Lucene4.3开发之第三步之温故知新(三)
- 摘要:前面几篇笔者已经把Lucene的最基本的入门,介绍完了,本篇就对Lucene基本的知识做一个总结,以便于加深对Lucene基本API组件的理解。为了方便对比学习,下面给出表格数据索引期间使用的API组件检索期间使用的API组件IndexWriterIndexReaderIndexWriterConfigIndexSearcherDirectoryDirectoryAnalyzerQueryParser或者Query子类DocumentTopDocsFieldScoreDoc-
- 标签:开发 lucene
前面几篇笔者已经把Lucene的最基本的入门,介绍完了,本篇就对Lucene基本的知识做一个总结,以便于加深对Lucene基本API组件的理解。
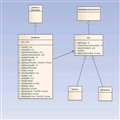
为了方便对比学习,下面给出表格数据
索引期间使用的API组件检索期间使用的API组件IndexWriterIndexReaderIndexWriterConfigIndexSearcherDirectoryDirectoryAnalyzerQueryParser或者Query子类DocumentTopDocsFieldScoreDoc--Term
下面笔者就对上图组件一一剖析下
首页要介绍的就索引期间的各个类
1,IndexWriter是索引过程中的核心类,主要负责创建索引或者打开已有索引,提供对索引的
添加,删除,修改等操作
2,IndexWriterConfig这个API在低版本的Lucene中是没有此配置类的,这个类也比较重要,使用此类则需要在其构造方法中传入2个参数,第一个参数是Lucene当前的版本号,第二个是索引是使用的分词器,除了这个我们最常用的功能,里面还提供了大量工具方法,例如,设置内存里缓冲大小,设置文档数据批量提交时大小,获取线程状态,设置创建模式,以及是否开启复合索引的等等一系列,可以对索引做一些基本的配置优化等信息。
3,Directory这个类代表了Lucene索引的存放位置,是一个抽象类,它有一系列子类可以用来处理索引,使用不同的子类对于系统的性能,影响会很大,但归其本质上,提升性能,无非就拿空间换时间或拿时间或空间2中情况,在具体使用时,我们可以使用其子类来获取索引所在的存储路径,然后将其传给IndexWriter类构造方法里。
4,Analyzer这个类也是所有分析器的基类,文本文件在索引前,需要经过分析器处理,处理成对应的语汇单元,统一格式,它能提取有效的信息,过滤掉一些禁用词,Lucene自带有几个分析器,但大部分都是对英文或欧洲语言处理的,如果想要使用中文的分词器,可以使用其自带的SmartCN分词器,也可以用开源的IK,messeg4j等等,选择什么样的分析器是索引过程中很重要的一步,这个关键还得看自己的业务需求定。
5,Document代表一个文档的意思,类似于数据库的一行记录,我们可以向文档中,添加自己想要的域字段,然后在把一个个文档索引起来,提供检索。
6,Field就是文档中存储的域,每一个域都有一个域名和域值,这就类似数据库的字段名跟值一样,我们可以使用Field来精确控制各个域的值,最常用的有2个Field,一个是不提供分词的StringField和另外一个分词的TextFiled,当然还有其他的一些Field,在这里就不多介绍了。
7,IndexReader这个类用来获取Directory的子类打开的索引文件流,然后在将进IndexSearcher的构造方法里,进行查询组件的初始化操作,这个类再低版本的的Lucene里也是不存在的,在后来新的版本里才添加的类。
8,IndexSearcher这个类是程序搜索期间的核心类,是连接索引的桥梁,它是以只读的方式打开索引,提供了大量检索,排序,过滤的等等以及其他的一些功能。
9,QueryParser或Query都可以完成一些检索功能,不同的是QueryParser提供的功能更为强大,方便自定义开发一些检索方案,而Query及其麾下的一系列子类是Lucene中自带的一些API,使用这些API,大部分情况下都可以完成一些基本的检索,如果需要定制化自己的检索方案则需要使用QueryParser,大多数情况下,我们最常使用的是Query下面的TermQuery子类,当然还有其他大量的特定功能的Query子类存在。
10,TopDocs这个类是一个简单的容器指针,它一般会记录前N个检索的结果,在TopDocs中,它只会存储这个文档的docid以及获取的得分情况,另外这前N个结果,默认的排序方式,是按照得分的大小排列的。
11,ScoreDoc类通常我们使用的是一个数组,它里面也只会包含这个文档的docid以及获取的得分情况,与TopDocs不同的是,我们可以使用这个类,来进行类似数据库的分页操作,当然你得保证你有足够的内存,如果是海量数据的分页,这个操作很容易造成内存溢出,这时候我们就需要考虑其他方法了。
12,Term类是搜索功能最基本的单元,与Field类似,检索的时候需要传入域名及检索的字符串,是一个小而不可或缺的精简类。
至此,笔者已经对Lucene的基本的常用的几个类简单的剖析了一下,可能大多数情况下,我们知道他们怎么用,但是就是不太了解他们的基本概念。笔者觉得,如果真正的理解了这些东西,就可以在开发中或给同事的一些交流中带来极大的方便。