英文原文:Starbucks Could Use Your Social Data To Find New Locations
剑桥大学的研究人员解析了 5 个月内用户发布在 Twitter 上的星巴克、麦当劳、Dunkin' Donuts (仅限纽约)相关的 62 万个签到数据(约是该时期内 Foursquare 四分之一的签到量),同时结合传统的地理区位数据,利用机器学习算法得出一个研究结果:Foursquare 签到数据有助于星巴克、麦当劳、Dunkin' Donuts 这样的快餐连锁店选择更好的门店地址。
首先,该研究团队分析了影响客流量的传统区位因素,比如邻近商户的类型,所在范围内商户类型是否丰富,是否有吸引人的地标,是否靠近火车站等。其次,他们利用签到数据分析了哪些是顾客密集区,一个门店之于另一个门店的受欢迎程度,不同地点之间的客流特点。
这些区位因素特征和数值目的是用于描述每个门店的区位特点,以及对几个不同的机器学习算法进行训练:Support Vector、 Regression、 M5 decision trees 和 Linear Regression 。根据三分之二的门店选址随机样本和其已知受欢迎程度,每个算法会被训练 1000 遍,而后系统会得出剩下三分之一门店的客流密集程度。接着会得出选址的优劣排名,这个结果可以拿来和这些选址的真实签到密度相比较得出其中的关联。

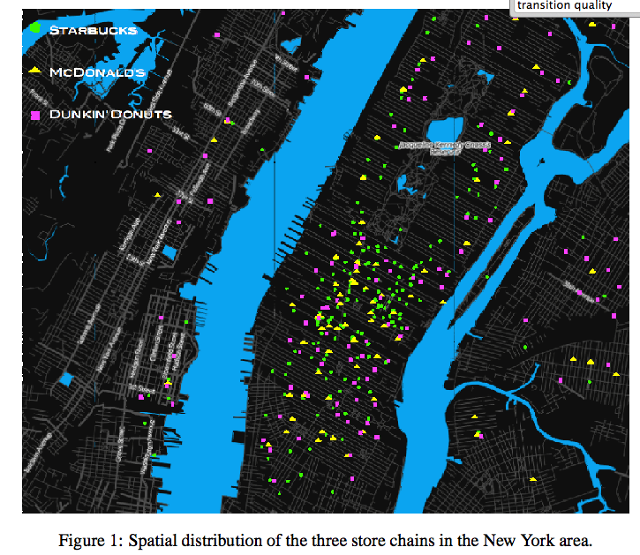
该研究团队发现星巴克、麦当劳、Dunkin' Donuts 签到数据模式各有特点。星巴克在签到总量是麦当劳和 Dunkin' Donuts 之和的 5 倍,但该结果忽略的一个事实是迈哈顿的星巴克门店本就是麦当劳和 Dunkin' Donuts 的 2 倍。而且星巴克建在火车站附近的机率也更大。
三个连锁店的选址预测模型各有不同的特征。竞争激烈程度是星巴克预测模型中权重最大的因素,这意味着它在周边竞争对手较少的时候表现更好;对麦当劳来说,其顾客多来自当前商业区以外,他们往往不太在乎稍远的行程。 Dunkin' Donuts 的顾客则多是购物人群,它的顾客往往会在邻近的周边商铺签到。
这个研究发现,即便有这些差异,不管针对哪家连锁店,传统地理特征和基于 Foursquare 的签到数据解析出的人员流动特征相结合都能得到最好的预测结果。如果以纽约全部星巴克门店为基数,门店选址的准确率为 67%,如果以 10% 和 15% 的客流密集的门店为基数,准确率为 76%。