ConcurrentHashMap��Java 5��֧�ָ߲����������������߳���ȫHashMapʵ�֡�����֮ǰ�Ҷ�ConcurrentHashMapֻ��һЩ��dz����������֪���������˶���������Ҳ�㹻�ˡ������ھ���һ�β�ʹ�����Ծ���֮���Ҿ��ñ��������о�����ʵ�֡������б��ʵ����Ƿ�Ҫ��������Ϊ��д�ᷢ����ͻ����˵����Ҫ�������Һ����Թ�Ҳ��˷����˳�ͻ����������֪�������л���˵��ͨ����ϸ�Ķ�Դ���룬������������ConcurrentHashMapʵ�ֻ����ˣ���ʵ��֮���ɣ�����̾�������ҹ���֮��
?
?
ʵ��ԭ��
?
������ (Lock Stripping)
?
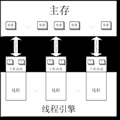
ConcurrentHashMap��������IJ����������У���ؼ�����ʹ���������뼼������ʹ���˶���������ƶ�hash���IJ�ͬ���ֽ��е��ġ�ConcurrentHashMap�ڲ�ʹ�ö�(Segment)����ʾ��Щ��ͬ�IJ��֣�ÿ������ʵ����һ��С��hash table���������Լ�������ֻҪ����IJ��������ڲ�ͬ�Ķ��ϣ����ǾͿ��Բ������С�
?
��Щ������Ҫ��Σ�����size()��containsValue()�����ǿ�����Ҫ����������������������ij���Σ�����Ҫ��˳���������жΣ�������Ϻ��ְ�˳���ͷ����жε����������˳���Ǻ���Ҫ�ģ������п��ܳ�����������ConcurrentHashMap�ڲ�����������final�ģ��������Ա����ʵ����Ҳ��final�ģ����ǣ������ǽ���������Ϊfinal�IJ�����֤�����ԱҲ��final�ģ�����Ҫʵ���ϵı�֤�������ȷ�����������������Ϊ�������˳���ǹ̶��ġ��������Ƕ��̱߳��ռ�к���Ҫ�ĵ�λ�����滹Ҫ̸����
?
Java���� ?
? class="star" alt="�ղش���">
class="star" alt="�ղش���"> spinner" style="display: none;" alt="">
spinner" style="display: none;" alt="">
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
?
?
����(Immutable)���ױ�(Volatile)
?
ConcurrentHashMap��ȫ��������������������У�������������Ҫ���������ʹ�ô�ͳ�ļ�������HashMap�е�ʵ�֣��������������hash�����м����ӻ�ɾ��Ԫ�أ����������������õ���һ�µ����ݡ�ConcurrentHashMapʵ�ּ����DZ�֤HashEntry�����Dz��ɱ�ġ�HashEntry����ÿ��hash���е�һ���ڵ㣬��ṹ������ʾ��
?
Java����?
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
���Կ�������value����final�ģ�����ֵ����final�ģ�����ζ�Ų��ܴ�hash�����м��β�����ӻ�ɾ���ڵ�����Ϊ����Ҫ��next����ֵ�����еĽڵ����ֻ�ܴ�ͷ����ʼ������put����������һ�����ӵ�Hash����ͷ�������Ƕ���remove������������Ҫ���м�ɾ��һ���ڵ㣬�����Ҫ��Ҫɾ���ڵ��ǰ�����нڵ���������һ�飬���һ���ڵ�ָ��Ҫɾ��������һ����㡣���ڽ���caozuo.html" target="_blank">ɾ������ʱ����������Ϊ��ȷ���������ܹ��������µ�ֵ����value���ó�volatile��������˼�����
?
����
?
Ϊ�˼ӿ춨λ���Լ�����hash�۵��ٶȣ�ÿ����hash�۵ĵĸ�������2^n����ʹ��ͨ��λ����Ϳ��Զ�λ�κͶ���hash�۵�λ�á�����������ΪĬ��ֵ16ʱ��Ҳ���Ƕεĸ�����hashֵ�ĸ�4λ�����������ĸ����С���������Ҳ��Ҫ���ǡ��㷨���ۡ������ǵĽ�ѵ��hash�۵ĵĸ�����Ӧ����2^n������ܵ���hash�۷��䲻��������Ҫ��hashֵ������hashһ�Ρ�������ƺ��е������ ��
��
?
��������hash���㷨�����Ƚϸ��ӣ���Ҳ����ȥ�����ˡ�
Java����?
private static int hash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
?
���Ƕ�λ�εķ�����
Java����?
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
?
?
?
���ݽṹ
?
