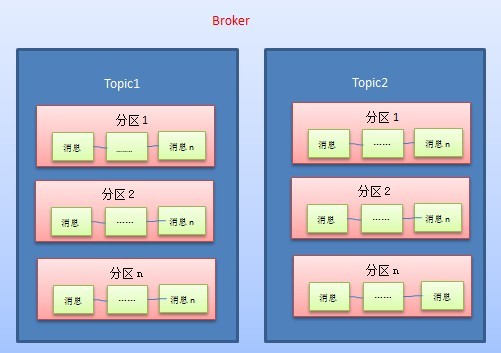
前面忘了先介绍一下Broker消息存储的组织方式,我们前面知道了一条消息属于某个Topic下的某个分区,消息存储的组织方式是按照此方式进行组织的,结构图如下:
?
?
所以对于每个Topic而言,分区是最小的元素,对外API主要由MessageStore提供,一个MessageStore实例代表一个分区的实例,分区存储具体的内容。在MetaQ中,分区的存储采用的多文件的方式进行组合,即MessageStore由多个FileMessageSet组成,而FileMessageSet在MessageStore被包装成Segment,代码如下(MessageStore是值得好好分析的一个类):
?
?
class="java" name="code">public class MessageStore extends Thread implements Closeable {
…….
}
MessageStore继承了Thread类,继承该类主要是为了实现异步写入方式?
?
public MessageStore(final String topic, final int partition, final MetaConfig metaConfig,
final DeletePolicy deletePolicy, final long offsetIfCreate) throws IOException {
this.metaConfig = metaConfig; //全局配置信息
this.topic = topic; //当前主题
final TopicConfig topicConfig = this.metaConfig.getTopicConfig(this.topic);
String dataPath = metaConfig.getDataPath(); //当前分区的存储路径
if (topicConfig != null) {
dataPath = topicConfig.getDataPath();
}
final File parentDir = new File(dataPath);
this.checkDir(parentDir); //检测父目录是否存在
this.partitionDir = new File(dataPath + File.separator + topic + "-" + partition);
this.checkDir(this.partitionDir);
// this.topic = topic;
this.partition = partition; //当前分区
this.unflushed = new AtomicInteger(0); //未提交的消息数
this.lastFlushTime = new AtomicLong(SystemTimer.currentTimeMillis()); //最后一次提交时间
this.unflushThreshold = topicConfig.getUnflushThreshold(); //最大允许的未flush消息数,超过此值将强制force到磁盘,默认1000
this.deletePolicy = deletePolicy; //由于是多文件的存储方式,消费过的消息或过期消息需要删除从而腾出空间给新消息的,默认提供归档和过期删除的方式
// Make a copy to avoid getting it again and again.
this.maxTransferSize = metaConfig.getMaxTransferSize();
//启动异步写入的时候,消息提交到磁盘的size配置,同时也是配置组写入时,消息最大长度的控制参数,如果消息长度大于该参数,则会同步写入
this.maxTransferSize = this.maxTransferSize > ONE_M_BYTES ? ONE_M_BYTES : this.maxTransferSize;
// Check directory and load exists segments.
this.checkDir(this.partitionDir);
this.loadSegments(offsetIfCreate);
if (this.useGroupCommit()) {
this.start();
}
}
首先是获取配置信息,其次由于MessageStore采用的多文件存储方,所以要检查父目录的存在,最后则是加载校验已有数据,如果配置了异步写入,则启动异步写入线程(如果unflushThreshold<= 0,则认为启动异步写入的方式)
?
