上一篇文章《社会化海量数据采集框架搭建》提到如何搭建一个社会化采集系统架构,讲架构一般都比较虚,这一篇讲一下如何实战用低成本服务器做到日流水千万级数据的分布式采集系统。
有这样一个采集系统的需求,达成指标: 需要采集30万关键词的数据 、微博必须在一个小时采集到、覆盖四大微博(新浪微博、腾讯微博、网易微博、搜狐微博)。为了节约客户成本,硬件为普通服务器:E5200 双核 2.5G cpu, 4 G DDR3 1333内存,硬盘 500G SATA 7200转硬盘。数据库为mysql。在这样的条件下我们能否实现这个系统目标?当然如果有更好的硬件不是这个文章阐述的内容。现通过采集、存储来说明一下如何实现:
一、采集,目标是在一个小时内把30万关键词对应的数据从四大微博采集下来,能够使用的机器配置就是上面配置的普通服务器。采集服务器对硬盘没有太多要求,属于cpu密集型运算,需耗费一些内存。评估下来硬件资源不是瓶颈,看下获取数据的接口有什么问题?
1、通过各大微博的搜索api。就比如新浪微博API针对一个服务器IP的请求次数,普通权限限制是一个小时1w次,最高权限合作授权一个小时4w次。使用应用时还需要有足够的用户,单用户每个应用每小时访问1000次,最高权限4w次需要40个用户使用你的应用。达到30w关键词,至少需要8个应用,如果每个关键词需要访问3页,总共需要24个合作权限的应用。实际操作我们是不可能为这个项目做到开发24个合作权限的应用,所以这个方式不是很合适。新浪微博API限制参考链接。
2、通过各大微博的最新微博收集数据,微博刚推出的时候,各大微博都有微博广场,可以把最新的微博都收集下来,然后通过分词,如果出现了30万关键词中的一个就留下,其他就丢弃掉。不过现在除了腾讯微博和搜狐微博有微博广场类似的功能,新浪微博和网易微博已经没有这项功能了。另按照新浪微博之前公布的数据,注册用户已经超过5亿,每小时超过1亿条微博,如果全量采集对数据存储是个大的考验,也需要大量的系统资源,实际采集了一亿条,也许就1000w条有用,浪费了9000w条数据的资源。
3、通过各大微博的网页搜索,可见即可抓的方式,结合反监控系统模块模拟人的正常行为操作,搜索30万关键词数据,使资源最大化利用。为了保证在一个小时采集到,需要采用分布式多线程模式抓取,并发采集。并发的时候不能从同一个ip或者同一个ip网段出去,保证对方不会监测到我们的爬虫。
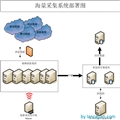
我们最后采用了第三种方式,目前运行状况为通过30w关键词搜索得到的所有微博加在一起总量1000多w条每天,新浪和腾讯最多,新浪微博略胜一筹。使用了6台普通PC服务器,就算一台机器7000元,总共4万元硬件设备解决采集硬件问题。整体部署图为:
class="size-full wp-image-521" style="display: block; margin-left: auto; margin-right: auto;" src="/Upload/Images/2013080616/AE8BC09D874D7A16.png" alt="海量采集系统部署图" width="512" height="502" />
二、存储,采集下来的数据如何处理?首先存储采集数据是个密集写的操作,普通硬盘是否能够支持,mysql数据库软件能否支持,未来量突然增加如何应对?再就是评估存储空间,每天增量这么多需要耗费大量的存储资源,如何存放并且易扩展。


按照这样的架构,我们使用开源免费软件、低成本服务器搭建的千万级数据采集系统在生产运转良好。
原创文章,转载请注明: 转载自LANCEYAN.COM
本文链接地址: 实战低成本服务器搭建千万级数据采集系统