class="topic_img" alt=""/>
class="topic_img" alt=""/>
groupcache 是使用 Go 语言编写的缓存及缓存过滤库,作为 memcached 许多场景下的替代版本。相关的 API 文档和实例请猛戳 package groupcache。
对比原始 memcached
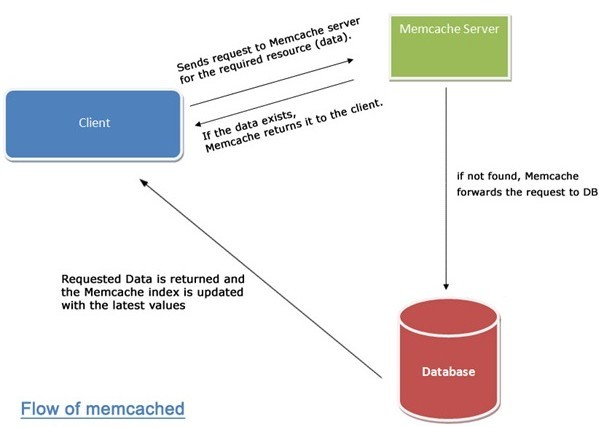
首先,groupcache 与 memcached 的相似之处:通过 key 分片,并且通过 key 来查询响应的 peer。
其次,groupcache 与 memcached 的不同之处:
1. 不需要对服务器进行单独的设置,这将大幅度减少部署和配置的工作量。groupcache 既是客户端库也是服务器库,并连接到自己的 peer 上。
2. 具有缓存过滤机制。众所周知,在 memcached 出现“Sorry,cache miss(缓存丢失)”时,经常会因为不受控制用户数量的请求而导致数据库(或者其它组件)产生“惊群效应(thundering herd)”;groupcache 会协调缓存填充,只会将重复调用中的一个放于缓存,而处理结果将发送给所有相同的调用者。
3. 不支持多个版本的值。如果“foo”键对应的值是“bar”,那么键“foo”的值永远都是“bar”。这里既没有缓存的有效期,也没有明确的缓存回收机制,因此同样也没有 CAS 或者 Increment/Decrement。
4. 基于上一点的改变,groupcache 就具备了自动备份“超热”项进行多重处理,这就避免了 memcached 中对某些键值过量访问而造成所在机器 CPU 或者 NIC 过载。
5. 当下只支持 Go
运行机制
简而言之,groupcache 查找一个 Get(“foo”)的过程类似下面的情景(机器#5 上,它是运行相同代码N台机器集中的一台):
1. key“foo”的值是否会因为“过热”而储存在本地内存,如果是,就直接使用
2. key“foo”的值是否会因为 peer #5 是其拥有者而储存在本地内存,如果是,就直接使用
3. 首先确定 key “fool”是否归属自己N个机器集合的 peer 中,如果是,就直接加载。如果有其它的调用者介入(通过相同的进程或者是 peer 的 RPC 请求,这些请求将会被阻塞,而处理结束后,他们将直接获得相同的结果)。如果不是,将 key 的所有者 RPC 到相应的 peer。如果 RPC 失败,那么直接在本地加载(仍然通过备份来应对负载)。
采用情况
groupcache 已经在 dl.Google.com、Blogger、Google Code、Google Fiber、Google 生产监视系统等项目中投入使用。
更多展示:Presentations