我们发现在构造方法的倒数第3行调用了loadSegments()方法去加载校验文件,看看该方法到底做了些什么事情
?
private void loadSegments(final long offsetIfCreate) throws IOException {
final List<Segment> accum = new ArrayList<Segment>();
final File[] ls = this.partitionDir.listFiles();
if (ls != null) {
//遍历目录下的所有.meta后缀的数据文件,将所有文件都变为不可变的文件
for (final File file : ls) {
if (file.isFile() && file.toString().endsWith(FILE_SUFFIX)) {
if (!file.canRead()) {
throw new IOException("Could not read file " + file);
}
final String filename = file.getName();
final long start = Long.parseLong(filename.substring(0, filename.length() - FILE_SUFFIX.length()));
// 先作为不可变的加载进来
accum.add(new Segment(start, file, false));
}
}
}
if (accum.size() == 0) {
// 没有可用的文件,创建一个,索引从offsetIfCreate开始
final File newFile = new File(this.partitionDir, this.nameFromOffset(offsetIfCreate));
accum.add(new Segment(offsetIfCreate, newFile));
} else {
// 至少有一个文件,校验并按照start升序排序
Collections.sort(accum, new Comparator<Segment>() {
@Override
public int compare(final Segment o1, final Segment o2) {
if (o1.start == o2.start) {
return 0;
} else if (o1.start > o2.start) {
return 1;
} else {
return -1;
}
}
});
// 校验文件,是否前后衔接,如果不是,则认为数据文件被破坏或者篡改,抛出异常
this.validateSegments(accum);
// 最后一个文件修改为可变
final Segment last = accum.remove(accum.size() - 1);
last.fileMessageSet.close();
log.info("Loading the last segment in mutable mode and running recover on " + last.file.getAbsolutePath());
final Segment mutable = new Segment(last.start, last.file);
accum.add(mutable);
log.info("Loaded " + accum.size() + " segments...");
}
this.segments = new SegmentList(accum.toArray(new Segment[accum.size()]));
//多个segmentg通过SegmentList组织起来,SegmentList能保证在并发访问下的删除、添加保持一致性,SegmentList没有采用java的关键字 synchronized进行同步,而是使用类似cvs原语的方式进行同步访问(因为绝大部分情况下并没有并发问题,可以极大的提高效率),该类比较简单就不再分析
}
?
MessageStore采用Segment方式组织存储,Segment包装了FileMessageSet,由FileMessageSet进行读写,MessageStore并将多个Segment进行前后衔接,衔接方式为:第一个Segment对应的消息文件命名为0.meta,第二个则命名为第一个文件的开始位置+第一个Segment的大小,图示如下(假设现在每个文件大小都为1024byte):
?
为什么要这样进行设计呢,主要是为了提高查询效率。MessageStore将最后一个Segment变为可变Segment,因为最后一个Segment相当于文件尾,消息是有先后顺序的,必须将消息添加到最后一个Segment上。
?关注validateSegments()方法做了些什么事情
?
private void validateSegments(final List<Segment> segments) {
//验证按升序排序的Segment是否前后衔接,确保文件没有被篡改和破坏(这里的验证是比较简单的验证,消息内容的验证在FileMessageSet中,通过比较checksum进行验证,在前面的篇幅中介绍过,这两种方式结合可以在范围上从大到小进行验证,保证内容基本不被破坏和篡改)
this.writeLock.lock();
try {
for (int i = 0; i < segments.size() - 1; i++) {
final Segment curr = segments.get(i);
final Segment next = segments.get(i + 1);
if (curr.start + curr.size() != next.start) {
throw new IllegalStateException("The following segments don't validate: "
+ curr.file.getAbsolutePath() + ", " + next.file.getAbsolutePath());
}
}
} finally {
this.writeLock.unlock();
}
}
?
?
? ?ITEye整理格式好麻烦,下面的代码分析直接在代码中分析
?
?
