str != null) {str = in.readLine();// process(str); }
/**
* ���ļ��а��н��ж�ȡ
���ݴ���
*/
BufferedReader in = new BufferedReader(new FileReader("infilename"));
String str;
while ((str = in.readLine()) != null) {// process(str); }
in.close();
/**
* д������һ���µ��ļ���ȥ.
*/
BufferedWriter out = new BufferedWriter(new FileWriter("outfilename"));
out.write("a String");
out.close();
/**
* ���µ����ݵ�һ���ļ���ȥ, ���ԭ�ļ�������
* ���½�����ļ�.
*/
BufferedWriter out = new BufferedWriter(new FileWriter("filename", true));
out.write("aString");
out.close();
/**
* ��һ����
���л���Java��object������ʽд��һ���ļ���ȥ��.
*/
ObjectOutput out = new ObjectOutputStream(new FileOutputStream("filename.ser"));
out.writeObject(object);
out.close();
/**
* ���ļ��лָ����л�����Java Object
*/
ObjectInputStream in = new ObjectInputStream(new FileInputStream("filename.ser"));
Object object = (Object) in.readObject();
in.close();
/**
* ��ָ���ı��뷽ʽ���ļ��ж�ȡ����
*/
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream("infilename"), "UTF8"));
String str = in.readLine();
/**
* ��ָ���ı��뷽ʽд���ݵ��ļ���
*/
Writer out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream("outfilename"), "UTF8"));
out.write("a String");
out.close();
����������ӿ��Կ����� ��֮����Ի���ת���� �������������ַ�������ý�֮ת����BufferedReader��BufferedWriter����������߶�д��Ч�ʡ�
��Ҫע�����һ����˵���Ĵ�С�ǵò����ģ� ��Ȼһ���InputStream����һ��available()�ķ������Է�����������Զ������ֽ����� �������������ʱ���ȷ�� �����ڶ�ȡ���紫�������ʱ�� ȡ���ij��Ȳ���һ������ʵ��Ч�ij��ȡ�
�����д�����ʱ������Ѿ�ע�һЩ��̳���java.io.Serializable����ӿڣ� ��ʵ�̳�������ӿ�֮�������ı����������κ����飬 ֻ���������Ա����л���ͨ���������д��䣬 ���ɱ���ԭ��ԭObject�� ���������ͨ�����紫�䣨EJB �н��д��ݲ����ͷ���ֵ��Data Class���� Ҳ���Ա��浽�ļ���ȥ��ObjectOutputStream����
7. Java������
��д�����ʱ����ÿ��ֻʹ��һ������ ������Ƕ�һ�������в����� ����Ҫ֪����������Щ���� �����ڱ����ʱ��������ʱ����֪�������ж��ٶ���������Ҫ���ж�̬�ķ����š�
Java�ļ�����ֻ�����ɶ������� ���ڼ����͵����ݴ�ţ� ֻ��ͨ����������ţ� ������Դ�ż����͵�����Ҳ�ܴ�Ŷ���
Java�ṩ���������͵ļ����ࣺ Vector(ʸ��)�� BitSet(λ��)�� Stack(
��ջ)�� Hashtable(ɢ�б�)��
1. ʸ���� һ�������Ԫ�أ� ����ͨ��index���з��ʡ�
2. λ���� ��ʵ������
������λ���ɵ�Vector�� ���������������-�ء���Ϣ�� ����ռ�Ŀռ�Ƚ�С�� ����Ч�ʲ��Ǻܸߣ� ������Ч�ʷ��ʣ� �������ù̶����ȵ����顣
3. ��ջ�� ��������LIFO�����ϣ� java.util.Stack����ʵ���Ǵ�Vector�̳������ģ� ʵ����pop, push������
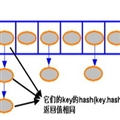
4. ɢ�б��� ��һ���顰��--ֵ����ɣ� ����ļ�������Object���͡� ͨ��Object��
hashCode���и�Ч�ʵķ��ʡ�
������Щ����֮��Ĺ�����ϵ����ͼ�� ���б�ɫ�IJ���Ϊ���dz��õ��ࡣ
����ͼ���Կ����� �����ӿ���������
Collection�� ���е�ʸ������������̳���ȥ�ģ� ������ֱ�Ӵ����̳���ȥ�ġ� List��Set�������ӿ�ֱ�Ӽ̳���Collection��
������������List������Ա�����ͬ�Ķ������� ��Set�����ֵ�Dz��ظ��ġ� ���Ǿ����õ�Vector��ArrayList���Ǵ�List�̳���ȥ�ģ� ��HashSet�Ǵ�Set�̳еġ�
Map��ɢ�б��Ľӿڣ� Hashtable��HashMap�̳�������ӿڡ�
����������ü�����ij��÷�����
/**
* Vector �� ArrayList�IJ���������һ����
* ���õ���Ԫ����add(), ɾ��Ԫ����remove()
* ȡԪ����get(), ����������ѭ����get()ȡ. ����
* �ȵõ�һ��Iterator, Ȼ��ͨ������Iterator�ķ���
* ����Vector��ArrayList
*/
// ����һ���յ�Vector
Vector vector = new Vector();
// �������һ��Ԫ�ء�
vector.add("one");
vector.add("two");
// ��ָ���ĵط�����һ��ֵ
vector.set(0, "new one");
// ����һ��Ԫ�ػ�����ָ��λ�õ�Ԫ��
