最近做的搜索引擎的数据量是越来越大估计了下在中国可能涉及到的1Kw的数据量,就全球来说也就是1K亿而已,最初是用的数据库是MySQL现在来说要做些优化,最终使用的两个方案很好用的。
1.读写分离;
2.纵向横向拆分库、表。
MySQL的基本功能中包括replication(复制)功能。所谓replication,就是确定master以及与之同步的slave服务器,再加上slave将master中写入的内容polling过来更新自身内容的功能。这样slave就是master的replica(复制品)。这样就可以准备多台内容相同的服务器。
通过master和salve的replication,准备好多台服务器之后,让应用程序服务器通过负载均衡器去处理查询slave。这样就能将查询分散到多台服务器上。
应用程序实现上应该只把select等读取之类的查询发送给负载均衡器,而更新应当直接发送给master。要是在slave上执行更新操作,slave和master的内容就无法同步。MySQL会检测到master和slave之间内容差异,并停止replication,这回导致系统故障。Slave可以采用LVS(linux系统自带的负载均衡器)实现查询的负载均衡。
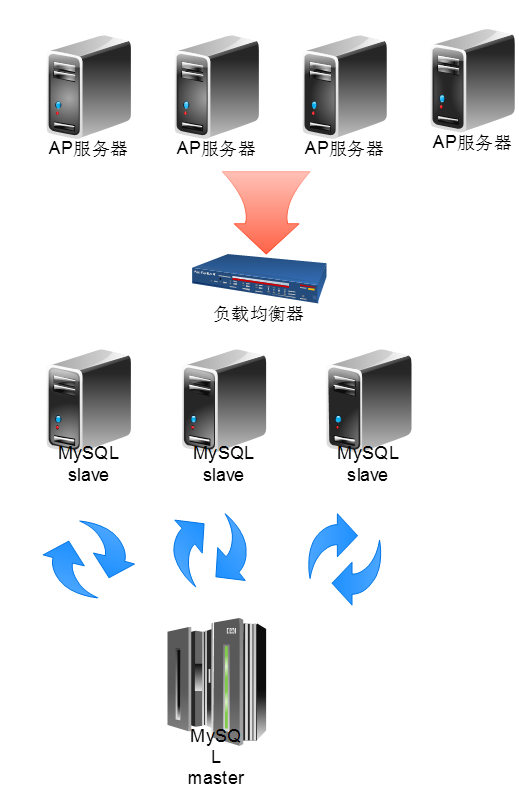
使用MySQL的replication是利用的冗余化,实现冗余化需要实现的最小服务器数量是4台,三台slave和一台master,slave为什么是需要三台呢,比如一台slave死机了,现在需要修复再次上线,那么意味着你必须停止一台slave来复制MySQL的数据,如果只有两台slave,一台坏了,你就必须停止服务,如果有三台,坏了一台,你复制数据时停止一台,还有一台可以运维。
对于数据的处理是能放入到内存中就尽量放入到内存中如果不能放入到内存中,可以利用MySQL的Partitioning。
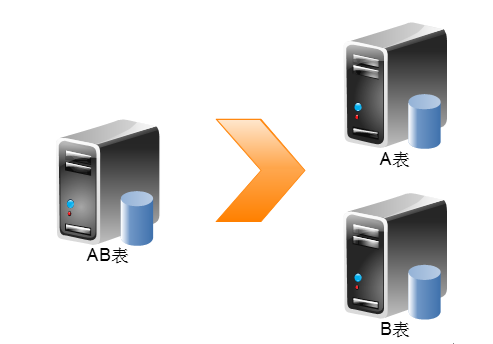
Partitioning就是表分割也就是讲A表和B表放在不同的服务器上。简单来说,Partitioning就是充分利用局部性进行分割,提高缓存利用效率,从而实现Partitioning的效果。其中最重要的一点就是以Partitioning为前提设计的系统将表分割开,用RDBMS的方式的话,对于一对多的关系经常使用JOIN查询将两张表连接起来。但是如果将表分割开了之后,也就是两张表不在同一个数据库,不在同一个服务器上怎样使用JOIN操作,这里需要注意的是如果是用where in操作不是省了一些麻烦了嘛。