?????? 首先谈谈我对压缩这个词的理解吧。在我看来,压缩=代码+协议。而这二者中,我认为协议比代码更重要,协议是整个压缩的灵魂。就拿哈夫曼压缩法来说,它的协议简单来说就是为待压缩文件中出现过的每个字符设置一个编码,头文件中存储了每个编码对应的字符信息。显然,哈夫曼压缩中的头文件就是我们定下的压缩协议。(今天主要谈LZW压缩法,因此哈夫曼压缩的具体原理就不做过多的说明了。)
??????? 谈到LZW字典压缩,好多同学觉得好高深,这就错了。举个简单的例子,读一篇英语文章,或者一篇英语巨著,里边有好多的单词和句子是重复的,如果我们用一个特定的符号来代替整个单词或句子,那么,节省的空间是相当可观的。
??????? 这就是字典压缩的最初构想。
??????? 想法有了,现在要做的就是定一个协议。这个协议要达到的目标很简单:1)能压缩文件。2)能把压缩文件翻译成原文件。至于压缩效果,那是后期工作。
??????? 先考虑编码问题,0~255是肯定不能用的,于是选取了256~65535,再大了会使编码的长度加倍而字典也不需要那么大。然后要思考怎样使文件中的符号跟编码一一对应,而且字典压缩是没有头文件的,这意味着压缩后的文件可以自己生成字典进行解压。
???????? ?在看压缩的过程之前先了解几个名词。前缀:对于每一个词,都拆分成两部分,前边的一个完整的个体(单独的一个字符或者已经写进字典的一个词的编码)叫做前缀,相应的“后缀”就很明了了。
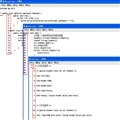
????????? OK,现在让我们一起来了解一下创建字典的算法(以压缩字符串“ababbacb”为例):
??????? 协议定好了,现在开始代码实现。
??????? 节点类很简单,其功能是定义两个属性:前缀(first),后缀(end)
class="java" name="code">public class Node {
int frist ;
int end;
public Node(){}
public Node(int frist,int end){
this.frist = frist;
this.end = end;
}
}
??????????? 然后是字典类,先创建一个链表:
public class Dictionary {
public List<Node> list = new ArrayList<Node>();
}
?????????? 将链表的0~255的节点按ASCII初始化:
public Dictionary(){
for(int i=0;i<256;i++){
Node node = new Node();
node.frist = i;
this.list.add(node);
}
}
???????? 向链表中添加节点:
public void add(int frist,int end){
Node node = new Node(frist, end);
list.add(node);
}
????????? 获取给定数据的结点的索引,若字典中存在,则返回索引,若不存在返回-2:
public int getIndex(int frist,int end){
for(int i=0;i<list.size();i++){
Node node = list.get(i);
if(node.frist==frist && node.end==end){
return i;
}
}
return -2;
}
????????? 字典设置完成了,开始实现压缩。
????????????????1.根据地址创建输入输出流。path:要压缩的文件的地址;newpath:? 压缩后文件存放的地址
??????????????? 2.循环进行压缩,直到文件末尾
??????????????????? 1)如果字典中存在
????????????????? ? 2)如果字典中不存在
?????????????????? ?3)后续处理工作
?????????????????? ?4)如果字典满了,字典清空,做标记,创建新的字典
?????????????????? ?5)到了文件结尾,做标记,翻译
?????????????????? ?6)异常处理
Dictionary dic;
public void compressFile(String path, String newpath) {
dic = new Dictionary();
try {
File file = new File(path);
DataInputStream dis = new DataInputStream(new FileInputStream(file));
File newfile = new File(newpath);
DataOutputStream newdos = new DataOutputStream(new FileOutputStream(newfile));
int frist = dis.read();
while (dis.available() > 0) {
int end = dis.read();
int index = dic.getIndex(frist, end);
//如果链表里边存在
if (index != -2) {
frist = index;
}
// 如果表里不存在该词组
else {
newdos.writeChar(frist);
dic.add(frist, end);
frist = end;
if (dic.list.size() >= 65534) {
newdos.writeChar(65535);
dic = new Dictionary();
}
}
}
// 将剩余的输出
newdos.writeChar(frist);
//System.out.println(frist);
/****** 把后续工作做完 ******/
newdos.writeChar(65535);
System.out.println("文件压缩完毕!!!");
dis.close();
newdos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
????????
???????? 因为压缩文件中是不存储字典的,所以解压时要根据压缩文件和已经翻译好的部分重新创建字典。
??????? ?解压=创建字典+翻译+创建字典+翻译+……?
??????
???????? 具体代码实现如下:
??????? 从字典中查询出字符串的方法(C为查询的字符串在字典中的位置,bufStr 用来存储字典中C位置上存储的字符串):
String bufStr = "";
private void getString(int c) {
if (c > 255) {
getString(dic.list.get(c).frist);
getString(dic.list.get(c).end);
} else {
bufStr += (char) c;
}
}
??????? 准备工作完成,开始解压。。。
??????? ?1.判断,如果是0~255直接翻译
?????????2.如果是前边创建的字典的内容, 按字典翻译
?????????3.若不在字典中,则该词很奇葩,它一定与其前缀加前缀的第一个字符相等
?????????个人认为第三点是解压的精华:String str = bufStr + bufStr.charAt(0);
public void releaseFile(String path, String newpath) {
try {
File file = new File(path);
DataInputStream dis = new DataInputStream(new FileInputStream(file));
File newfile = new File(newpath);
DataOutputStream newdos = new DataOutputStream(new FileOutputStream(newfile));
int frist;
int end;
dic = new Dictionary();
frist = dis.readChar();
newdos.write(frist);
while (frist != 65535) {
end = dis.readChar();
if (end == 65535) {
break;
}
if (end <= 255) {
newdos.write(end);
dic.add(frist,end);
frist = end;
} else {
if (end<dic.list.size()) {
getString(end);
newdos.write(bufStr.getBytes());
dic.add(frist,(int)bufStr.charAt(0));
bufStr = "";
frist = end;
}
else {
getString(frist);
String str = bufStr + bufStr.charAt(0);
newdos.write(str.getBytes());
dic.add(frist, (int)bufStr.charAt(0));
frist = dic.getIndex(frist, bufStr.charAt(0));
bufStr = "";
}
}
}
System.out.println("文件解压完毕");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
???? OK,解压到这里就基本完成了。
?????
????? 这里只是提供了压缩的简单思路,许多细节还未注意到(现在只能压缩英语,中文的还不能压缩成功)。
????? 为了提高压缩效率,我们可以优化压缩协议,比如说当字典满时,可以选择删除重复使用效率不高的词,复用率自己制定,这样压缩效果会更好,大家一起动手试试吧。
?