1、内部存储结构
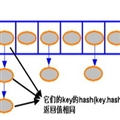
HashMap的内部存储结构是数组,默认初始化为16长度的Entry[],对于
hash冲突采用拉链方法解决,所以它是数组和链表的合体。
2、
理解HashMap做到
合理使用
假设我们要存放100W数据到HashMap中,那么分到每个链上就有100W/16个数据,显然这样的map是不合理的。
HashMap采用resize数组来增加数据长度降低拉链过长造成的性能影响,当put数据时put方法会判断map中的数据数量是否到达了需要扩充大小的临界点,临界点计算方法是当前数组长度*loadFactor(默认值是0.75),到了临界点后数组长度会扩容到当前数组的2倍。
resize方法相当消耗资源,不过拉链过长已经发生了性能问题,resize也只是性能分摊,以解决后面的性能问题吧,还是值得的,但当我们自己
写代码时如果能够预测到HashMap中需要存放多少数据那么我们最好自己定义HashMap数组长度和加载因子loadFactor。
另外不要以为new HashMap(30)就会分配一个长度为30的数组,HashMap会重新给你算一个最优值(一个2的n次幂且大小30,n能取到最小值的数字),32,那么resize临界值就是32*0.75=24,看来指定了长度还是会resize,但
构造函数里还有一个参数就是加载因子,修改new HashMap(30, 1),这样我们就指定了一个长度为32,加载因子为1的map,这时我们放30个数据时就不会触发resize了,但如果还继续增加数据,数据个数达到32时就会进行一次resize,不过这也是理所应当。
HashMap为什么要重新算一个2的n次幂长度呢?这就是HashMap中hash的精髓了
put数据过程:首先拿到数据的hashcode,然后再和数组长度-1做与运算找到应存储在数组上的位置,最后进行存储
举例:
数组长度16,存储三个数据的key的hash值分别为1、2、3
用数组长度和1、2、3分别做与操作,得到0、0、0;用数组长度-1和1、2、3做与操作得到1、2、3
用
二进制表示会看的更清楚10000&1=0,10000&10=0,10000&11=0;1111&1=1,1111&10=10,1111&11=11
原因就很明显了,只要key有不同的hash值那么冲突的可能性就很平均,查询效率在整体上也会有所提前
除非定长,否则最好不要自己定义加载因子,使用默认就好(new HashMap(30)、new HashMap(64)、new HashMap(128))。
3、key值的hashCode和equals
HashMap的key可以是任意对象,假设我们用
在线用户来做key,在线用户对象包括用户id,用户名,
用户登录时间,那么显然这个key值中用用户id就可以唯一确定一个值,而加上用户登录时间就不一定了如果一个系统允许用户登录多次就有问题了(可以不太恰当)
这时我们就需要改写hashCode和equals方法,在计算hashCode和equals时只需要考虑用户id这一个属性就可以了
在程序书写过程中也要考虑改写对其它代码造成的影响,如果影响到其它代码了就要重新定义一个key对象了,千万不能在hashCode代码中return 1,那就悲剧了,全在一条拉链上
4、一些源码
void resize(int newCapacity) {// newCapacity为原数据长度的2倍
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);// 将老数组里的数据copy到新数组,是整个HashMap中最耗性能的代码
table = newTable;
threshold = (int)(newCapacity * loadFactor);// 重新定义临界值
}
void transfer(Entry[] newTable) {// 将老数组里的数据copy到新数组,是整个HashMap中最耗性能的代码,要遍历所有数组元素,遍历所有拉链数据,并重新计算存储点,重新拉小链cool
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
public HashMap(int initialCapacity, float loadFactor) {// 构造方法指定长度和加载因子
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)// 直到取到最优值,目的是为了减少hash冲突
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {// 计算key在数组上的存储位置,h为key的hash值,length为数组长度
return h & (length-1);
}
static
class Entry<K,V> implements Map.Entry<K,V> {// 静态内部类Entry完成了LinkdList和Entry[]合体后就是HashMap的存储结构了
final K key;
V value;
Entry<K,V> next;
final int hash;
….
}
5、总结
给HashMap一个合理初始大小,注意加载因子的使用,如果没有特殊要求尽量默认,不知道默认值为什么是0.75时我选择相信sun的工程师
如果使用HashMap做数据
缓存要考虑数据量大小,如果量大则占用
内存,性能也会受到影响,可以考虑会其它cache替代,oscache、ehcache或分布式缓存memcached等
MashMap非
线程安全,应用ConcurrentHashMap替代
对象做key时最好注意下是否需要重写hashCode和equals,但要避免代码不合理引起的hash冲突
尽量避免遍历map,人家就不是干这个的
key为数字时使用考虑使用ArrayList,或与ArrayList配合使用寻求高效
转载:http://blog.shilimin.com/219.htm

- 大小: 34.1 KB