vector.remove(0);
// ��forѭ���������Vector
for (int i = 0; i < vector.size(); i++) {
String element = (String) vector.get(i); }
// ��
ö����(Enumeration)������(ֻ��Vector�У�ArrayListû��)
Enumeration enu = vector.elements();
while (enu.hasMoreElements()) {
enu.nextElement();}
// �÷�����(Iterator)������
Iterator it = vector.iterator();
while (it.hasNext()) {it.next();}
/**
* Hashtable��HashMap�IJ���, ��Ԫ����put(����add)
* ɾ��Ԫ����remove, ����������Iterator �ȿ��Ա���
* ����key, Ҳ������value
*/
// ����һ���յ�Hashtable��HashMap
Hashtable hashtable = new Hashtable();
// ��һ��Ԫ��
hashtable.put("one", "one object value");
// ɾ��һ��Ԫ��
hashtable.remove("one");
// ��Iterator����
Iterator keyIt = hashtable.keySet().iterator();
while (keyIt.hasNext()) {
Object keyName = keyIt.next();
String value = (String) hashtable.get(keyName); }
Iterator valueIt = hashtable.values().iterator();
while (valueIt.hasNext()) {
valueIt.next();}
// ��Enumeration����, ֻ��Hashtable��, HashMapû��.
Enumeration enu = hashtable.elements();
while (enu.hasMoreElements()) {
enu.nextElement();}
˵���� Enumeration���ϼ��Ͽ��еĽӿڣ� ��Iterator���¼��ϣ�1.2���г��ֵģ� ��Vector��HashtableҲ�����ϼ����е��࣬ ����ֻ��Vector��Hashtable������Enumeration��
Vector��ArrayList�Աȣ�
��Ȼ��ʹ�õ�ʱ�������������ûʲô���� ���Ƕ��Ǵ�List�̳������ģ� ӵ����ͬ�ķ����� �����ǵ��ڲ�������Щ��ͬ�ģ�
? ����Vector���ڲ���һЩ��������
�߳�ͬ��(synchronized)�� ͬ���Ĵ��۾��ǽ�����ִ��Ч�ʣ� �������
��ȫ������ArrayList�����̲߳�ͬ���ģ� ���Զ��̲߳�����д����
? �ڲ����������ʡ� ���е���Щʸ���������ڲ�������Object��������д洢�Ͳ����ġ� ����Ҳ��������Ϊʲô�����Խ����κ����͵�Object�� ��ȡ������ʱ����Ҫ�����������졣 Vector��ArrayList�����Զ������Ĺ��ܣ� ���Dz��ù���size��� ���Ƕ����������ĺ�����Ԫ�ء� Vector��ArrayList�ڲ��������������Dz�һ���ģ� ���ڲ������鲻�����ɸ���Ԫ�ص�ʱ�� Vector���Զ�������ԭ������С�� ArrayList���Ϊԭһ�����С�� �����������������һ��Ԫ��һ��Ԫ�ص�������
Hashtable��HashMap�Աȣ�
Hashtable��HashMap���Ǵ�Map�̳������ģ� ����������һ���� �����ڲ���������ͬ�㣺
? ��Vector��ArrayListһ���� ����
������ͬ���Dz�ͬ�ģ� Hashtable���ڲ������߳�ͬ���� ��HashMap���̲߳�ͬ���ġ�
? HashMap�ļ���ֵ������Ϊnull�� ��Hashtable�����ԣ� �������ͼ��һ��nullֵ�ŵ�Hashtable����ȥ�� ����һ��NullPointException�ġ�
���ܶԱȣ�
�������õļ��ϲ����� ÿ�ּ��϶�Ӧ����һ�����dz��õļ����࣬ ���ڲ�ͬ�ij�����Ӧ��ʹ��Ч����ߵ�һ���� һ����˵���Ƽ�����ʹ���µļ����࣬ ���Dz����ѣ� ����˵��Ҫ�������ϼ�����д�IJ�Ʒ�ij��� Ҳ����˵����ʹ��ArrayList��HashMap�� ����ʹ��Vector��Hashtable��
? �ڵ��߳���ʹ��ArrayList��HashMap�� ���ڶ��߳��������Ҫ�����߳�ͬ������ʹ��Vector��Hashtable�� ��Ҳ������synchronized��ArrayList��HashMap����ͬ���� ����ͬ�����ArrayList��HashMap�DZ�Vector��Hashtable���ġ� ��������Ϊ��Ҫ�����߳�ͬ���ĵط������ࡣ ���һ�����������ڷ����ڲ�ͬʱֻ������һ���̶߳�֮���в����� �Ͳ���Ҫ����ͬ���� �������������ڲ����Ҳ��Ǿ�̬�ģ� ����
ʵ�������� ������ಢû�б����߳�ʹ��Ҳ�Ͳ���Ҫͬ����
һ���Լ�д�ij�����ٻ��Լ�ȥ�����̵߳ģ� ����
Web������ʱ�� �������Servlet�� ��ÿ��request����һ���̣߳� Ҳ����˵ÿ��Servlet�����ڶ��̻߳��������еģ� ���Servlet��ʹ����
ȫ����̬�ij�Ա�����͵�С�ĵ���� �����Ҫͬ���͵��ڷ����ϼ���synchronized���η��� �����������̲߳������� ������֪��������ʲô��ͻ����Ϳ��Դ�ʹ��ArrayList��HashMap�� ��������ڶ��߳������߳��ڶ�ArrayList��HashMap�����ģ��ṹ�ϵ��ģ��� ����һ���߳�����Iterator���ж�ȡ������ ���ʱ����п��ܻ���ConcurrentModificationException, ��Ϊ��Iterator��ʱ�� ������ԭList�Ľṹ�ı䡣��������get������ȡ��
���ü��ɣ�
1. ��������ӿڵ�
��̼����� ����������Ҫдһ����ͨ��������ʸ������������Vector��ArrayList��HashSet�ȵȽ��в����� ���Ҳ���֪�������û�����崫����ʲô���͵��࣬ ���ʱ�����ǿ���ʹ��Collection�ӿڣ� �Ӷ�ʹ������кܴ������ԡ� ����ʾ�����£�
/**
* ��list���������Ԫ����sep����������
* list����ΪVector, ArrayList, HashSet�ȡ�
*/
public static String join(String sep, Collection list) {
StringBuffer sb = new StringBuffer();
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
sb.append(iterator.next());
if (iterator.hasNext()) { sb.append(sep); }
}
return sb.toString();
}
2. ����Set����Unique�� ������һ����������ж������ظ��ģ��� ������ֻ�Բ�ͬ�Ķ������Ȥ�� ���ʱ�����ʹ��HashSet��������࣬ Ȼ�����ͨ������Object��equals������ѡ���Զ����ж���ȵ�rule�� ȱʡ���ǵ�ַ�жϡ� ����
class DataClass {
private String code = null;
private String name = null;
public void setCode(String code) {this.code = code; }
public String getCode() {return this.code; }
public void setName(String name) {this.name = name; }
public String getName() {return this.name; }
public boolean equals(DataClass otherData) {
if (otherData != null) {
if (this.getCode() != null&& this.getCode().equals(otherData.getCode()) {
return true;
}
}
return false;
}}
DataClass data1 = new DataClass();
DataClass data2 = new DataClass();
data1.setCode("1");
data2.setCode("1");
HashSet singleSet = new HashSet();
singleSet.add(data1);
singleSet.add(data2);
���singleSet����ֻ��data1�� ��Ϊdata2.equals(data1)�� ����data2��û�мӽ�ȥ��
3. ������Ƽ��ϵĴ洢��ʽ�� �Ի�ýϸ�Ч�Ĵ����� �������������Ƕ���ϣ� ������ArrayList������HashMap�� HashMap������Ƕ��HashMap��
8��ResourceBundle, Properties
ResourceBundle������һ����Ŀ�� �����ļ����ٲ��˵ģ� һЩ��Ҫ���ݻ��������ĵIJ����� ���е÷ŵ������ļ���ȥ�� ��Java��һ����ͨ��һ��properties�ļ���ʵ�ֵģ� ����ļ���properties��β�� �ڲ��ṹ�Ƕ�ά�ģ� ��key=value����ʽ���ڡ� ���£�
options.column.name.case=1
options.column.bean.serializable=1
options.column.bean.defaultconstructor=1
options.column.method.setter=1
options.general.user.version=1.0
database.connection[0]=csc/csc@localhost_oci8
database.connection[1]=cscweb/cscweb@localhost_thin
ResourceBundle����
�����������ļ��� ���Ĺ����ǿ��Ը������Locale�����н��������ļ��� ���һ����Ʒ��Ҫ���ж�����֧�֣� �����ڲ�ͬ���ֵ�ϵͳ�ϣ� ����ʾ��������������ʾ��Ӧ�Ľ������ԣ� �Ϳ��Զ����ݵ�properties�ļ��� ÿ���ļ���key��һ���ģ� ֻ��value��һ���� Ȼ����application��ʱ�� �����б𱾻���Locale��������Ӧ��properties�ļ��� Properties�ļ���������ݵ�Ҫ��Unicode�� ��jdk���������native2ascii����������ת���� ���� native2ascii Message.txt Message.properties ������һ��Unicode���ļ���
Properties: Properties�������ʵ���Ǵ�Hashtable�̳������ģ� Ҳ����˵����һ��ɢ�б��� ������������key��value����String�͵ģ� ����Ҳ���˼������õķ�����
? String getProperty(String key) ȡ��һ��property
? String getProperty(String key, String defaultValue) ȡproperty�� �����������defaultValue��
? void list(PrintStream out) ��out������е�properties
? void list(PrintWriter out)
? Enumeration propertyNames() �����е�property key����Enumeration��ʽ���ء�
? Object setProperty(String key, String value) ����һ��property��
ResourceBundle��Propertiesһ��
�������ʹ�á� ���ǵ��÷��ܼ� ��ResourceBundle����������key��valueȻ�������һ����̬��Properties��Ա��������ȥ�� Ȼ��Ϳ���ͨ������Properties�ķ������ж�ȡProperty�� ������������ӣ�
public class PropertyManager implements Serializable {
/** ����һ����̬��Properties���� */