����Hash���Ļ������ݽṹ�����ﲻ���������̽�֡�Hash����һ������Ҫ���������ν��hash��ͻ��ConcurrentHashMap��HashMapʹ����ͬ�ķ�ʽ�����ǽ�hashֵ��ͬ�Ľڵ����һ��hash���С���HashMap��ͬ���ǣ�ConcurrentHashMapʹ�ö����Hash����Ҳ���Ƕ�(Segment)��������ConcurrentHashMap�����ݳ�Ա��
?
Java����?
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
/**
* Mask value for indexing into segments. The upper bits of a
* key's hash code are used to choose the segment.
*/
final int segmentMask;
/**
* Shift value for indexing within segments.
*/
final int segmentShift;
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
}
?
���еij�Ա����final�ģ�����segmentMask��segmentShift��Ҫ��Ϊ�˶�λ�Σ��μ������segmentFor������
?
ÿ��Segment�൱��һ����Hash�����������ݳ�Ա���£�
?
Java����?
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
/**
* The number of elements in this segment's region.
*/
transient volatile int count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
count����ͳ�Ƹö����ݵĸ���������volatile��������Э���ĺͶ�ȡ�������Ա�֤��ȡ�����ܹ���ȡ���������µ��ġ�Э����ʽ�������ģ�ÿ���IJ������˽ṹ�ϵĸı䣬������/ɾ���ڵ�(�Ľڵ��ֵ����ṹ�ϵĸı�)����Ҫдcountֵ��ÿ�ζ�ȡ������ʼ��Ҫ��ȡcount��ֵ����������Java 5�ж�volatile�������ǿ����ͬһ��volatile������д�Ͷ�����happens-before��ϵ��modCountͳ�ƶνṹ�ı�Ĵ�������Ҫ��Ϊ�˼��Զ���ν��б���������ij�����Ƿ����ı䣬�ڽ�����β���ʱ�ỹ��������threashold������ʾ��Ҫ����rehash�Ľ���ֵ��table����洢���нڵ㣬ÿ������Ԫ���Ǹ�hash������HashEntry��ʾ��tableҲ��volatile����ʹ���ܹ���ȡ�����µ�tableֵ������Ҫͬ����loadFactor��ʾ�������ӡ�
?
?
ʵ��ϸ��
?
�IJ���
?
��������ɾ������remove(key)��
Java����?
public V remove(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
�����������ȶ�λ���Σ�Ȼ��ί�и��ε�remove�����������ɾ��������������ʱ��ֻҪ�������ڵĶβ���ͬ�����ǾͿ���ͬʱ���С�������Segment��remove����ʵ�֣�
Java����?
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
?�����������ڳ��ж����������ִ�еģ��հ���֮ǰ������Ҫ�Ƕ�λ��Ҫɾ���Ľڵ�e�����������������������ڵ��ֱ�ӷ���null�������Ҫ��eǰ��Ľ�㸴��һ�飬β���ָ��e����һ����㡣e����Ľ�㲻��Ҫ���ƣ����ǿ������á������Ǹ�ʾ��ͼ����ֱ�Ӵ������վ �ϸ��Ƶģ���������ͼʵ����̫�鷳�ˣ������λ�кõ���ͼ���ߣ������Ƽ�һ�£���
?
?
ɾ��Ԫ��֮ǰ��
?

?
?
ɾ��Ԫ��3֮��

?
�ڶ���ͼ��ʵ�е����⣬���ƵĽ����Ӧ����ֵΪ2�Ľ����ǰ�棬ֵΪ1�Ľ���ں��棬Ҳ���Ǹպú�ԭ�����˳���෴�������ⲻӰ�����ǵ����ۡ�
?
����removeʵ�ֲ������ӣ�������Ҫע�����¼��㡣��һ����Ҫɾ���Ľ�����ʱ��ɾ�������һ������Ҫ��count��ֵ��һ������������һ�������������ȡ�������ܿ�����֮ǰ�Զ������Ľṹ���ġ��ڶ���removeִ�еĿ�ʼ�ͽ�table����һ���ֲ�����tab��������Ϊtable��volatile��������дvolatile�����Ŀ����ܴ�����Ҳ���ܶ�volatile�����Ķ�д���κ��Ż���ֱ�Ӷ�η��ʷ�volatileʵ������û�ж��Ӱ�죬������������Ӧ�Ż���
?
?
��������put������ͬ����put����Ҳ��ί�и��ε�put�����������Ƕε�put������
Java����?
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
�÷���Ҳ���ڳ��ж����������ִ�еģ������ж��Ƿ���Ҫrehash����Ҫ����rehash�����������Ƿ����ͬ��һ��key�Ľ�㣬������ھ�ֱ���滻�������ֵ������һ���µĽ�㲢���ӵ�hash����ͷ������ʱһ��Ҫ��modCount��count��ֵ��ͬ����count��ֵһ��Ҫ�������һ����put����������rehash������reash����ʵ�ֵ�Ҳ�ܾ��ɣ���Ҫ������table�Ĵ�СΪ2^n������Ͳ������ˡ�
?