//添加消息的方式有两种,同步和异步
public void append(final long msgId, final PutCommand req, final AppendCallback cb) {
//首先将内容包装成前面介绍过的消息存储格式
this.appendBuffer(MessageUtils.makeMessageBuffer(msgId, req), cb);
}
//异步写入的包装类
private static class WriteRequest {
public final ByteBuffer buf;
public final AppendCallback cb;
public Location result;
public WriteRequest(final ByteBuffer buf, final AppendCallback cb) {
super();
this.buf = buf;
this.cb = cb;
}
}
//这里比较好的设计是采用回调的方式来,对于异步写入实现就变得非常容易
//AppendCallback返回的是消息成功写入的位置Location(起始位置和消息长度),该Location并不是相对于当前Segment的开始位置0,而是相对于当前Segment给定的值(对应文件命名值即为给定的值),以后查询消息的时候直接使用该位置就可以快速定位到消息写入到哪个文件
//这也就是为什么文件名的命名采用前后衔接的方式,这也通过2分查找可以快速定位消息的位置
private void appendBuffer(final ByteBuffer buffer, final AppendCallback cb) {
if (this.closed) {
throw new IllegalStateException("Closed MessageStore.");
}
//如果启动异步写入并且消息长度小于一次提交的最大值maxTransferSize,则将该消息放入异步写入队列
if (this.useGroupCommit() && buffer.remaining() < this.maxTransferSize) {
this.bufferQueue.offer(new WriteRequest(buffer, cb));
} else {
Location location = null;
final int remainning = buffer.remaining();
this.writeLock.lock();
try {
final Segment cur = this.segments.last();
final long offset = cur.start + cur.fileMessageSet.append(buffer);
this.mayBeFlush(1);
this.mayBeRoll();
location = Location.create(offset, remainning);
} catch (final IOException e) {
log.error("Append file failed", e);
location = Location.InvalidLocaltion;
} finally {
this.writeLock.unlock();
if (cb != null) {
cb.appendComplete(location);
}
//调用回调方法,数据写入文件缓存
}
}
}
……
//判断是否启用异步写入,如果设置为unflushThreshold <=0的数字,则认为启动异步写入;如果设置为unflushThreshold =1,则是同步写入,即每写入一个消息都会提交到磁盘;如果unflushThreshold>0,则是依赖组提交或者是超时提交
private boolean useGroupCommit() {
return this.unflushThreshold <= 0;
}
@Override
public void run() {
// 等待force的队列
final LinkedList<WriteRequest> toFlush = new LinkedList<WriteRequest>();
WriteRequest req = null;
long lastFlushPos = 0;
Segment last = null;
//存储没有关闭并且线程没有被中断
while (!this.closed && !Thread.currentThread().isInterrupted()) {
try {
if (last == null) {
//获取最后的一个segment,将消息写入最后segment对应的文件
last = this.segments.last();
lastFlushPos = last.fileMessageSet.highWaterMark();
}
if (req == null) {
//如果等待提交到磁盘的队列toFlush为空,则两种可能:一、刚刚提交完,列表为空;二、等待写入消息的队列为空,如果判断toFlush,则调用bufferQueue.take()方法,可以阻塞住队列,而如果toFlush不为空,则调用bufferQueue.poll,这是提高性能的一种做法。
if (toFlush.isEmpty()) {
req = this.bufferQueue.take();
} else {
req = this.bufferQueue.poll();
//如果当前请求为空,表明等待写入的消息已经没有了,这时候文件缓存中的消息需要提交到磁盘,防止消息丢失;或者如果已经写入文件的大小大于maxTransferSize,则提交到磁盘
//这里需要注意的是,会出现这样一种情况,刚好最后一个segment的文件快满了,这时候是不会roll出一个新的segment写入消息的,而是直接追加到原来的segment尾部,可能导致segment对应的文件大小大于配置的单个segment大小
if (req == null || last.fileMessageSet.getSizeInBytes() > lastFlushPos + this.maxTransferSize) {
// 强制force,确保内容保存到磁盘
last.fileMessageSet.flush();
lastFlushPos = last.fileMessageSet.highWaterMark();
// 通知回调
//异步写入比组写入可靠,因为异步写入一定是提交到磁盘的时候才进行回调的,而组写入如果依赖组提交的方式,则可能会丢失数据,因为组写入在消息写入到文件缓存的时候就进行回调了(除非设置unflushThreshold=1)
for (final WriteRequest request : toFlush) {
request.cb.appendComplete(request.result);
}
toFlush.clear();
// 是否需要roll
this.mayBeRoll();
// 如果切换文件,重新获取last
if (this.segments.last() != last) {
last = null;
}
continue;
}
}
}
if (req == null) {
continue;
}
//写入文件,并计算写入位置
final int remainning = req.buf.remaining();
//写入位置为:当前segment给定的值 + 加上文件已有的长度
final long offset = last.start + last.fileMessageSet.append(req.buf);
req.result = Location.create(offset, remainning);
if (req.cb != null) {
toFlush.add(req);
}
req = null;
} catch (final IOException e) {
log.error("Append message failed,*critical error*,the group commit thread would be terminated.", e);
// TODO io异常没办法处理了,简单跳出?