private static Properties properties = new Properties();
/**
* ͨ��һ�������������IJ�������Property�ļ��ij��ڻ�
* ����������һ���ļ���Message.properties�� �������
* ejb/util���沢�ң� ���Ŀ¼�����е�classpath����
* ��in��Ϊejb.util.Message
*
*/
public static void init(String in) throws MissingResourceException {
ResourceBundle bundle = ResourceBundle.getBundle(in);
Enumeration enum = bundle.getKeys();
Object key = null;
Object value = null;
while (enum.hasMoreElements()) {
key = enum.nextElement();
value = bundle.getString(key.toString());
properties.put(key, value);
}}
/**
* ȡ��һ��Propertyֵ
*/
public static String getProperty(String key) {return properties.get(key); }
/**
* ����һ��Propertyֵ
*/
public static void setProperty(String key, String value) {properties.put(key, value); }
}
�������ڵ�Java��Ʒ�У�Խ��Խ��������XML�滻Properties�ļ����������á� XML���þ��в�νṹ������ŵ㡣
9. Exceptions
Throwable
Exception
Error
RuntimeException
ClassNotFoundException
IOException
SQLException
IndexOutOfBoundsException
ClassCastException
NullPointerException
OutOfMemoryError
StackOverflowError
NoClassDefFoundError
Java����Υ��(Exception)�������������д������� Υ�����Ƶ�һ���ô������ܹ�������ƴ��룬 ������Ҳ���ü��һ���ض��Ĵ��� Ȼ���ڳ���Ķദ�ط�������п��ơ� ���⣬ Ҳ����Ҫ�ڷ������õ�ʱ���������Ϊ��֤�����ܹ���������Ĵ��� ����ֻ��Ҫ��һ���ط��������⣺��Υ������ģ�顱���ߡ�Υ������������ ��������Ч���ٴ������� ������Щ����������������Ĵ�����ר�ž�������Ĵ���ָ�����
һ��������Υ�����ӣ�
public void throwTest() throws MyException {
try {
...
} catch (SQLException se) {
cat.error("", se);
throw new MyException(se.getMessage());
} catch (Exception e) {cat.error("", e);
} finally {
...
}
}
���һ�δ����п��ܻ��׳�Υ��������try {} catch {}�������� ��catch����Υ���������׳��� Ҳ����ת��Ϊ�������͵�Exception�׳��� finally������Ĵ����ܻᱻִ�е��ģ� ����ǰ���Ƿ��Ѿ�throw��return�ˡ�
Throwable������Υ���Ļ��࣬ �������ֳ������͡� ���У� Error���������ں�ϵͳ���� ����һ�㲻�����Ⲷ�����ǡ� Exception�ǿ��Դ��κα�Java�������������Ļ������͡�
�������ͼ�� �����Error���������RuntimeException����������Υ����һ���������ԣ� ����˵���ǿ��Ե����Dz����ڣ� ������Υ���׳���ʱ�� ���ǿ��Բ�catch���� Ҳ���Բ��ڷ�����throws���� RuntimeExceptionһ���������һ����̴��� ����ȫ���Ա���ġ�
����ע��㣺 ��Ϊʹ����Exception֮����ҪӰ��һЩЧ�ʵģ� ����Exception�������á�һ��IJ�Ҫ��Exception������ҵ�����̣� ��β�Ҫѭ������ʹ�á�
���ɣ����ǿ��Դ�Exception��ֱ�Ӵ�Throwable�̳�д�����Լ���Exception�� Ȼ�����ҵ����Ҫ�ײ�ͬ�����Exception��
10. JDBC���
���� JDBC������ֹ�ϵ���ݿⷢ�� SQL ������һ���������¡�����֮������ JDBC API���Ͳ���Ϊ���� Sybase ���ݿ�ר��дһ������Ϊ���� Oracle ���ݿ���ר��дһ������Ϊ���� Informix ���ݿ���д��һ�����ȵȡ���ֻ���� JDBC API дһ��������ˣ���������Ӧ���ݿⷢ�� SQL ��䡣���ң�ʹ�� Java
���������д��Ӧ�ó�������ȥ����ҪΪ��ͬ��ƽ̨��д��ͬ��Ӧ�ó��� Java �� JDBC ���������ʹ
����Աֻ��дһ�����Ϳ��������κ�ƽ̨�����С�
����Ϊ���õĴ������̣�
DriverManager
Connection
Statement
PreparedStatement
CallableStatement
ResultSet
��˵��JDBC ���������£�
1. �����ݿ⽨������
2. ���� SQL ���
3. �������
���д���θ��������������Ļ���ʾ����
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
Connection conn = DriverManager.getConnection (
"jdbc:oracle:thin:@eai-sol:1521:eai_db", "csc2", "csc2");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT CONTACTID FROM CONTACTINFO");
while (rs.next()) {long contactID = rs.getLong("CONTACTID");}
