 original="http://ittopic.gotoip1.com/qee/wordpress/wp-content/uploads/2013/08/437060703.jpg" />
original="http://ittopic.gotoip1.com/qee/wordpress/wp-content/uploads/2013/08/437060703.jpg" />
英文原文:Programming Languages vs. Fat Fingers
水星探索项目中一段 Fortran 代码里的逗号被写成了点号,影响了运算的准确性,导致太空探测器无法到达更远的轨道。出现这种事情的几率有多大?一种编程语言的设计在多大程度上会影响程序正确性和导致相似的事件?最近发表在第四届 International Workshop on Evaluation and Usability of Programming Languages and Tools 上的一篇论文中,我展示了一些研究发现:通过往由各种不同语言编写的类似程序中随机的制造一些干扰信息,看编译器或运行系统能否发现由这些干扰引起的错误,或者最终导致了程序输出了错误的结果。
在由我和我的同事 Vassilios Karakoidas、Panagiotis Louridas 共同指导的这项研究中,我们首先选择了 10 中流行的编程语言,以及用它们写出的一批程序。我们选择这些语言的条件是基于一篇 IEEE Spectrum 文章里提供的数据(由软件研究公司 TIOBE 建立的一个索引目录)、出现在 Powell’s Books 书名中的数量、IRC 在线讨论中引用的数量,以及 Craigslist 中招聘职位的数量。在这样一个流行语言的大集合中,由于一些可操作性的原因,部分语言被排除在外。根据流行度索引,这个集合大概能覆盖所有语言的 71% 到 86%。
然后我们从 Rosetta Code wiki 中寻找我们研究的这 10 种语言写成的执行相同任务的各种源代码。用 Rosetta Code 这个网站的创办人自己的话,这个网站的目的就是搜集用不用的各种语言来完成同一种任务的代码,展示它们的相似和不同,帮助那些研究基础工作的人了解问题的另一种解决方案。
我们的下一步是要制造一个代码干扰器:一个能系统的往代码里随机引入各种随机混乱的工具。干扰器能替换标志符,把一些数字加一,随机改变字符或把字符串替换成相似的东西或随机的串。最后,我们把干扰器应用到我们搜集的代码里,检查这些被修改后有错误的代码是否能被编译器或运行环境检测到,或是否导致了错误的输出。
理论上,我们人工引入的这些错误是模拟现实生活中的很多具体表现。错误拼写——“胖手指”——就是一个很常见的例子。另外的场景包括马虎大意,自动重构错误(特别是在像C和 C++ 这些语言里,自动重构是很难正确无误的实现的),复杂的编辑器命令导致的意外失误,或搜索-替换操作造成的错误,甚至还包括猫踩着键盘上产生的后果。
总计我们一共测试了 136 个任务实现,尝试了 2 万 8 千种干扰操作,其中成功的有 261,667 (93%)个。被干扰的程序中有 90,166 (32%)个编译通过或语法上没有发现异常。60,126 (67%, 或总共被干扰的数量的 23%)个能正常的结束运行。 18,256 个输出了完全无异的结果,表明干扰没有对程序产生任何影响。其余的,41,870 个程序 (能运行的 70%, 总数的 16%)编译和运行都没有问题,但输出了结果错误。
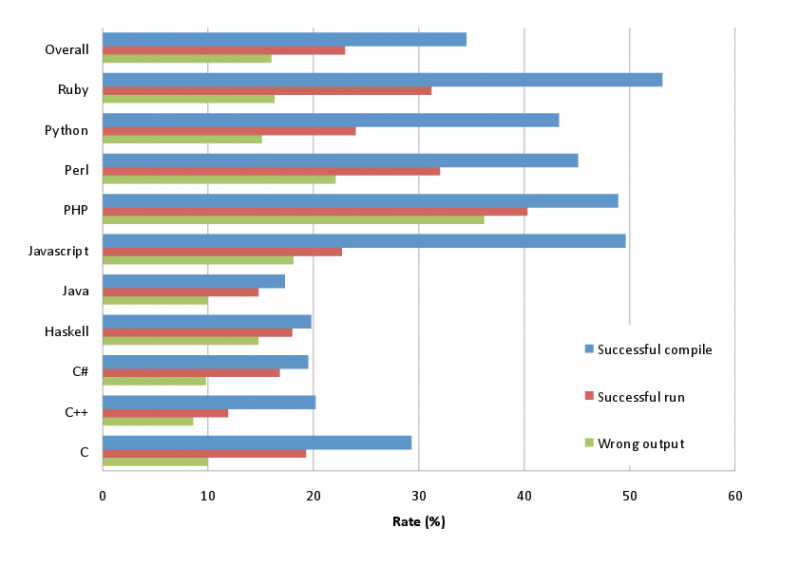
上图显示了对各种语言的统计结果,是按失败情况统计:成功的编译或执行,没有捕获程序中的错误,导致输出了错误的结果。上图验证了我们一些非常直觉的看法。强静态类型语言(Java, Haskell, C++)比那些弱的或动态类型语言(Ruby, Python, Perl, PHP, 和 JavaScript)能在编译器捕获更多的错误。稍微有点意外的是,C语言出现在了中间位置,验证了一个被很多人相信的观点:C语言的类型系统并不像它的众多追随者(包括我)认为的那样强。然而,C语言在运行期却抛出了大量的错误,导致最终它的不正确输出结果的比率跟那些强类型语言的相似。
这还有一副类似的统计图,统计的是运行时各种语言的表现。同样,相比起强类型语言,弱类型语言更倾向于仍能无异常(崩溃或抛出异常)的运行。根据这两个统计表可以看出,弱类型语言在输出结果上将会有更高的错误率。相比起 C++ 或C#,PHP 的错误率是 36%,而 C++ 的是8%,C#是 10%,用像 PHP 这样语法上不是很严格的语言写成的应用,虽然充分利用了这些弱类型语言带来的方便性,但不经意的拼写错误也会很容易溜进产品代码里。总的看来,动态脚本语言跟强静态类型语言比起来差距很大。这可能是我们只在较高层面测试这些脚本语言特征有关。
我们对这些数据做了进一步分析,发现了下面一些事情。
然而,我想我们的研究最重要的成果是,通过对具有可比性的语言进行干扰测试,提供了对编程语言的设计进行评价的数据资料。





