首先,让我们来简单了解一下什么是“栈”(stack),什么是“堆”(heap)。“栈”其实就是一种后入先出(LIFO)的数据结构。在我们.NET Framework里面,由CLR负责管理,我们程序员不用去担心垃圾回收的问题;每一个线程都有自己的专属的“栈”。“堆”的存放就要零散一些,并且由 Garbage Collector(GC)执行管理,我们关注的垃圾回收部分,就是在“堆”上的垃圾回收;其次就是整个进程共用一个“堆”。

我们先来记住两条黄金法则:
1.引用类型总是被分配到“堆”上。
2.值类型总是分配到它声明的地方:
a.作为引用类型的成员变量分配到“堆”上
b.作为方法的局部变量时分配到“栈”上
要真正理解上面的两条黄金法则,还需要了解一下,“栈”和“堆”是如何工作的。首先以下面的这个方法为例:
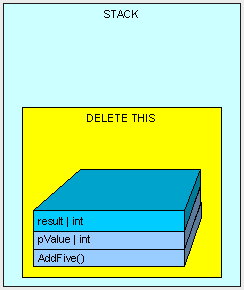
public int AddFive(int pValue) { int result; result = pValue + 5; return result; }
1.方法AddFive()被压入“栈”
2.紧接着方法参数pValue被压入“栈”
3.然后是需要为result变量分配空间,这时被分配到“栈”上。
4.最后返回结果
通过将栈指针指向 AddFive()方法曾使用的可用的内存地址,所有在“栈”上的该方法所使用内存都被清空,且程序将自动回到“栈“上最初的方法调用的位置。
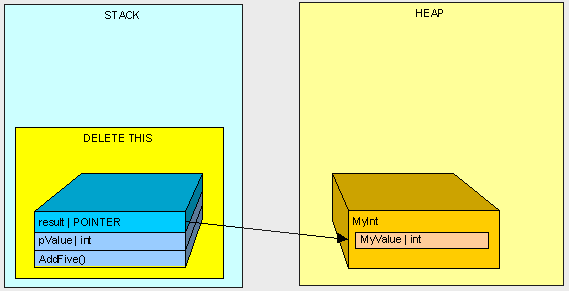
下面我们来看看,值类型的变量分配到“堆”上到情况。
public class MyInt { public int MyValue; } public MyInt AddFive(int pValue) { var result = new MyInt(); result.MyValue = pValue + 5; return result; }
和前面一样,线程开始执行函数,函数参数被压入线程堆栈。
由于 MyInt 为引用类型,它被分配在“堆”上,并且由一个位于“栈”上的指针引用。
AddFive()函数执行完毕后,“栈”同样会被清空。
最后,只剩下一个 MyInt 类被留在“堆”上(“栈”上再也没有指向这个 MyInt 类的指针)!这个时候就需要GC机制来处理了。
好了,大家对“栈”和“堆”有一定的了解之后,下面让我们来稍微深入一点,来看两个例子。
public int ReturnValue() { int x = 3; int y = x; y = 4; return x; }
返回值大家其实已经知道了吧,还是3。这是为什么呢?这是因为,值类型,使用的就是值本身,其实在做int y = x的时候,就把3做了一份“拷贝”赋值给了y,然后在y = 4的时候,操作的是这个“拷贝”,并不会操作原来的3。
接下来我们看另外一个例子,MyInt还是使用上面例子中使用过的MyInt类。
public int ReturnValue() { var x = new MyInt(); x.MyValue = 3; MyInt y; y = x; y.MyValue = 4; return x.MyValue; }
在这个代码中,x.MyValue是否还是会是3呢?是否y.MyValue还是操作的3的“拷贝”呢?其实只要运行一下这个代码,就可以得出结果,x.MyValue还是被修改成了4。这是因为,当我们使用引用类型时,我们实际上是在使用指向这些对象的地址,而不是直接使用这些对象本身。

好了,暂时就介绍到这里,如果有什么疑问,或者有误的地方,欢迎大家指点和交流。
![[激励机制]浅谈内部竞争——如何让你的员工玩命干活?](/Upload/SmallIMG/2013072309/CE5768B3B1192C5C.png)