����Գ��õļ�����ͽӿ���Щ��˵����
DriverManager:
DriverManager���� JDBC �Ĺ����㣬�������û�����������֮�䡣�����ٿ��õ��������������ݿ����Ӧ��������֮�佨�����ӡ����⣬DriverManager ��Ҳ�����������������¼ʱ��
��������¼������Ϣ����ʾ�������ڼ�Ӧ�ó���һ�����Ա��Ҫ�ڴ�����ֱ��ʹ�õ�Ψһ������ DriverManager.getConnection������������ʾ���÷��������������ݿ�����ӡ�
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
Connection conn = DriverManager.getConnection (
"jdbc:oracle:thin:@eai-sol:1521:eai_db", "csc2", "csc2");
���е�һ�仰���������ڵ�ǰ�Ļ�����loadһ��DB Driver�� ���˿��ܾ�����֣� ��仰ִ����֮�� ������ô֪��ȥ�����Driver�أ� ��ʵDriverManager���Դ�load��classes�����ҵ�ע�����driver��Ȼ��ʹ�������ҵ��ĵ�һ�����Գɹ����ӵ����� URL ���������� �ڶ��仰�����������ֱ���URL, User, Password����river��һ������URL����Ҳ��һ����
Statement:
Statement �������ڽ� SQL ��䷢�͵����ݿ��С�ʵ���������� Statement �������Ƕ�Ϊ�ڸ���������ִ�� SQL ���İ�������Statement��PreparedStatement������ Statement �ж������� CallableStatement������ PreparedStatement �̳ж����������Ƕ�ר���ڷ��Ͷ����͵� SQL ��䣺 Statement ��������ִ�в��������ļ� SQL ��䣻PreparedStatement ��������ִ�д��� IN ������Ԥ���� SQL ��䣻CallableStatement ��������ִ�ж����ݿ��Ѵ洢���̵ĵ��á�
Statement �ӿ��ṩ��ִ�����ͻ�ȡ����Ļ���������PreparedStatement �ӿ������˴��� IN �����ķ������� CallableStatement �����˴��� OUT �����ķ�����
? ���� Statement ����
�����˵��ض����ݿ������֮�Ϳ��ø����ӷ��� SQL ��䡣Statement ������ Connection �ķ��� createStatement �����������д��������ʾ��
Statement stmt = conn.createStatement();
Ϊ��ִ�� Statement �������͵����ݿ�� SQL ��佫����Ϊ�����ṩ�� Statement �ķ�����
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM table1");
? ʹ�� Statement ����ִ�����
Statement �ӿ��ṩ������ִ�� SQL ���ķ�����executeQuery��executeUpdate ��execute��ʹ����һ�������� SQL ��������������ݾ�����
���� executeQuery ���ڲ����������������䣬���� SELECT ��䡣
���� executeUpdate ����ִ�� INSERT��UPDATE �� DELETE ����Լ� SQL DDL�����ݶ������ԣ���䣬���� CREATE TABLE �� DROP TABLE��INSERT��UPDATE �� DELETE ����Ч�����ı������л�����е�һ�л���С�executeUpdate �ķ���ֵ��һ��������ָʾ��Ӱ��������������¼����������� CREATE TABLE �� DROP TABLE �Ȳ������е���䣬executeUpdate �ķ���ֵ��Ϊ�㡣
���� execute ����ִ�з��ض���������������¼����������ϵ���䡣
? ������
�����Ӵ����Զ��ύģʽʱ��������ִ�е���������ʱ���Զ��ύ��ԭ���������ִ�������н������ʱ������Ϊ����ɡ����ڷ���һ��������� executeQuery �������ڼ����� ResultSet �����������ʱ�������ɡ����ڷ��� executeUpdate������ִ��ʱ��伴��ɡ������������÷��� execute ������У��ڼ������н�����������ɵĸ��¼���֮��������ɡ�
? �ر� Statement ����
Statement ������ Java �����ռ������Զ��رա�����Ϊһ�ֺõı�̷��Ӧ�ڲ���Ҫ Statement ����ʱ��ʽ�عر����ǡ��⽫�����ͷ� DBMS ��Դ�������ڱ���DZ�ڵ�
�ڴ����⡣ �ر�Statement�� stmt.close()��������
ResultSet:
ResultSet �������� SQL ����������������У�������ͨ��һ�� get ��������Щ get �������Է��ʵ�ǰ���еIJ�ͬ�У��ṩ�˶���Щ�������ݵķ��ʡ�ResultSet.next ���������ƶ��� ResultSet �е���һ�У�ʹ��һ�г�Ϊ��ǰ�С�
�����һ����һ�����������в�ѯ�����ص��б��⼰��Ӧ��ֵ�����磬�����ѯΪ SELECT a, b, c FROM Table1��������������������ʽ��
a b c
-------- --------- --------
12345 Cupertino CA
83472 Redmond WA
83492 Boston MA
����Ĵ������ִ�� SQL ����ʾ������ SQL ��佫�����м��ϣ������� 1 Ϊ int���� 2 Ϊ String������ 3 ��Ϊ�����ͣ�
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM Table1");
while (rs.next()) {
int i = rs.getInt("a");
String s = rs.getString("b");