break;
} catch (final InterruptedException e) {
// ignore
}
}
// terminated
//关闭store 前,将等待写入队列中的剩余消息写入最后一个文件,这时候如果最后一个Segment满了也不会roll出新的Segment,持续的将消息写入到最后一个Segment,所以这时候也会发生Segment的size大于配置的size的情况
try {
for (WriteRequest request : this.bufferQueue) {
final int remainning = request.buf.remaining();
final long offset = last.start + last.fileMessageSet.append(request.buf);
if (request.cb != null) {
request.cb.appendComplete(Location.create(offset, remainning));
}
}
this.bufferQueue.clear();
} catch (IOException e) {
log.error("Append message failed", e);
}
}
……
//Append多个消息,返回写入的位置
public void append(final List<Long> msgIds, final List<PutCommand> putCmds, final AppendCallback cb) {
this.appendBuffer(MessageUtils.makeMessageBuffer(msgIds, putCmds), cb);
}
/**
* 重放事务操作,如果消息没有存储成功,则重新存储,并返回新的位置
*/
public void replayAppend(final long offset, final int length, final int checksum, final List<Long> msgIds,
final List<PutCommand> reqs, final AppendCallback cb) throws IOException {
//如果消息没有存储,则重新存储,写到最后一个Segment尾部
final Segment segment = this.findSegment(this.segments.view(), offset);
if (segment == null) {
this.append(msgIds, reqs, cb);
} else {
final MessageSet messageSet = segment.fileMessageSet.slice(offset - segment.start, offset - segment.start + length);
final ByteBuffer buf = ByteBuffer.allocate(length);
messageSet.read(buf, offset - segment.start);
buf.flip();
final byte[] bytes = new byte[buf.remaining()];
buf.get(bytes);
// 这个校验和是整个消息的校验和,这跟message的校验和不一样,注意区分
final int checkSumInDisk = CheckSum.crc32(bytes);
// 没有存入,则重新存储
if (checksum != checkSumInDisk) {
this.append(msgIds, reqs, cb);
} else {
// 正常存储了消息,无需处理
if (cb != null) {
this.notifyCallback(cb, null);
}
}
}
}
//判断是否需要roll,如果当前 messagestore最后一个segment的size>=配置的segment size,则产生新的segment,并将新的segment作为最后一个segment,原来最后的segment提交一次,并将mutable设置为false
private void mayBeRoll() throws IOException {
if (this.segments.last().fileMessageSet.getSizeInBytes() >= this.metaConfig.getMaxSegmentSize()) {
this.roll();
}
}
String nameFromOffset(final long offset) {
final NumberFormat nf = NumberFormat.getInstance();
nf.setMinimumIntegerDigits(20);
nf.setMaximumFractionDigits(0);
nf.setGroupingUsed(false);
return nf.format(offset) + FILE_SUFFIX;
}
private long nextAppendOffset() throws IOException {
final Segment last = this.segments.last();
last.fileMessageSet.flush();
return last.start + last.size();
}
private void roll() throws IOException {
final long newOffset = this.nextAppendOffset();
//新的segment对应的存储文件的命名为原来最后一个segment的起始位置 + segment的size
final File newFile = new File(this.partitionDir, this.nameFromOffset(newOffset));
this.segments.last().fileMessageSet.flush();
this.segments.last().fileMessageSet.setMutable(false);
this.segments.append(new Segment(newOffset, newFile));
}
//判断是否需要消息提交到磁盘,判断的条件有两个,如果达到组提交的条件或者达到间隔的提交时间
private void mayBeFlush(final int numOfMessages) throws IOException {
if (this.unflushed.addAndGet(numOfMessages) > this.metaConfig.getTopicConfig(this.topic).getUnflushThreshold()