�IJ�������putAll��replace��putAll���Ƕ�ε���put������ûʲô��˵�ġ�replace�����������ṹ�ϵĸ��ģ�ʵ��Ҫ��put��deleteҪ�ö࣬������put��delete������replace�Ͳ��ڻ����ˣ�����Ҳ�������ˡ�
?
?
��ȡ����
?
���ȿ���get������ͬ��ConcurrentHashMap��get������ֱ��ί�и�Segment��get������ֱ�ӿ�Segment��get������
?
Java����?
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
?
get��������Ҫ������һ���Ƿ���count����������һ��volatile�������������е��IJ����ڽ��нṹ��ʱ���������һ��дcount������ͨ�����ֻ��Ʊ�֤get�����ܹ��õ��������µĽṹ���¡����ڷǽṹ���£�Ҳ���ǽ��ֵ�ĸı䣬����HashEntry��value������volatile�ģ�Ҳ�ܱ�֤��ȡ�����µ�ֵ�����������Ƕ�hash�����б����ҵ�Ҫ��ȡ�Ľ�㣬���û���ҵ���ֱ�ӷû�null����hash�����б�������Ҫ������ԭ��������ָ��next��final�ġ�����ͷָ��ȴ����final�ģ�����ͨ��getFirst(hash)�������أ�Ҳ���Ǵ���table�����е�ֵ����ʹ��getFirst(hash)���ܷ��ع�ʱ��ͷ��㣬���磬��ִ��get����ʱ����ִ����getFirst(hash)֮����һ���߳�ִ����ɾ������������ͷ��㣬��͵���get�����з��ص�ͷ��㲻�����µġ����ǿ���������ͨ����count������Э�����ƣ�get�ܶ�ȡ���������µ����ݣ���Ȼ���ܲ������µġ�Ҫ�õ����µ����ݣ�ֻ�в�����ȫ��ͬ����
?
�������ҵ�������Ľ�㣬�ж�����ֵ����ǿվ�ֱ�ӷ��أ�������������״̬���ٶ�һ�Ρ����ƺ���Щ�ѽ⣬�����Ͻ���ֵ������Ϊ�գ�������Ϊput��ʱ��ͽ������жϣ����Ϊ�վ�Ҫ��NullPointerException����ֵ��ΨһԴͷ����HashEntry�е�Ĭ��ֵ����ΪHashEntry�е�value����final�ģ���ͬ����ȡ�п��ܶ�ȡ����ֵ����ϸ����put��������䣺tab[index] = new HashEntry<K,V>(key, hash, first, value)������������У�HashEntry���캯���ж�value�ĸ�ֵ�Լ���tab[index]�ĸ�ֵ���ܱ�����������Ϳ��ܵ��½���ֵΪ�ա��������Ӧ���ܺ�����һ���������������ConcurrentHashMap��ȡ�ķ�ʽ���ڳ�������������ٶ�һ�飬���ܹ���֤�������µ�ֵ������һ������Ϊ��ֵ��
?
Java����?
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
?
?
��һ��������containsKey�����ʵ�־�Ҫ�ö��ˣ���Ϊ������Ҫ��ȡֵ��
Java����?
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
return true;
e = e.next;
}
}
return false;
}
?
?
����
?
��Щ������Ҫ�漰������Σ�����˵size(), containsValaue()����������size()������
?
Java����?
public int size() {
final Segment<K,V>[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count;
if (mc[i] != segments[i].modCount) {
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
}
?
size������Ҫ˼·������û����������¶����жδ�С��ͣ�������ܳɹ���������Ϊ���������п����������߳����ڶ��Ѿ��������Ķν��нṹ�Ը��£������ִ��RETRIES_BEFORE_LOCK�Σ���������ɹ����ڳ������ж�����������ٶ����жδ�С��͡���û�������������Ҫ������Segment�е�modCount���м�⣬�ڱ��������б���ÿ��Segment��modCount���������֮���ټ��ÿ��Segment��modCount��û�иı䣬����иı��ʾ�������߳����ڶ�Segment���нṹ�Բ������£���Ҫ���¼��㡣
?
?