Timestamp t = rs.getTimestamp("c");
}
? ��
ResultSet ά��ָ���䵱ǰ�����еĹ�ꡣÿ����һ�� next ��������������ƶ�һ�С������λ�ڵ�һ��֮ǰ����˵�һ�ε��� next ���ѹ�����ڵ�һ���ϣ�ʹ����Ϊ��ǰ�С�����ÿ�ε��� next ���¹�������ƶ�һ�У����մ������µĴ����ȡ ResultSet �С��� ResultSet ������丸�� Statement ����ر�֮ǰ�����һֱ������Ч��
? ��
���� getXXX �ṩ�˻�ȡ��ǰ����ij��ֵ��;������ÿһ���ڣ��ɰ��κδ����ȡ��ֵ����Ϊ�˱�֤����ֲ�ԣ�Ӧ�ô������һ�ȡ��ֵ������һ���Եض�ȡ��ֵ���������кſ����ڱ�ʶҪ���л�ȡ���ݵ��С����磬��� ResultSet ���� rs �ĵڶ�����Ϊ��title��������ֵ�洢Ϊ�ַ�������������һ���뽫��ȡ�洢�ڸ����е�ֵ��
String s = rs.getString("title");
String s = rs.getString(2);
ע�����Ǵ������ұ�ŵģ����Ҵ��� 1 ��ʼ��ͬʱ������ getXXX ��������������������ִ�Сд�� Ϊ�˴���Ŀ�ά������ɶ��ԣ���Ӧ�ý�ֹ��index�ķ�����ȡֵ����Ҫ�ö������ķ�������������ĵ�һ��ȡֵ������
? �������ͺ�ת��
���� getXXX ������JDBC ����������ͼ����������ת����ָ�� Java ���ͣ�Ȼ���ʺϵ� Java ֵ�����磬��� getXXX ����Ϊ getString�����������ݿ�����������Ϊ VARCHAR���� JDBC �������� VARCHAR ת���� Java String��getString �ķ���ֵ��Ϊ Java String ����
? NULL ���ֵ
Ҫȷ���������ֵ�Ƿ��� JDBC NULL�������ȶ�ȡ���У�Ȼ��ʹ�� ResultSet.wasNull �������ôζ�ȡ�Ƿ� JDBC NULL��
PreparedStatement:
�� PreparedStatement �ӿڼ̳� Statement������֮��������������ͬ��
PreparedStatement ʵ�������ѱ���� SQL ��䡣�����ʹ��䡰���á��� ������ PreparedStatement �����е� SQL ���ɾ���һ������ IN ������IN ������ֵ�� SQL ��䴴��ʱδ��ָ�����෴�ģ������Ϊÿ�� IN ��������һ���ʺţ�����������Ϊռλ����ÿ���ʺŵ�ֵ�����ڸ����ִ��֮ǰ��ͨ���ʵ��� setXXX �������ṩ��
���� PreparedStatement ������Ԥ�������������ִ���ٶ�Ҫ���� Statement ������ˣ����ִ�е� SQL ��侭������Ϊ PreparedStatement ���������Ч�ʡ�
��Ϊ Statement �����࣬PreparedStatement �̳��� Statement �����й��ܡ���������������һ���������������÷������ݿ���ȡ�� IN ����ռλ����ֵ��ͬʱ��
���ַ��� execute�� executeQuery �� executeUpdate �ѱ�������ʹ֮������Ҫ������
? ���� PreparedStatement ����
���µĴ���Σ����� conn �� Connection ���������������� IN ����ռλ���� SQL ���� PreparedStatement ����
PreparedStatement pstmt=conn.prepareStatement("UPDATE table1 SET a = ? WHERE b = ?");
pstmt ���������� " UPDATE table1 SET a = ? WHERE b = ?"�����ѷ��� DBMS����Ϊִ������������
? ���� IN ����
��ִ�� PreparedStatement ����֮ǰ����������ÿ�� ? ������ֵ�����ͨ������ setXXX ��������ɣ����� XXX ����ò�����Ӧ�����͡����磬����������� Java ���� long����ʹ�õķ������� setLong��setXXX �����ĵ�һ��������Ҫ���õIJ���������λ�ã��ڶ������������ø��ò�����ֵ�����磬���´��뽫��һ��������Ϊ 123456789���ڶ���������Ϊ 100000000��
pstmt.setLong(1, 123456789);
pstmt.setLong(2, 100000000);
CallableStatement:
CallableStatement ����Ϊ���е� DBMS �ṩ��һ���Ա���ʽ�����Ѵ������(Ҳ���ǣӣ�)�ķ������Ѵ�����̴��������ݿ��С����Ѵ�����̵ĵ����� CallableStatement �������������ݡ���������ʽ��һ����ʽ�������������һ����ʽ����������������������һ����� (OUT) ���������Ѵ�����̵ķ���ֵ��������ʽ���ɴ��������ɱ�����루IN �������������OUT ������������������INOUT �������IJ������ʺŽ�����������ռλ����
�� JDBC �е����Ѵ�����̵��������ʾ��ע�⣬�����ű�ʾ���������ǿ�ѡ������ű��������������ɲ��ݡ�
{call ������[(?, ?, ...)]}
���ؽ�������Ĺ��̵��Ϊ��
{? = call ������[(?, ?, ...)]}
�����������Ѵ�����̵�����ƣ�
{call ������}
ͨ�������� CallableStatement �������Ӧ��֪�����õ� DBMS ��֧���Ѵ�����̵ģ�����֪����Щ���̶���Щʲô��Ȼ���������Ҫ��飬���� DatabaseMetaData �����������ṩ��������Ϣ�����磬��� DBMS ֧���Ѵ�����̵ĵ��ã��� supportsStoredProcedures ���������� true���� getProcedures ���������ض��Ѵ�����̵�������
CallableStatement �̳� Statement �ķ������������ڴ���һ��� SQL ��䣩�����̳��� PreparedStatement �ķ������������ڴ��� IN ��������CallableStatement �ж�������з��������ڴ��� OUT ������ INOUT ������������֣�ע�� OUT ������ JDBC ���ͣ�һ�� SQL ���ͣ�������Щ�����м������������������ص�ֵ�Ƿ�Ϊ JDBC NULL��
? ���� CallableStatement ����
CallableStatement �������� Connection ���� prepareCall �����ġ��������� CallableStatement ��ʵ�������к��ж��Ѵ������ Csc_ GetCustomId���á��ù������������������������������
CallableStatement cstmt = con.prepareCall("{call CSC_GetCustomId (?, ?, ?)}");
���� ? ռλ��Ϊ IN�� OUT ���� INOUT ������ȡ�����Ѵ������ Csc_ GetCustomId��
? IN �� OUT ����
��IN �������� CallableStatement ������ͨ�� setXXX ������ɵġ��÷����̳��� PreparedStatement����������������;��������õ� setXXX ���������磬�� setFloat ������ float ֵ�ȣ���
����Ѵ�����̷��� OUT ����������ִ�� CallableStatement ������ǰ������ע��ÿ�� OUT ������ JDBC ���ͣ����DZ���ģ���ΪijЩ DBMS Ҫ�� JDBC ���ͣ���ע�� JDBC �������� registerOutParameter ��������ɵġ����ִ�����CallableStatement �� getXXX ������ȡ�ز���ֵ����ȷ�� getXXX ������Ϊ��������ע��� JDBC ��������Ӧ�� Java ����Ҳ����˵�� registerOutParameter ʹ�õ��� JDBC ���ͣ�����������ݿⷵ�ص� JDBC ����ƥ�䣩���� getXXX ��֮ת��Ϊ Java ���͡��������CSC�е�һ�����ӣ�
String sqlSp = "{call CSC_GetCustomId(?, ?, ?)}";
cstmt = conn.prepareCall(sqlSp.toString());
cstmt.registerOutParameter(1, Types.NUMERIC);
cstmt.registerOutParameter(2, Types.NUMERIC);
cstmt.registerOutParameter(3, Types.VARCHAR);
cstmt.execute();
long customerID = cstmt.getLong(1);
long lRet = cstmt.getLong(2);
String sErr = cstmt.getString(3);
? INOUT ����
��֧�������ֽ�������IJ�����INOUT ���������˵��� registerOutParameter �����⣬��Ҫ������ʵ��� setXXX �������÷����Ǵ� PreparedStatement �̳����ģ���setXXX ����������ֵ����Ϊ����������� registerOutParameter ���������� JDBC ����ע��Ϊ���������setXXX �����ṩһ�� Java ֵ�������������Ȱ����ֵת��Ϊ JDBC ֵ��Ȼ�����͵����ݿ��С����� IN ֵ�� JDBC ���ͺ��ṩ�� registerOutParameter ������ JDBC ����Ӧ����ͬ��Ȼ��Ҫ�������ֵ����Ҫ�ö�Ӧ�� getXXX ���������磬Java ����Ϊ byte �IJ���Ӧ��
ʹ�÷��� setByte ��������ֵ��Ӧ�ø� registerOutParameter �ṩ����Ϊ TINYINT �� JDBC ���ͣ�ͬʱӦʹ�� getByte ���������ֵ������������һ���Ѵ������ reviseTotal����Ψһ������ INOUT ���������� setByte �Ѵ˲�����Ϊ 25��������������Ϊ JDBC TINYINT �����͵����ݿ��С����ţ�registerOutParameter ���ò���ע��Ϊ JDBC TINYINT��ִ������Ѵ�����̺�����һ���µ� JDBC TINYINT ֵ������ getByte ���������ֵ��Ϊ Java byte ���ͼ�����
CallableStatement cstmt = con.prepareCall("{call reviseTotal(?)}");
cstmt.setByte(1, 25);
cstmt.registerOutParameter(1, java.sql.Types.TINYINT);
cstmt.executeUpdate();
byte x = cstmt.getByte(1);
11. ����
���ģʽ
1��Singletonģʽ
Singletonģʽ��Ҫ�����DZ�֤��JavaӦ�ó����У�һ��Classֻ��һ��ʵ�����ڡ�һ�������ַ�����
? ����һ���࣬���Ĺ��캯��Ϊprivate�ģ����з���Ϊstatic�ġ����������������ȫ����ͨ������ֱ�����á����磺
private SingleClass() {}
public static String getMethod1() {}
public static ArrayList getMethod2() {}
? ����һ���࣬���Ĺ��캯��Ϊprivate�ģ�����һ��static��private�ĸ��������ͨ��һ��public��getInstance������ȡ����������,�̶��������еķ��������磺
private staitc SingleClass _
instance = null;
private SingleClass() {}
public static SingleClass getInstance() {
if (_instance == null) {_instance = new SingleClass();}