|| SystemTimer.currentTimeMillis() - this.lastFlushTime.get() > this.metaConfig.getTopicConfig(this.topic).getUnflushInterval()) {
this.flush0();
}
}
//提交到磁盘
public void flush() throws IOException {
this.writeLock.lock();
try {
this.flush0();
} finally {
this.writeLock.unlock();
}
}
private void flush0() throws IOException {
if (this.useGroupCommit()) {
return;
}
//由于只有最后一个segment是可变,即可写入消息的,所以只需要提交最后一个segment的消息
this.segments.last().fileMessageSet.flush();
this.unflushed.set(0);
this.lastFlushTime.set(SystemTimer.currentTimeMillis());
}
@Override
public void close() throws IOException {
this.closed = true;
this.interrupt();
//等待子线程完成写完异步队列中剩余未写的消息
try {
this.join(500);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
//关闭segment,保证内容都已经提交到磁盘
for (final Segment segment : this.segments.view()) {
segment.fileMessageSet.close();
}
}
//返回segment的信息,主要包括segment的开始位置以及 segment 的size
public List<SegmentInfo> getSegmentInfos() {
final List<SegmentInfo> rt = new ArrayList<SegmentInfo>();
for (final Segment seg : this.segments.view()) {
rt.add(new SegmentInfo(seg.start, seg.size()));
}
return rt;
}
/**
* 返回当前最大可读的offset
*/
//需要注意的是,在文件缓存中的消息是不可读的,可以通过getSizeInBytes()方法来判断还有多少内容还在文件缓存中,getSizeInBytes()方法返回的值是包括所有在磁盘和缓存中的size
public long getMaxOffset() {
final Segment last = this.segments.last();
if (last != null) {
return last.start + last.size();
} else {
return 0;
}
}
/**
* 返回当前最小可读的offset
*/
public long getMinOffset() {
Segment first = this.segments.first();
if (first != null) {
return first.start;
} else {
return 0;
}
}
/**
* 根据offset和maxSize返回所在MessageSet, 当offset超过最大offset的时候返回null,
* 当offset小于最小offset的时候抛出ArrayIndexOutOfBounds异常
*/
//代码的注释以及清楚的解析了作用
public MessageSet slice(final long offset, final int maxSize) throws IOException {
final Segment segment = this.findSegment(this.segments.view(), offset);
if (segment == null) {
return null;
} else {
return segment.fileMessageSet.slice(offset - segment.start, offset - segment.start + maxSize);
}
}
/**
* 根据offset查找文件,如果超过尾部,则返回null,如果在头部之前,则抛出ArrayIndexOutOfBoundsException
*/
//指定位置找到对应的segment,由于前面的文件组织方式,所以这里可以采用2分查找的方式,
//效率很高
Segment findSegment(final Segment[] segments, final long offset) {
if (segments == null || segments.length < 1) {
return null;
}
// 老的数据不存在,返回最近最老的数据
final Segment last = segments[segments.length - 1];
// 在头部以前,抛出异常
if (offset < segments[0].start) {
throw new ArrayIndexOutOfBoundsException();
}
// 刚好在尾部或者超出范围,返回null
if (offset >= last.start + last.size()) {
return null;
}
// 根据offset二分查找
int low = 0;
int high = segments.length - 1;
while (low <= high) {
final int mid = high + low >>> 1;
final Segment found = segments[mid];
if (found.contains(offset)) {
return found;
} else if (offset < found.start) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return null;
}
?未完待续,下篇介绍存储模块的文件删除策略
?
?
?
?
?
![纯手工打造[博客园-闪存数据分析]总结报告](/Upload/SmallIMG/2013082318/57D49B8500D744B6.png)