��ʵ���ַ�ʽ�Ǵ�������ģ��ڵ�һ���ڲ�forѭ���У������������sum += segments[i].count; mcsum += mc[i] = segments[i].modCount;֮�䣬�����߳̿������ڶ�Segment���нṹ�Ե��ģ�����segments[i].count��segments[i].modCount��ȡ�����ݲ���һ�¡������ʹsize()���������κ�ʱ�������ڵĴ�С�������javadoc��Ȼû����ȷ�����һ�㣬��������Ϊ���ʱ�䴰��̫С�˰ɡ�size()��ʵ�ֻ���һ����Ҫע�⣬����Ҫ��segments[i].count������segments[i].modCount��������Ϊsegment[i].count�Ƕ�volatile�����ķ��ʣ�������segments[i].modCount���ܵõ��������µ�ֵ��ǰ�����Ѿ�˵��Ϊʲôֻ�ǡ��������ˣ��������containsValue�����еõ������쾡�µ�չ�֣�
?
?
Java����?
public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
// See explanation of modCount use above
final Segment<K,V>[] segments = this.segments;
int[] mc = new int[segments.length];
// Try a few times without locking
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
int sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
int c = segments[i].count;
mcsum += mc[i] = segments[i].modCount;
if (segments[i].containsValue(value))
return true;
}
boolean cleanSweep = true;
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
int c = segments[i].count;
if (mc[i] != segments[i].modCount) {
cleanSweep = false;
break;
}
}
}
if (cleanSweep)
return false;
}
// Resort to locking all segments
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
boolean found = false;
try {
for (int i = 0; i < segments.length; ++i) {
if (segments[i].containsValue(value)) {
found = true;
break;
}
}
} finally {
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
return found;
}
?
ͬ��ע���ڲ�ĵ�һ��forѭ�������������int c = segments[i].count; ����cȴ����û�б�ʹ�ù�����ʹ��ˣ�������Ҳ�������Ż����������ȥ������Ϊ���ڶ�volatile����count�Ķ�ȡ�����������ڵ�ΨһĿ�ľ��DZ�֤segments[i].modCount��ȡ���������µ�ֵ������containsValue�������������־Ͳ������ˣ�����size������ࡣ
?
?
��η����л���һ��isEmpty()��������ʵ�ֱ�size()������Ҫ��Ҳ�������ˡ����ؽ����µ�����������keySet(), values(), entrySet()��������Щ������������Ӧ�ĵ����������е��������̳���Hash_Iterator��(�ύʱ��Ȼ�����Ҳ��ܰ���sh It��ֻ�ü����»���)����ʵ������Ҫ�ķ�������ṹ�ǣ�
?
Java����?
abstract class Hash_Iterator{
int nextSegmentIndex;
int nextTableIndex;
HashEntry<K,V>[] currentTable;
HashEntry<K, V> nextEntry;
HashEntry<K, V> lastReturned;
}
?
?nextSegmentIndex�Ƕε�������nextTableIndex��nextSegmentIndex��Ӧ������hash����������currentTable��nextSegmentIndex��Ӧ�ε�table������next����ʱ��Ҫ�ǵ�����advance������
?
?
Java����?
final void advance() {
if (nextEntry != null && (nextEntry = nextEntry.next) != null)
return;
while (nextTableIndex >= 0) {
if ( (nextEntry = currentTable[nextTableIndex--]) != null)
return;
}
while (nextSegmentIndex >= 0) {
Segment<K,V> seg = segments[nextSegmentIndex--];
if (seg.count != 0) {
currentTable = seg.table;
for (int j = currentTable.length - 1; j >= 0; --j) {
if ( (nextEntry = currentTable[j]) != null) {
nextTableIndex = j - 1;
return;
}
}
}
}
}
�����ٶ�����ˣ�Ψһ��Ҫע�����������һ����ʱ��һ��Ҫ�ȶ�ȡ��һ���ε�count������?
?
���ֵ�����ʽ����ҪЧ���Dz����׳�ConcurrentModificationException��һ����ȡ����һ���ε�table��Ҳ����ζ������ε�ͷ����ڵ��������о�ȷ���ˣ��ڵ��������оͲ��ܷ�ӳ������νڵ㲢����ɾ�������ӣ����ڽڵ�ĸ������ܹ���ӳ�ģ���Ϊ�ڵ��ֵ��һ��volatile������
?
������
?
ConcurrentHashMap��һ��֧�ָ߲����ĸ����ܵ�HashMapʵ�֣���֧����ȫ�����Ķ��Լ�һ���̶Ȳ�����д��ConcurrentHashMap��ʵ��Ҳ�Ǻܾ��ɣ�������������µ�JMM�淶��ֵ��ѧϰ��ȴ��ֵ��ģ�¡�������ڱ���ˮƽ���ޣ��Դ�ʦ����Ʒ�����������������ڣ�������ţ�Dz���ָ����
?
?
?
?
�ο����£�
http://www.ibm.com/developerworks/java/library/j-jtp08223/����������۵���Doug Lea's util.concurrent���е�ConcurrentHashMap��ʵ�֣���������˼����һ�µġ