return _instance; }
public String getMethod1() {}
public ArrayList getMethod2() {}
2��Prototypeģʽ
Prototypeģʽ����
���������������ǵ�����������Ҫ����ʱ�����Դʱ����Java�У�Prototypeģʽ��ʵ����ͨ������clone(),�÷���������Java�ĸ�����Object��, ��ˣ�Java�е���������ֻҪ�����������ˡ�ͨ��clone(),���ǿ��Դ�һ�������ø���Ķ���
������������ǵ���Ҫ�����ǵ����ԡ�
public class Prototype implements Cloneable {
private String Name;
public rototype(String Name) {this.Name = Name; }
public void setName(String Name) {this.Name = Name; }
public String getName() {return Name; }
public Object clone() {
try{return super.clone();
}catch(CloneNotSupportedException cnse){
cnse.printStackTrace();
return null;
}
}}
Prototype p = new Prototype("My First Name");
Prototype p1 = p.clone();
p.setName("My Second Name");
Prototype p2 = p.clone();
3. Factoryģʽ��Abstract Factoryģʽ
? Factoryģʽ
���ø�Factory���ݲ�ͬ�IJ������Է��ؾ�����ͬ�����ʵ����ͬһ�ӿڵĶ���
? Abstract Factoryģʽ
������Factoryģʽ����Factory������ͨ��Factory���ز�ͬ�Ķ���
�������Sun XML Parser�е����ӣ�
// 1. Abstract Factoryģʽ
SAXParserFactory spf = SAXParserFactory.newInstance();
String validation = System.getProperty ("javax.xml.parsers.validation", "false");
if (validation.equalsIgnoreCase("true")) {spf.setValidating (true); }
// 2. Factoryģʽ
SAXParser sp = spf.newSAXParser();
parser = sp.getParser();
parser.setDocumentHandler(this);
parser.parse (uri);
1. SAXParserFactory�еľ�̬����newInstance()����ϵͳ����javax.xml.parsers.SAXParserFactory��ͬ��ֵ���ɲ�ͬ��SAXParserFactory����spf��Ȼ��SAXParserFactory���������÷���newSAXParser()����SAXParser����
ע�⣺
SAXParserFactory �Ķ���Ϊ��
public abstract class SAXParserFactory extends java.lang.Object
SAXParserFactoryImpl �Ķ���Ϊ��
public class SAXParserFactoryImpl extends javax.xml.parsers.SAXParserFactory
public static SAXParserFactory newInstance() {
String factoryImplName = null;
try {
factoryImplName =System.getProperty("javax.xml.parsers.SAXParserFactory",
"com.sun.xml.parser.SAXParserFactoryImpl");
} catch (SecurityException se) {
factoryImplName = "com.sun.xml.parser.SAXParserFactoryImpl";
}
SAXParserFactory factoryImpl;
try {
Class clazz = Class.forName(factoryImplName);
factoryImpl = (SAXParserFactory) clazz.newInstance();
} catch (ClassNotFoundException cnfe) {
throw new FactoryConfigurationError(cnfe);
} catch (IllegalAccessException iae) {
throw new FactoryConfigurationError(iae);
} catch (InstantiationException ie) {
throw new FactoryConfigurationError(ie);
}
return factoryImpl;
}
2. newSAXParser() ������SAXParserFactory����������
SAXParserFactoryImpl�̳���SAXParserFactory����ʵ���˷���newSAXParser()��
public SAXParser newSAXParser()
throws SAXException, ParserConfigurationException {
SAXParserImpl saxParserImpl = new SAXParserImpl(this);
return saxParserImpl;
}
ע�⣺
SAXParserImpl�Ķ���Ϊ��
public class SAXParserImpl extends javax.xml.parsers.SAXParser
SAXParserImpl�Ĺ��캯������Ϊ��
public SAXParserImpl(SAXParserFactory spf)
throws SAXException, ParserConfigurationException {
super();
this.spf = spf;
if (spf.isValidating ()) {
parser = new ValidatingParser();
validating = true;
} else { parser = new Parser();}
if (spf.isNamespaceAware ()) {
namespaceAware = true;
throw new ParserConfigurationException(
"Namespace not supported by SAXParser");
}
}